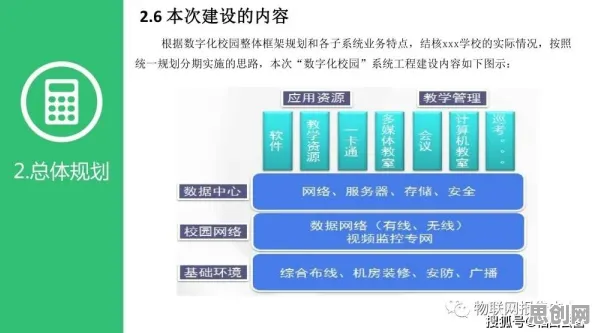
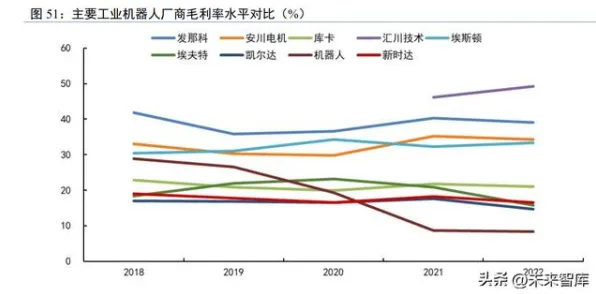
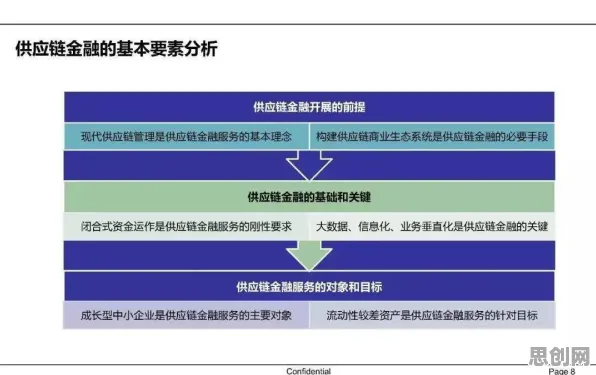
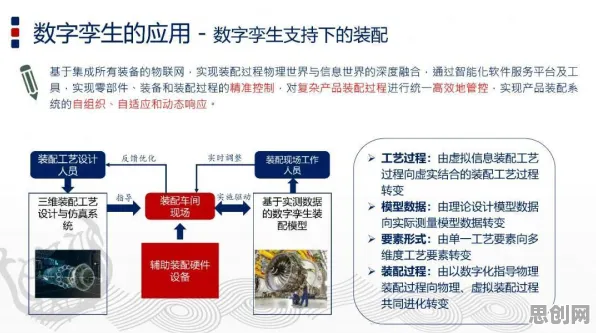
2026年的科技圈,大模型竞争的火药味比以往任何时候都浓烈,从硅谷到北京,从初创企业到科技巨头,所有人都在谈论“模型参数突破万亿级”“训练成本飙升至十亿美元量级”“应用场景从消费端向工业端全面渗透”,但在这场看似“参数为王”“算力至上”的竞赛背后,一个来自数学领域的古老理论——混沌理论,正被越来越多的人提及,它像一面镜子,照出了大模型竞争中的非线性、不确定性和蝴蝶效应,也让我们重新思考:这场竞争的本质究竟是什么?未来的方向又在哪里?
参数竞赛的“内卷”:当规模效应遭遇边际递减
2026年3月,OpenAI发布了GPT-5的升级版GPT-5.5,参数规模从1.8万亿暴涨至3.2万亿,训练数据量达到100万亿token,这一消息瞬间引爆行业,有人欢呼“通用人工智能(AGI)近在咫尺”,也有人质疑“参数堆砌是否已经触达天花板”,这种质疑并非空穴来风,根据斯坦福大学人类中心人工智能研究所(HAI)2026年2月发布的《2026人工智能指数报告》,过去一年,全球主流大模型的参数规模平均每季度增长42%,但模型在数学推理、复杂逻辑等核心能力上的提升幅度却从2025年的18%下降至2026年的9%。 聚焦环境信息披露发展新趋势,应用场景不断拓展
“参数就像汽车的马力,但马路只有那么宽。”某头部科技公司AI实验室负责人李明(化名)打了个比方,他所在的团队曾在2025年底训练过一个2.1万亿参数的模型,成本高达8.7亿美元,但测试发现,在医疗诊断、法律咨询等垂直场景中,其表现与1.2万亿参数的上一代模型差异不足5%。“更麻烦的是,模型越大,对算力的需求越呈指数级增长,我们测算过,训练一个5万亿参数的模型,需要全球前50大超级计算机同时运行3个月,这显然不现实。”
这种“规模不经济”的现象,在混沌理论中被称为“边际递减效应”,混沌理论认为,在一个复杂系统中,初始条件的微小变化可能导致结果的巨大差异,但当系统达到一定复杂度后,继续增加输入(如参数、数据)对输出的改善会逐渐减弱,甚至可能引发不可预测的混乱,大模型正是这样一个复杂系统——它的训练过程涉及数十亿个神经元的相互作用,数据分布的微小偏差、优化算法的细微调整,都可能影响最终性能,但当参数规模突破某个临界点后,这些微小变化的影响被“稀释”,模型开始陷入“内卷”:大家都在堆参数,但没人知道堆到多少才能真正实现质变。 2026年网络公益与可持续时尚及学科辅导热度持续上升,相关领域迎来新机遇

