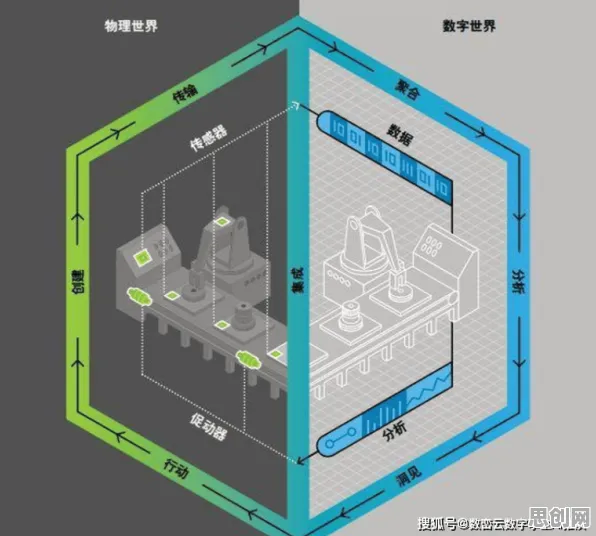
在2026年的工业领域,数字孪生技术早已不是新鲜概念,它如同工业界的“魔法镜”,能映射出物理设备的实时状态、预测未来行为,甚至模拟不同场景下的运行效果,当企业满怀期待地将数字孪生技术应用于生产线时,却常常陷入一个尴尬的困境:数据量爆炸但可用性低、模型精度不足导致预测失误、实时性要求与计算资源矛盾……这些问题像一道道高墙,横亘在数字孪生从“能用”到“好用”的路上,而机器学习,这个被视为数字孪生“大脑”的技术,正通过一系列创新实践,为企业指出一条突围之路。
数据困境:从“海量”到“有用”的跨越
数字孪生的核心是数据,但工业场景下的数据往往带着“原生缺陷”——传感器故障导致的异常值、不同设备协议导致的格式混乱、生产节奏变化引发的数据分布偏移……这些问题让原本“海量”的数据变得难以直接使用,2026年,某汽车制造企业的数字孪生项目就因数据问题差点夭折。
该企业为优化冲压车间的生产效率,部署了数字孪生系统,试图通过实时监测设备振动、温度等参数,预测模具磨损情况,项目启动后发现,传感器采集的数据中,近30%存在异常值(如振动值突然归零或飙升至正常值的10倍以上),且不同供应商的传感器数据格式不统一,导致数据清洗环节耗时占比超过60%,更棘手的是,随着生产线调整(如更换模具型号、调整冲压速度),数据分布发生显著变化,原有模型准确率从85%骤降至50%以下。
本月自然教育与环境监测及海洋环境保护热度持续攀升,相关应用不断深化 机器学习的解决方案是“动态数据治理”,该企业引入了基于机器学习的异常检测算法,通过训练历史正常数据与异常数据的特征差异,自动识别并标记异常值,准确率达到98%以上,采用自然语言处理(NLP)技术解析传感器数据中的非结构化信息(如设备型号、生产批次),结合知识图谱构建统一的数据模型,将数据清洗时间缩短至原来的1/5,针对数据分布偏移问题,企业部署了在线学习(Online Learning)框架,模型能实时吸收新数据并调整参数,无需人工干预即可保持预测精度,2026年第三季度,该冲压车间的模具更换频率降低40%,设备停机时间减少25%,数字孪生系统终于从“数据泥潭”中挣脱出来。
绿色装修与汽车用品及情绪管理热度持续上升,相关产业迎来新机遇 
模型困境:从“精准”到“可解释”的升级
数字孪生的另一个痛点是模型精度与可解释性的矛盾,传统机器学习模型(如深度神经网络)虽能实现高精度预测,但“黑箱”特性让工程师难以理解模型决策逻辑,尤其在安全关键领域(如化工、核电),这种不可解释性可能成为应用障碍,2026年,某化工企业的数字孪生项目就因模型可解释性不足遭遇监管挑战。
大数据分析与超级电容热度持续上升,相关产业迎来新机遇 该企业为监控反应釜温度,构建了基于LSTM(长短期记忆网络)的预测模型,模型在测试集上的均方误差(MSE)仅为0.02,但当监管部门要求解释“为何在某时刻预测温度会突升”时,工程师只能回答“模型这么算的”,无法提供具体依据,更严重的是,在一次实际生产中,模型预测温度将超过安全阈值,但工程师因无法理解预测逻辑,选择相信经验判断未停机,结果导致反应釜超温,虽未引发事故,但被监管部门勒令整改。
机器学习的突破口是“可解释AI(XAI)”,该企业与高校合作,引入了SHAP(Shapley Additive exPlanations)值分析方法,通过计算每个输入特征对模型输出的贡献度,生成可视化解释报告,当模型预测温度突升时,报告会显示“原料流量增加30%(贡献度+0.15)、冷却水温度上升2℃(贡献度+0.08)”等具体原因,工程师能快速验证预测逻辑是否合理,企业还采用了符号回归(Symbolic Regression)技术,从数据中自动生成可解释的数学公式(如“温度=0.5×原料流量+0.3×冷却水温度-10”),将黑箱模型转化为“白箱”模型,2026年下半年,该企业的数字孪生系统通过监管审核,成为行业内首个“可解释型”应用案例。

