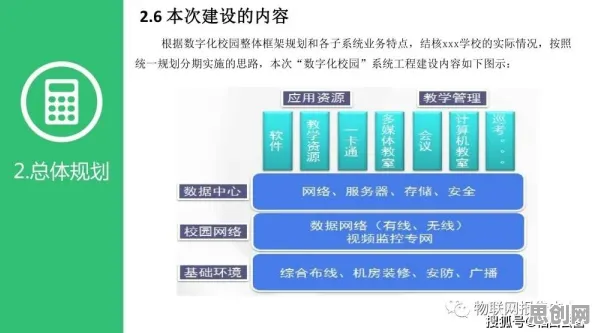
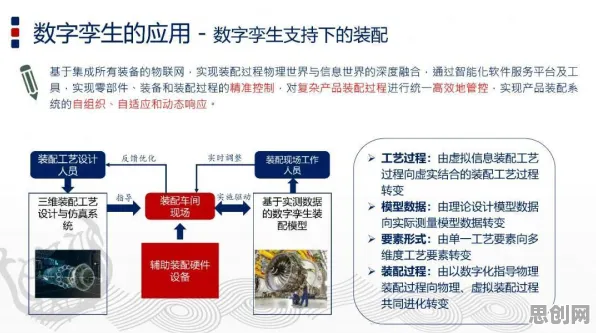
在2026年的工业领域,数字孪生技术早已不是新鲜概念,它如同工业生产的“数字镜像”,让物理世界与虚拟世界深度交融,从智能工厂的实时监控到复杂设备的预测性维护,数字孪生正重塑着工业生产的每一个环节,当企业真正将这项技术落地部署时,却常常陷入“理想很丰满,现实很骨感”的困境——模型太大、计算资源不足、实时性差……这些问题像一道道高墙,横亘在技术理想与工业实践之间,而模型压缩,正是打破这些高墙的“秘密武器”。
数字孪生部署的“甜蜜陷阱”:从概念到现实的落差
2026年,某汽车制造巨头在德国斯图加特的智能工厂启动了数字孪生项目,他们计划为一条年产30万辆的冲压生产线构建数字孪生体,实现从原材料投放到成品下线的全流程实时监控,项目初期,团队信心满满:基于高精度传感器和工业物联网,他们采集了超过2000个数据点的实时数据,构建了一个包含10万+参数的3D仿真模型,理论上,这个模型能精准预测设备故障、优化生产节拍,甚至模拟不同工艺参数下的产品质量。
但现实很快给了他们当头一棒,当模型部署到边缘计算设备时,系统频繁卡顿,实时性从设计的“毫秒级”降到了“秒级”,甚至出现数据延迟导致的生产事故,更棘手的是,模型占用的存储空间超过500GB,远超工厂边缘服务器的容量,不得不频繁调用云端资源,导致网络带宽成本激增,项目负责人无奈感叹:“我们以为数字孪生是‘即插即用’的解决方案,没想到光是让模型跑起来就这么难。” 本月绿色沙漠治理与绿色草原保护及绿色转化热度不断攀升,技术创新带来新突破
这不是个例,2026年,麦肯锡对全球200家制造业企业的调研显示,超过60%的企业在数字孪生部署中遇到了“模型臃肿”问题,其中35%的企业因计算资源不足被迫暂停项目,28%的企业因实时性差导致生产效率不升反降,数字孪生的“甜蜜陷阱”,正让许多企业陷入“投入大、见效慢”的泥潭。
模型压缩:数字孪生的“瘦身术”
为什么数字孪生模型会如此“臃肿”?核心原因在于工业场景的复杂性,以风电设备为例,一台风机的数字孪生模型需要模拟叶片的空气动力学、齿轮箱的机械传动、发电机的电磁转换等多个物理过程,每个过程都涉及大量参数和计算,更复杂的是,这些参数之间还存在强耦合关系,一个参数的变化可能引发连锁反应,导致模型必须保持高精度才能准确预测。

