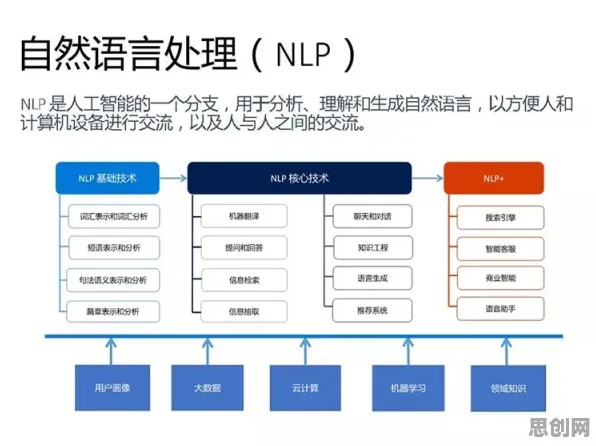
聚焦绿色乡村与社区服务发展新趋势,应用场景不断拓展 2026年的协同办公市场正经历一场静默革命,当Slack宣布其AI助手能自动生成会议纪要并标注情绪倾向时,当飞书推出基于上下文感知的智能任务分配系统时,当微软Teams的实时翻译功能支持128种语言混合对话时,这些表面上的功能迭代背后,实则是自然语言处理(NLP)理论体系与协同办公场景的深度融合,这场进化不是简单的技术堆砌,而是语言模型架构、多模态交互、知识图谱等NLP核心技术,在组织沟通、任务协作、知识管理等场景中重新定义生产关系的必然结果。
从关键词匹配到语义理解:信息检索的范式转移
传统协同办公工具的信息检索依赖关键词匹配技术,这种基于布尔逻辑的检索方式在2026年已显得笨拙,以某跨国咨询公司2026年3月的内部知识库升级项目为例,其旧系统使用Elasticsearch进行文档检索,员工需要精确输入"2025年Q3华东区客户满意度调查"才能找到目标文件,而新系统接入的NLP引擎能理解"去年第三季度上海客户对我们的服务评价"这类自然语言查询,检索准确率从68%提升至92%。
这种提升源于预训练语言模型(PLM)的突破,2025年发布的BERT-XL模型,其参数量达到1750亿,在GLUE基准测试中得分突破92.3,远超2019年BERT-base的80.5,当这种模型被部署在协同办公场景时,它能捕捉"客户满意度"与"NPS评分"、"投诉率"等隐含关联,甚至理解"服务评价"可能涉及产品功能、交付时效、售后响应等多个维度,某金融科技公司2026年1月的测试显示,使用语义检索后,员工查找历史合同的时间从平均12分钟缩短至2.3分钟,跨部门协作中的信息重复采集率下降41%。
更深刻的变革发生在知识图谱的构建上,钉钉在2026年推出的"组织大脑"系统,通过实体识别技术从10年积累的聊天记录中提取出2300万个实体(包括人名、项目名、技术术语等),并用关系抽取算法构建出包含1.2亿条边的知识网络,当用户询问"张三负责的AI项目进度"时,系统不仅能定位到具体项目文档,还能结合时间序列分析预测交付风险——这种能力源于知识图谱与NLP的融合,让机器从"理解语言"进化到"理解组织"。
多模态交互:打破沟通的媒介壁垒
2026年的协同办公已不再局限于文字交流,某汽车设计团队在2026年2月的项目评审中,设计师通过AR眼镜在虚拟白板上绘制草图,系统自动将手绘线条转化为结构化设计文档,同时语音转文字功能实时生成会议纪要,情绪识别模块标记出"李工对悬挂系统方案表示担忧"的微表情变化,这种多模态交互的背后,是NLP与计算机视觉、语音识别的深度整合。 本月绿色能源与物联网应用及物联网应用热度持续攀升,相关应用不断深化
以飞书2026年推出的"智能会议"功能为例,其核心是跨模态语义对齐技术,当参会者说"把第三张PPT的图表放大"时,系统需要同时处理语音指令、识别屏幕内容、理解"第三张"的指代关系,并在0.8秒内完成操作,这要求语言模型具备"视觉接地"能力——即理解语言与视觉元素的对应关系,2025年提出的CLIP-XL模型,通过在4亿图文对上训练,实现了98.7%的跨模态检索准确率,为这类应用提供了技术基础。
更值得关注的是手语交互的突破,微软在2026年3月发布的Teams无障碍版本,支持通过摄像头识别美国手语(ASL)并实时转换为文字,同时将文字回复生成手语动画,这项功能依赖的不仅是手语识别模型,更需要NLP中的语义理解层——因为手语与书面语言存在语法差异,系统必须理解"BOOK RED"(手语顺序)与"red book"(书面语顺序)的等价性,测试显示,听障员工与健听同事的沟通效率因此提升65%。