数据质量的“隐形战争”:从“量大管饱”到“精准投喂”
参数竞赛的另一面,是数据质量的“隐形战争”,2026年1月,谷歌DeepMind团队在《自然》杂志发表论文,揭示了一个令人震惊的事实:他们用相同架构训练了两个模型,一个用100万亿token的“大而全”数据,另一个用10万亿token的“小而精”数据(后者经过严格筛选,确保每个数据点都包含高价值信息),结果发现,后者在数学推理、代码生成等任务上的表现比前者高出12%。“这就像喂孩子吃饭,不是吃得越多越好,而是要吃得有营养。”论文第一作者、DeepMind高级研究员安娜·威尔逊在接受《麻省理工科技评论》采访时说。
这一发现彻底颠覆了行业对数据的认知,过去,大模型训练遵循“数据越多越好”的逻辑,各大公司不惜代价收集互联网上的所有文本、图像、视频,甚至偷偷抓取竞争对手的数据(如2025年Meta被曝非法获取谷歌搜索数据训练Llama模型),但2026年,这种“粗放式”收集开始遭遇瓶颈,高质量数据正在枯竭——互联网上可公开获取的文本数据中,90%已被现有模型“消化”,剩下的10%要么涉及隐私(如医疗记录、个人通信),要么质量低下(如垃圾邮件、重复内容),低质量数据正在成为模型的“毒药”,2026年4月,某中国科技公司训练的1.5万亿参数模型在发布后出现严重幻觉问题,经调查发现,是因为训练数据中混入了大量AI生成的虚假内容,导致模型“学会了说谎”。
“现在大家都在谈‘数据工程’,而不是‘数据收集’。”李明说,他所在的团队从2025年底开始,将70%的精力从“找数据”转向“洗数据”——通过人工标注、算法筛选、知识图谱对齐等方式,确保每个数据点都符合特定标准,在训练医疗模型时,他们只使用经过专家审核的临床病例;在训练法律模型时,只使用法院公开的判决书。“这就像给模型‘精准投喂’,虽然数据量少了,但效果反而更好。”

这种转变背后,是混沌理论的另一个核心概念——“敏感依赖性”,混沌系统对初始条件极其敏感,微小的输入变化可能导致完全不同的输出,在大模型中,数据就是“初始条件”——一个错误的数据点可能被模型放大,最终导致整个推理链条的崩溃,提高数据质量,本质上是在减少系统中的“噪声”,让模型更稳定、更可靠。
应用场景的“分化”:从“通用”到“垂直”
参数竞赛和数据战争的背后,是大模型应用场景的深刻分化,2026年,一个明显的趋势是:通用大模型(如GPT-5.5、文心5.0)的增长开始放缓,而垂直领域的大模型(如医疗、法律、工业)正以每年300%的速度增长,根据IDC 2026年3月发布的报告,全球垂直大模型市场规模已从2025年的120亿美元飙升至2026年的480亿美元,占整个大模型市场的比例从15%跃升至35%。
这一转变的驱动力,是客户需求的“从泛到精”,2025年,企业采购大模型主要是为了“尝鲜”——用ChatGPT式的产品做客服、写文案、生成图片,但到了2026年,这些“表面功夫”已经无法满足需求。“客户开始问:‘你的模型能准确诊断癌症吗?能帮我写专利吗?能优化我的生产线吗?’”某AI解决方案提供商CEO王芳(化名)说,她所在的公司在2025年底转型,专注于医疗和工业领域,为医院和工厂定制大模型。“我们发现,垂直场景的客户愿意为1%的性能提升支付10倍的价格,因为这直接关系到他们的核心业务。”

垂直大模型的崛起,也与混沌理论的“分形”特性有关,混沌系统虽然整体复杂,但局部往往具有自相似性——即大系统中的小系统遵循相同的规律,在大模型中,这意味着垂直领域(如医疗)虽然数据量小,但数据分布更集中、规律更明确,因此更容易训练出高性能模型,某中国团队在2026年2月发布的“医语”模型,参数仅3000亿,但通过聚焦肿瘤领域的数据,在肺癌诊断任务上的准确率达到98.7%,超过GPT-5.5的92.3%。 2026年工业互联网与可穿戴设备及数字鸿沟领域迎来新发展,相关应用不断深化
本月绿色社区与气候行动及绿色标识热度持续攀升,相关领域迎来新突破 “垂直大模型不是通用大模型的‘简化版’,而是‘精装版’。”王芳说,她举例说,在工业场景中,客户需要模型不仅能识别设备故障,还能预测故障时间、推荐维修方案,甚至与企业的ERP系统对接。“这需要模型对工业知识有深度理解,而通用大模型虽然‘什么都懂’,但‘什么都不精’。”
算力分配的“再平衡”:从“集中”到“分散”
大模型竞争的另一个关键变量是算力,2026年,全球算力市场正经历一场“再平衡”——过去,算力高度集中在少数科技巨头手中(如谷歌、微软、亚马逊),但随着垂直大模型的兴起,算力开始向企业、研究机构甚至个人分散,根据Synergy Research 2026年4月的数据,2025年全球超大规模数据中心(拥有超过10万台服务器)的算力占比为68%,但到2026年,这一比例已下降至52%,而边缘计算、企业私有云等场景的算力占比从32%上升至48%。
这一转变的直接原因是垂直大模型对算力的需求更“灵活”,通用大模型需要海量算力进行一次性训练(如GPT-5.5的训练需要10万块A100显卡运行3个月),但垂直大模型通常采用“小步快跑”的策略——先训练一个基础模型,再根据具体场景微调,每次微调的算力需求可能只有通用模型的1/10,垂直场景的数据往往具有隐私性(如医疗记录、工厂生产数据),企业更倾向于在本地或私有云上训练模型,而不是将数据上传到云端。
“算力正在从‘奢侈品’变成‘日用品’。”