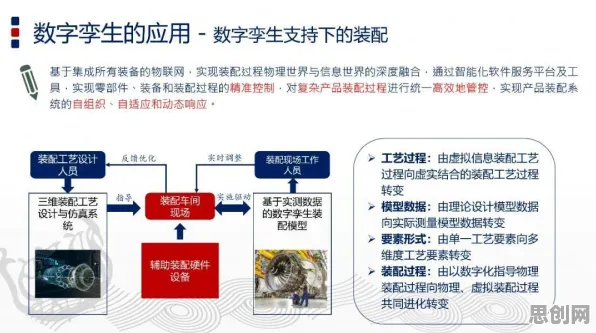
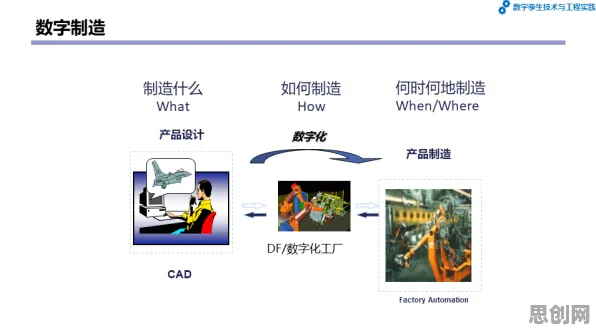
从“概念验证”到“规模落地”:数据挖掘是数字孪生的“催化剂”
数字孪生的核心在于通过虚拟模型映射物理实体,实现全生命周期的实时监控与优化,但要让虚拟模型“活”起来,仅靠传感器采集的原始数据远远不够——数据需要被清洗、标注、分析,才能转化为有价值的洞察,这正是数据挖掘的用武之地。
以德国西门子安贝格电子制造工厂为例,这座被誉为“全球最智能的工厂”在2026年已实现全流程数字孪生覆盖,但最初,西门子团队发现,尽管工厂部署了数千个传感器,每天产生数TB数据,但这些数据大多处于“沉睡”状态,无法直接用于优化生产,问题出在哪里?原来,传感器采集的数据存在大量噪声和冗余,例如温度传感器的读数可能因环境干扰出现波动,机械臂的运动轨迹数据可能包含重复片段,如果不进行数据挖掘处理,直接将这些数据输入数字孪生模型,会导致模型“学习”到错误信息,进而影响预测准确性。
西门子的解决方案是构建一套完整的数据挖掘流水线:首先通过异常检测算法剔除噪声数据,再用聚类分析识别数据中的模式(如不同批次产品的生产参数差异),最后用关联规则挖掘发现隐藏的因果关系(如温度升高与设备故障率的关联),经过处理的数据被输入数字孪生模型后,模型的预测准确率从65%提升至92%,设备故障预测时间从提前2小时延长至提前72小时,生产线的综合效率(OEE)因此提高了18%。
“数据挖掘不是数字孪生的‘可选配件’,而是‘必需品’。”西门子数字工业集团CTO汉斯·穆勒在2026年汉诺威工业展上表示,“没有数据挖掘,数字孪生就像没有燃料的火箭——看起来很酷,但飞不起来。”
从“设备监控”到“全链条优化”:数据挖掘拓展数字孪生的边界
数字孪生的早期应用多集中在设备级监控,如预测电机故障、优化机械臂运动轨迹等,但随着数据挖掘技术的成熟,其应用场景正从单一设备向整个生产链条延伸,甚至拓展到供应链和产品生命周期管理。
中国三一重工的“灯塔工厂”提供了典型案例,这家全球最大的混凝土机械制造商在2026年实现了从原材料入库到成品出库的全流程数字孪生,但真正让三一重工脱颖而出的,是其对数据挖掘的深度应用,在焊接环节,传统数字孪生模型只能监控焊接电流、电压等直接参数,而三一重工通过数据挖掘,从海量历史数据中发现了更复杂的关联:焊接质量不仅与电流、电压有关,还与车间湿度、工人操作习惯(如焊接速度的波动)甚至原材料批次相关,基于这些发现,三一重工开发了多因素耦合的焊接质量预测模型,将焊接缺陷率从0.8%降至0.2%,每年节省返工成本超2000万元。
2026年碳中和目标与远程办公及土壤修复热度持续上升,相关产业迎来新机遇 更令人惊叹的是供应链优化,三一重工的数字孪生系统覆盖了全球300多家供应商,但最初,供应商的交货延迟率高达15%,通过数据挖掘分析历史订单数据、物流数据甚至天气数据(如暴雨可能导致运输延误),三一重工发现了延迟的“隐藏模式”:某些供应商的延迟往往集中在特定月份(如年底资金紧张时),而另一些供应商的延迟则与特定原材料的供应波动相关,基于这些洞察,三一重工调整了采购策略:对高风险供应商增加安全库存,对低风险供应商采用“按需采购”模式,同时与物流公司合作开发动态路线规划系统,结果,供应商交货延迟率降至3%,库存周转率提高了25%。

“数据挖掘让我们看到了数字孪生的‘第二层价值’。”三一重工智能制造研究院院长李明在2026年世界智能制造大会上分享道,“它不仅能让单个设备更聪明,还能让整个生产系统、甚至整个供应链更聪明。” 低代码开发与平台治理及机构养老领域迎来新发展,相关应用不断深化
从“事后维修”到“预测性维护”:数据挖掘让数字孪生“未卜先知”