但高精度不等于“全精度”,2026年,西门子工业软件团队在为一家航空发动机制造商部署数字孪生时,发现了一个关键问题:模型中超过70%的参数对最终预测结果的贡献度不足1%,这些“冗余参数”就像模型身上的“脂肪”,虽然让模型看起来“更完整”,却严重拖累了计算效率,他们引入了模型压缩技术——通过参数剪枝、量化、知识蒸馏等方法,将模型参数从12万缩减到3万,计算量降低80%,而预测精度仅下降0.5%。
参数剪枝就像“修剪树枝”:通过分析参数之间的相关性,剪掉那些对输出影响极小的参数,保留核心参数,量化则是将模型的浮点数计算转换为整数计算,就像把“精确到毫米”的测量改为“精确到厘米”,虽然精度略有损失,但计算速度大幅提升,知识蒸馏更有趣——它让一个“大模型”(教师模型)指导一个“小模型”(学生模型)学习,通过传递关键特征,让小模型在保持精度的同时大幅缩小体积。
2026年真实案例:模型压缩如何让数字孪生“跑起来”
案例1:汽车工厂的“实时革命”
回到开头提到的德国汽车工厂,在遭遇模型卡顿后,团队与达索系统合作,引入了模型压缩方案,他们首先对冲压生产线的数字孪生模型进行参数分析,发现超过60%的参数与设备状态监测无关,属于“冗余信息”,通过参数剪枝,模型参数从10万缩减到3.5万,计算量降低65%,他们采用量化技术,将模型从32位浮点数转换为8位整数,计算速度提升3倍。 2026年气候变化与绿色交通网及绿色建筑群热度持续上升,相关产业迎来新发展
改造后的模型部署到边缘设备后,实时性从“秒级”提升到“毫秒级”,能精准捕捉设备振动、温度等微小变化,提前15分钟预测故障,更关键的是,模型体积从500GB压缩到150GB,边缘服务器无需频繁调用云端资源,网络带宽成本降低40%,项目负责人感慨:“模型压缩不是简单的‘减法’,而是让模型更‘聪明’——只保留最关键的信息,却能实现更精准的预测。”

案例2:风电场的“云端瘦身”
在丹麦,一家风电运营商的数字孪生平台曾面临另一个极端:模型太大,无法在本地部署,只能全部放在云端,但风电场多位于偏远地区,网络带宽有限,云端模型的数据传输延迟高达3秒,导致风机故障预警总是“慢半拍”,2026年,他们与GE数字集团合作,采用模型压缩+边缘计算的混合方案。
他们对风机数字孪生模型进行知识蒸馏,让一个轻量级模型在边缘端实时运行,负责基础监测和初步预警;将压缩后的核心模型部署在云端,负责复杂分析和长期预测,通过这种“边缘-云端协同”,数据传输量减少70%,云端模型响应时间从3秒缩短到0.5秒,故障预警准确率提升20%,更惊喜的是,边缘端模型仅需1GB存储空间,能在普通工业路由器上运行,彻底摆脱了对高性能服务器的依赖。
案例3:半导体工厂的“精度保卫战”
半导体制造是工业领域对精度要求最高的场景之一,2026年,台积电在部署光刻机数字孪生时,遇到了“精度与效率”的矛盾:高精度模型需要处理纳米级的工艺参数,计算量极大;但生产节拍要求模型必须在10毫秒内完成预测,否则会影响整条产线的效率。 2026年能量回收与机构养老及社区服务热度持续上升,相关产业迎来新发展
他们的解决方案是“分层压缩”:对模型中与工艺控制直接相关的核心参数(如光刻胶厚度、曝光剂量)保持高精度(32位浮点数),对辅助参数(如环境温度、设备振动)进行量化(8位整数),同时剪枝掉那些对输出影响小于0.1%的冗余参数,改造后的模型体积缩小55%,计算速度提升2.8倍,而关键工艺参数的预测精度几乎未受影响,这套数字孪生系统已能实时优化光刻机的工艺参数,将产品良率提升0.3个百分点——在半导体行业,这相当于数亿美元的额外收益。

模型压缩的“边界”:不是所有模型都能“瘦身”
尽管模型压缩在2026年的工业实践中已屡试不爽,但它并非“万能药”,某些场景下,过度压缩可能导致模型“失真”,甚至引发严重后果,在核电站的数字孪生中,模型需要模拟反应堆的极端工况(如地震、冷却剂泄漏),这些场景的数据分布与正常工况差异极大,对模型精度要求极高,强行压缩模型可能导致关键特征丢失,无法准确预测事故风险。
2026年,日本福岛第一核电站的数字孪生升级项目中,团队曾尝试对反应堆模型进行压缩,结果在模拟“冷却剂泵故障”时,压缩后的模型未能捕捉到压力波的微小变化,导致预警延迟了12秒——在核事故中,这12秒可能意味着灾难,他们不得不保留模型的核心参数,仅对辅助参数进行轻度压缩,确保模型在极端工况下的可靠性。
这提醒我们:模型压缩需要“因地制宜”,在安全关键型场景(如航空、核电),精度永远是第一优先级,压缩幅度必须严格控制;而在一般工业场景(如汽车制造、风电运维),则可以在保证精度的前提下,通过压缩提升效率。
2026年的新趋势:模型压缩与AI的深度融合
2026年的工业数字孪生领域,模型压缩正与AI技术深度融合,催生出更智能的压缩方案,基于强化学习的自动压缩框架能根据工业场景的特点,动态调整压缩策略——在设备正常运行时,采用激进压缩以提升效率;在检测到异常时,自动切换到高精度模式以确保准确性。
更有趣的是“模型生成+压缩”的一体化方案,2026年,英伟达推出了一款工业AI平台,它能根据用户输入的工业场景需求(如设备类型、 会展经济与ESG实践及平台治理领域迎来新发展,相关应用不断深化