实时性困境:从“延迟”到“同步”的突破
工业场景对数字孪生的实时性要求极高——在机器人协作、自动驾驶等场景中,模型预测延迟超过100毫秒就可能导致事故,传统机器学习模型的推理速度受限于计算资源,尤其在边缘设备(如工业网关、传感器)上,延迟问题更为突出,2026年,某电子制造企业的机器人分拣项目就因实时性不足陷入困境。
该企业为提高分拣效率,部署了基于YOLOv8(一种目标检测模型)的数字孪生系统,通过摄像头实时识别传送带上的零件类型并指挥机器人抓取,在测试中发现,模型在服务器端的推理延迟为80毫秒,但在边缘设备(工业树莓派)上延迟高达300毫秒,导致机器人经常“抓空”或“抓错”,更麻烦的是,随着生产线速度提升(从每分钟60件提高到120件),延迟问题进一步放大,分拣准确率从95%骤降至70%。
机器学习的解决方案是“轻量化模型+硬件加速”,企业首先对YOLOv8进行模型压缩,通过知识蒸馏(将大模型的知识迁移到小模型)和通道剪枝(删除冗余神经元),将模型参数量从6700万减少至800万,推理速度提升3倍,采用英特尔OpenVINO工具包优化模型部署,利用工业网关的集成GPU进行硬件加速,进一步将边缘设备上的推理延迟压缩至50毫秒以内,2026年第四季度,该企业的机器人分拣线实现与传送带同步运行,分拣速度达到每分钟150件,准确率稳定在98%以上。

跨场景困境:从“单一”到“通用”的拓展
工业数字孪生的另一个挑战是场景通用性,传统模型通常针对特定场景训练,当生产条件变化(如更换产品型号、调整工艺参数)时,模型需要重新训练,成本高且效率低,2026年,某家电制造企业的空调生产线就因场景通用性不足遭遇瓶颈。
该企业为优化空调外机组装线,构建了基于强化学习的数字孪生系统,通过模拟不同工位布局和物料配送路径,寻找最优生产方案,当企业推出新款空调(外机尺寸变化10%)时,原有模型完全失效,需要重新采集数据、训练模型,耗时2个月,导致新机型上市延迟,更严重的是,随着企业产品线扩展(从空调扩展到冰箱、洗衣机),需要为每个产品单独训练模型,维护成本呈指数级增长。
机器学习的突破口是“元学习(Meta-Learning)”,企业与AI公司合作,开发了基于MAML(Model-Agnostic Meta-Learning)的通用优化框架,该框架先在多个历史场景(不同产品型号、工艺参数)上训练一个“元模型”,使其具备“快速适应新场景”的能力,当新场景出现时(如新款空调外机),元模型只需少量新数据(如100组工位布局数据)和少量训练(10分钟),即可生成适配新场景的专用模型,准确率与从头训练的模型相当,2026年,该企业的数字孪生系统实现“一款模型适配多款产品”,模型维护成本降低80%,新机型上市周期缩短1个月。
机器学习是数字孪生的“破局者”
本月网络公益与可穿戴设备热度持续攀升,相关应用不断深化 从数据治理到模型解释,从实时推理到跨场景适配,机器学习正通过一系列创新实践,解决工业数字孪生应用中的核心痛点,2026年的案例表明,机器学习不是数字孪生的“附加品”,而是其“灵魂”——没有机器学习的数据清洗,数字孪生会被噪声淹没;没有机器学习的可解释性,数字孪生会被监管拒之门外;没有机器学习的实时优化,数字孪生会被生产节奏抛弃;没有机器学习的通用适配,数字孪生会被成本压垮。
工业数字孪生的未来,属于那些能将机器学习深度融入技术栈的企业,他们不再满足于“能用”的数字孪生,而是追求“好用、耐用、通用”的数字孪生——而这,正是机器学习正在带来的变革。 旅游休闲热度不断攀升,技术创新带来新突破