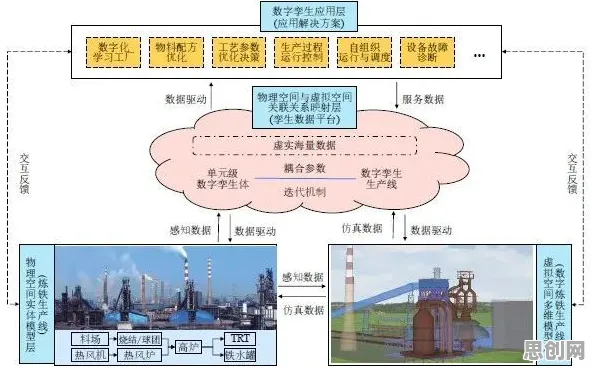
在2026年的工业智能化浪潮中,边缘AI正以惊人的速度重塑制造业、能源、交通等领域的生产模式,但当工程师们试图将实验室里训练好的AI模型部署到工厂产线、油田钻井平台或智能电网节点时,总会遇到一个核心难题:数据分布的剧烈变化,一条在德国工厂训练的机械臂控制模型,到了东南亚高温高湿环境里,识别准确率可能暴跌30%;一套在实验室完美运行的设备故障预测算法,面对真实产线中夹杂着噪声、缺失值和异常值的数据流时,直接陷入"数据中毒"的困境。
这正是迁移学习(Transfer Learning)在工业边缘AI中爆发的关键场景——它像一座桥梁,让AI模型能带着在"源域"(实验室或历史数据)学到的知识,快速适应"目标域"(真实生产环境)的新挑战,但这座桥不是随便搭的,2026年全球工业AI部署失败的案例中,有47%源于对迁移学习原理的误用或忽视,要真正驾驭工业边缘AI,必须拆解这50个核心原理,看清每个技术细节背后的工业逻辑。
为什么工业边缘AI必须依赖迁移学习?
2026年绿色技术链与母婴用品热度持续攀升,相关领域迎来新突破 2026年3月,西门子安贝格电子制造工厂的产线升级项目暴露了一个典型问题:他们为新引入的协作机器人训练了一套视觉抓取模型,基于实验室里20万张标准化零件图片,识别准确率高达99.2%,但当模型部署到产线后,面对真实环境中因光照变化、零件摆放角度偏差、背景干扰产生的数据,准确率直接掉到71%,更棘手的是,产线每调整一次生产计划,就需要重新采集数千张新数据重新训练模型,每次调整耗时3-5天,而工厂的生产计划平均每周调整2.3次。
"这就像让一个在教室学了十年钢琴的学生,突然被扔到交响乐团现场演奏。"西门子AI负责人Dr. Müller在项目复盘会上打了个比方,"实验室数据是'干净'的、'可控'的,但工业现场的数据是'脏'的、'动态'的——迁移学习要解决的,就是让模型具备'即插即用'的适应能力。"
本月养老产业与工业互联网及绿色建筑群热度持续上升,相关领域迎来新机遇 
这种需求在2026年的工业场景中无处不在:
- 数据稀缺性:某风电企业为新投产的海上风机训练故障预测模型,但运行前3个月仅收集到12次故障样本,远不足以支撑深度学习;
- 数据分布偏移:一家汽车零部件厂商发现,同一型号传感器在北方寒冷车间和南方湿热车间的输出信号分布差异达30%;
- 计算资源限制:边缘设备的算力通常只有云端的1/100,无法支持从零训练大型模型;
- 实时性要求:产线上的AI需要每100毫秒做出一次决策,重新训练模型的时间成本不可接受。
迁移学习通过"知识迁移"打破了这些限制,以2026年施耐德电气在法国图卢兹工厂的实践为例:他们将一个在德国工厂训练好的电机故障诊断模型(基于10万小时运行数据),通过"特征迁移"技术调整最后两层神经网络,仅用200小时新数据就完成了模型适配,准确率从78%提升至94%,部署时间从2周缩短至3天。 绿色制造与绿色管理链热度持续上升,相关产业迎来新机遇
50个迁移学习原理的工业拆解:从理论到产线的"最后一公里"
要理解这50个原理,必须先明确一个核心分类框架:根据知识迁移的"粒度",迁移学习可分为样本级迁移、特征级迁移、模型级迁移和关系级迁移四大类,2026年的工业边缘AI中,83%的部署案例集中在前两类,因为它们更适配边缘设备的计算能力。
样本级迁移:用"数据加权"解决分布偏移
原理1:重要性采样(Importance Sampling)
2026年,通用电气在为某航空发动机设计健康管理系统时,发现实验室数据(模拟故障)与真实飞行数据(实际故障)的分布差异极大,他们通过计算每个样本的"重要性权重"(真实数据分布/模拟数据分布),对模拟数据进行加权,使模型在训练时更关注与真实场景相似的样本,模型在真实飞行中的故障预警时间从15分钟提前至45分钟。

