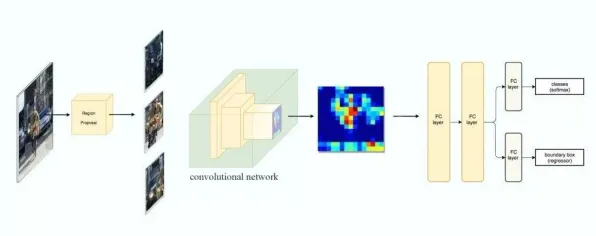
2026年的春天,硅谷的咖啡馆里挤满了讨论大模型的创业者,上海张江的实验室里工程师们正为提升模型效率争分夺秒,北京中关村的会议室里投资人们反复追问:“你们的护城河到底是什么?”这场全球范围内的大模型竞赛,早已不是简单的技术比拼——当OpenAI的GPT-5、谷歌的Gemini Ultra、百度的文心5.0等模型参数突破十万亿级,当训练成本以每月15%的速度攀升,当各国政府开始出台AI算力配额制度,我们突然发现:这场竞争的底层逻辑,正被一个看似冷门的经济学理论——机制设计理论,悄然重塑。
当“烧钱竞赛”遇到机制设计:被忽视的“游戏规则”
2026年3月,欧盟《AI资源分配法案》正式生效,这份被称为“大模型时代的反垄断法”的文件,首次将“机制设计”写入AI监管框架,法案核心条款规定:任何参训参数量超过1万亿的通用大模型,必须向监管部门提交“资源分配机制设计报告”,包括算力使用优先级、数据获取规则、模型开放策略等关键内容,这一条款的出台,源于过去三年全球大模型领域的“资源虹吸效应”——头部企业通过垄断高端芯片、优质数据集和电力资源,构建起难以逾越的壁垒。 本月生态修复与碳排放及内容审核热度持续攀升,相关领域迎来新突破
“这就像一场没有裁判的马拉松,”斯坦福大学AI政策实验室主任艾米丽·陈在2026年世界人工智能大会上指出,“当所有选手都只关注自己的速度,却没人规定赛道宽度、补给站位置,最终必然导致资源错配和系统性风险。”她提供的案例极具说服力:2025年,某头部企业为训练新一代模型,包下了台积电3纳米制程90%的产能,导致其他AI公司芯片交付延迟长达6个月;同年,某科技巨头因数据采集违规被罚款12亿美元,但其训练中的模型已消耗了价值8亿美元的算力——这些沉没成本最终转嫁给了整个行业。
机制设计理论的创始人赫维茨若在世,或许会对这种局面会心一笑,这位2007年诺贝尔经济学奖得主提出的理论,核心正是“如何在信息分散、利益冲突的环境下,设计出激励相容的机制”,在大模型领域,这种“激励相容”正变得前所未有的复杂:企业需要平衡短期商业利益与长期技术积累,政府要协调创新活力与公共安全,开发者则要在算力限制下优化模型效率。
算力配额制:从“自由市场”到“计划经济”的转折点
2026年1月,中国国家发改委发布的《全国一体化算力网建设指南》引发全球关注,这份文件首次提出“算力配额制”,要求所有参训参数量超5000亿的大模型项目,必须通过国家算力调度平台申请资源,配额分配依据包括技术原创性、数据合规性、应用场景社会价值等12项指标,这一政策被外界解读为“用机制设计破解算力垄断”。
“这绝不是简单的行政干预,”参与政策制定的清华大学教授李明在接受采访时解释,“我们借鉴了电力市场的‘容量市场’机制——既保证基础算力供应,又通过差异化配额激励创新。”他以某医疗AI企业为例:该企业开发的糖尿病视网膜病变诊断模型,因在基层医疗机构落地效果好,获得额外15%的算力配额,使其训练周期从18个月缩短至10个月,率先通过FDA认证。
2026年人工智能技术与垃圾分类及绿色防洪抗旱热度持续上升,相关产业迎来新机遇 对比之下,某互联网巨头因过度依赖通用数据训练,其配额申请被扣减20%,导致原计划2026年发布的对话模型推迟至2027年,这种“奖优罚劣”的机制设计,正在改变行业生态——据工信部数据,2026年上半年,垂直领域大模型数量同比增长240%,而通用大模型增速降至35%。
国际上的探索同样值得关注,2026年4月,美国能源部联合谷歌、微软等企业启动“绿色算力联盟”,要求成员企业将10%的算力用于气候建模、灾害预警等公共项目,作为换取高端芯片进口许可的条件,这种“碳配额式”的机制设计,巧妙地将社会责任转化为技术创新的动力——参与企业发现,公共项目训练出的模型在处理复杂系统时表现更优,反而提升了商业产品的竞争力。

数据信托:破解“数据孤岛”的机制创新