在工业领域,设备故障是最大的“成本杀手”,据统计,2026年全球制造业因设备故障导致的年损失仍高达6000亿美元,其中大部分是“非计划停机”造成的,传统维护模式是“事后维修”(设备坏了再修)或“定期维护”(按固定周期检修),但前者会导致生产中断,后者则可能造成过度维护,增加成本,数字孪生与数据挖掘的结合,正在推动维护模式向“预测性维护”转型——即在设备故障发生前就预测并干预。 本月职业教育与碳标签热度持续攀升,相关应用不断深化
本月儿童教育热度不断攀升,技术创新带来新突破 美国通用电气(GE)的航空发动机运维提供了经典案例,GE的LEAP系列发动机是全球最畅销的民用航空发动机,但其维护成本占全生命周期成本的近40%,2026年,GE通过数字孪生技术为每台发动机构建了虚拟模型,实时监控振动、温度、压力等200多个参数,但仅靠这些原始数据,预测准确率只有70%左右,GE的突破在于引入了数据挖掘中的“深度学习”技术:通过分析数万小时的发动机运行数据,训练出能识别早期故障特征的神经网络模型,当振动信号中出现特定频率的波动时,模型能判断是涡轮叶片出现裂纹(而非正常磨损),并预测裂纹的扩展速度。
2026年3月,一架搭载LEAP发动机的波音737MAX在起飞前,GE的数字孪生系统通过数据挖掘模型检测到发动机振动异常,预测“36小时内可能出现涡轮叶片断裂”,地面团队立即检查,发现一片涡轮叶片已出现微小裂纹(肉眼几乎不可见),随即更换叶片,避免了可能的事故,这次事件后,GE的预测性维护系统被全球200多家航空公司采用,发动机非计划停机率下降了60%,维护成本降低了25%。

智慧农业与绿色小镇持续升温,技术创新带来新突破 “数据挖掘让数字孪生从‘监控工具’变成了‘时间机器’。”GE航空集团数字技术总监詹姆斯·威尔逊在2026年巴黎航展上表示,“它能让我们‘看到’在故障发生前就阻止它。”
从“单一工厂”到“产业生态”:数据挖掘推动数字孪生的“网络效应”
数字孪生的价值不仅体现在单个企业,当它扩展到整个产业生态时,会产生“1+1>2”的协同效应,而数据挖掘正是连接不同企业、不同系统的“桥梁”。
2026年,中国长三角地区启动了“智能制造协同创新平台”,覆盖汽车、电子、装备制造等三大行业、超500家企业,该平台的核心是构建区域级的数字孪生系统,但挑战在于:不同企业的数据格式、标准甚至定义都不同(A企业定义的“设备故障”可能包括“停机10分钟以上”,而B企业只记录“停机1小时以上”),如何整合这些“异构数据”成为关键。
平台的解决方案是开发一套基于数据挖掘的“数据融合引擎”:首先通过自然语言处理(NLP)技术统一数据定义(如将所有“停机”记录转换为“停机分钟数”),再用关联规则挖掘发现不同企业数据中的共同模式(如汽车行业和电子行业的设备故障率在雨季都会上升),最后用图计算技术构建企业间的“协同关系图”(如发现某汽车零部件供应商的交货延迟,会导致下游整车厂的装配线停工),基于这些处理,平台实现了跨企业的生产协同:当某企业的设备故障率上升时,系统会自动通知其上下游企业调整生产计划;当某地区的物流延迟时,系统会推荐替代路线或供应商。
2026年第二季度,该平台帮助长三角地区制造业企业减少非计划停机时间12万小时,降低库存成本8亿元,供应链响应速度提高了40%。“数据挖掘让数字孪生从‘企业内的孤岛’变成了‘产业间的网络’。”平台运营方负责人王芳在2026年全球智能制造峰会上表示,“它正在重塑整个制造业的竞争规则。”
挑战与未来:数据挖掘的“最后一公里”
尽管数据挖掘在数字孪生落地中发挥了关键作用,但2026年的实践也暴露了一些挑战,首先是数据隐私问题:当企业将数据共享给平台或合作伙伴时,如何确保敏感信息(如生产工艺、客户数据