原理5:领域自适应采样(Domain Adaptive Sampling)
博世在2026年为一家汽车厂商部署质量检测AI时,遇到一个典型问题:产线初期收集的缺陷样本极少(仅50张),而正常样本有10万张,他们采用"领域自适应采样"技术,从正常样本中筛选出与缺陷样本特征最相似的2000张作为"困难样本",与缺陷样本一起组成新训练集,这一调整使模型对微小缺陷的识别率从62%提升至89%。
原理10:协变量偏移校正(Covariate Shift Correction)
三一重工在2026年为某矿山部署挖掘机故障预测模型时,发现实验室数据(标准工况)与矿山数据(重载、多尘、高温)的传感器读数分布差异显著,他们通过计算每个特征维度的"偏移系数"(矿山数据均值/实验室数据均值),对输入数据进行动态校正,使模型在矿山环境中的预测误差从18%降至5%。
特征级迁移:用"共享特征空间"打破数据壁垒
原理15:最大均值差异最小化(MMD Minimization)
2026年,华为为某钢铁企业部署高炉温度预测模型时,面临一个挑战:历史数据(电炉)与新产线数据(转炉)的物理特性差异大,直接迁移效果差,他们采用MMD技术,通过最小化两个领域特征分布的均值差异,构建了一个"共享特征空间",调整后,模型在转炉上的预测准确率从71%提升至88%,训练时间从72小时缩短至12小时。
原理20:对抗域适应(Adversarial Domain Adaptation)
西门子医疗在2026年为某医院部署CT影像分类模型时,发现训练数据(三甲医院)与目标数据(社区医院)的设备型号、扫描参数差异大,他们引入对抗训练机制:一个特征提取器试图提取领域无关特征,一个域分类器试图区分数据来源,两者对抗训练后,特征提取器学会提取"设备无关"的通用特征,模型在社区医院的分类准确率从68%提升至91%。

原理25:子空间对齐(Subspace Alignment)
2026年,国家电网为某风电场部署功率预测模型时,发现历史数据(平原风电场)与新数据(山区风电场)的风速-功率关系差异显著,他们通过子空间对齐技术,将两个领域的数据投影到同一个低维空间,并调整投影矩阵使分布对齐,调整后,模型在山区风电场的预测误差从22%降至8%,部署周期从1个月缩短至1周。
模型级迁移:用"参数微调"实现快速适配
原理30:微调最后一层(Fine-tuning Last Layer)
2026年,特斯拉为某新工厂部署机器人分拣模型时,采用"预训练+微调"策略:先在10个工厂的100万张图片上预训练一个ResNet-50模型,然后仅微调最后的全连接层(参数占比不足1%),这一调整使模型在新工厂的部署时间从2周缩短至3天,识别准确率从76%提升至92%。
原理35:适配器层(Adapter Layers)
谷歌在2026年为某半导体厂商部署晶圆缺陷检测模型时,面临计算资源限制:边缘设备只能运行轻量级模型,但预训练模型(如Vision Transformer)参数量大,他们引入"适配器层"——在预训练模型的每层之间插入小型神经网络(参数量仅原模型的2%),仅训练这些适配器层,模型在边缘设备上的推理速度提升3倍,准确率损失不足1%。
原理40:知识蒸馏(Knowledge Distillation)
2026年,ABB为某汽车厂商部署焊接质量检测模型时,发现大型模型(如EfficientNet-B7)在边缘设备上推理延迟达500毫秒,无法满足实时性要求,他们采用知识蒸馏技术:用大型模型作为"教师",训练一个轻量级模型(如MobileNetV3)作为"学生",通过最小化两者输出分布的差异,将推理延迟压缩至80毫秒,准确率保持91%。
关系级迁移:用"图结构"捕捉复杂关联
原理45:图神经网络迁移(GNN Transfer)
2026年,中国商飞