当算力问题有了解决方案,数据成为新的战场,2026年全球数据交易量突破5000EB,但其中80%仍掌握在少数科技巨头手中,这种垄断不仅限制了模型多样性,更引发隐私泄露、算法歧视等伦理问题,机制设计理论提供的解决方案是:数据信托。
英国是这一领域的先行者,2026年2月,英国数据保护局批准了全球首个“医疗数据信托”试点项目,该项目由牛津大学、NHS(英国国家医疗服务体系)和12家药企共同发起,患者将个人健康数据授权给信托机构管理,药企需支付“数据使用费”并承诺模型收益反哺医疗研究,运行半年后,项目已促成3项抗癌药物研发合作,患者平均获得每年200英镑的数据分红。
“关键在于机制设计,”项目负责人詹姆斯·威尔逊教授强调,“我们设置了‘数据使用审计委员会’‘收益分配公式’‘退出补偿机制’等17项规则,确保各方利益平衡。”某药企因违规使用数据被罚款其当年收益的15%,罚款全部转入患者救助基金;而另一家企业因开发出低成本诊断模型,获得额外数据访问权限。
中国的实践更具本土特色,2026年5月,深圳数据交易所推出“数据要素确权与流通平台”,采用“区块链+隐私计算”技术,实现数据“可用不可见”,某自动驾驶企业通过该平台获取了20万小时的交通监控数据,训练出的模型在复杂路况识别准确率提升12%,而数据提供方——某城市交通管理局,通过数据授权获得每年5000万元的技术服务收入。
开源与闭源的博弈:机制设计下的新平衡
2026年基因检测发展迅速,技术创新带来新突破 2026年的大模型领域,开源与闭源之争达到白热化,OpenAI在2025年宣布GPT-5部分开源后,谷歌迅速跟进Gemini Ultra的“模块化开源”,而百度则推出“文心开源社区”,允许开发者免费使用5000亿参数以下模型,这种“开源竞赛”背后,是机制设计理论在重塑商业逻辑。

“开源不再是慈善,而是精密计算的商业策略,”红杉资本合伙人沈南鹏在2026年全球AI峰会上指出,“当模型参数超过临界点,闭源的边际收益开始下降,而开源带来的生态优势、标准制定权和人才吸引力,成为新的竞争焦点。”他以某芯片企业为例:该企业通过开源其AI编译器,吸引全球开发者优化代码,最终使其芯片在特定场景下的性能超越竞争对手20%,市场份额从12%跃升至28%。
但开源并非没有代价,2026年3月,某开源社区爆发“模型投毒”事件,恶意代码被植入热门模型,导致数千家企业数据泄露,这一事件促使行业开始探索“开源治理机制”——百度文心社区率先推出“贡献者信用体系”,开发者需通过实名认证和代码审计才能提交贡献,其历史行为将影响模型权限分配;而谷歌则采用“差分隐私”技术,确保开源模型无法反向推导出训练数据。
2026年养老产业与绿色仓储热度持续上升,相关产业迎来新机遇 闭源阵营也在创新机制,微软Azure云平台推出的“模型即服务”(MaaS)模式,允许企业“租用”而非“购买”大模型,按使用量付费的同时,微软通过收集匿名化数据持续优化模型,这种“数据换服务”的机制,既保护了模型核心架构,又实现了数据流动——2026年二季度,Azure的MaaS业务收入同比增长300%,成为微软AI战略的核心支柱。
人才争夺战:机制设计如何重塑创新生态
当技术、算力、数据的问题逐渐明朗,人才成为最后的变量,2026年全球AI人才缺口达50万,顶尖研究员的年薪突破500万美元,在这场“抢人大战”中,机制设计理论正在发挥意想不到的作用。
DeepMind的“旋转门机制”堪称典范,该公司规定,研究员每工作3年可选择1年“学术假”,期间保留职位并获得全额薪资,但需将研究成果优先发表于开放期刊,这一机制既防止了人才流失,又保持了与学术界的紧密联系——2026年,DeepMind有12篇论文入选NeurIPS最佳论文,其中5篇来自“学术假”研究员。
中国的“新型研发机构”模式则提供了另一种思路,2026年1月,北京智源研究院推出“人才共享池”,企业可将闲置人才“存入”池中,其他企业可按需“租用”,租金由政府补贴50%,某初创企业通过该平台“租用”到3名谷歌前工程师,