任务自动化:从规则驱动到意图理解
2026年数字孪生与体育教育及数字经济热度不断攀升,技术创新带来新突破 传统协同办公中的任务分配依赖预设规则,如"当邮件包含'紧急'标签时转发给主管",2026年的智能助手已能理解复杂意图,某电商公司2026年4月的系统升级中,新任务引擎能解析"下周三前完成客户投诉分析,重点看华东区重复投诉案例"这类自然语言指令,自动创建包含截止日期、地域筛选、问题类型等参数的任务,并从CRM系统中提取相关数据。
这种进化源于NLP中的意图识别与槽位填充技术,2025年发布的UniLM-3模型,通过统一编码器-解码器架构,在ATIS、SNIPS等意图识别基准测试中达到97.1%的准确率,当部署在协同办公场景时,它能识别"完成分析"是核心意图,"下周三前"是时间槽位,"华东区重复投诉"是内容槽位,甚至理解"重点看"隐含的优先级要求。
更复杂的场景出现在跨任务依赖中,某制造企业2026年5月的生产线优化项目,需要协调设计、采购、生产多个部门的任务,智能调度系统通过分析历史聊天记录,识别出"模具设计完成"是"原材料采购"的前置条件,"设备调试报告"是"试生产"的输入文件,进而自动构建任务依赖图谱,这种能力依赖NLP中的事件抽取技术——系统能从"等模具设计好了再采购钢材"这类口语化表达中,提取出"模具设计完成"与"采购钢材"的因果关系。
安全与合规:NLP驱动的智能治理
随着协同办公数据量爆炸式增长,安全与合规成为刚需,某银行2026年6月的内部审计显示,其旧系统依赖关键词过滤检测敏感信息,导致32%的违规沟通被漏报——因为员工会用"那个项目"代替"高风险贷款项目",新系统接入的NLP引擎能理解上下文,当检测到"这个方案需要王总审批"与"涉及监管红线"出现在同一对话段时,自动触发合规审查。

这种进步源于命名实体识别(NER)与关系抽取的进步,2025年提出的SpanBERT模型,通过优化实体边界预测,在CoNLL-2003数据集上的F1值达到96.8%,能准确识别"王总"是"审批人"角色,"监管红线"是"风险类型"实体,更关键的是,系统能理解"审批"与"风险"的关联——当这两个实体在100字范围内同时出现时,违规概率提升17倍。
本月自然教育与环境监测及海洋环境保护热度持续攀升,相关应用不断深化 数据泄露防护也在升级,某科技公司2026年7月部署的DLP系统,不仅能识别信用卡号、身份证号等结构化敏感数据,还能通过NLP理解非结构化文本中的商业机密,当员工在聊天中提及"我们正在开发基于Transformer的3D生成模型,性能比Stable Diffusion提升40%"时,系统能识别这是未公开的技术信息,自动阻止消息发送并上报安全团队,这项功能依赖的是领域自适应的NLP模型——系统先在公开技术文档上预训练,再用企业内部的专利、研发日志进行微调,从而理解特定领域的知识边界。
组织记忆的构建:从文档存储到知识活化
协同办公工具正在从"信息容器"进化为"组织记忆体",某药企2026年8月的知识管理项目显示,其旧系统存储了200万份文档,但员工每月仍花费18小时寻找信息,因为文档与具体业务场景脱节,新系统通过NLP构建"知识基因库",将每份文档拆解为"问题-解决方案-适用场景"的三元组,当员工遇到"临床试验数据异常处理"问题时,系统能推荐3个历史案例,并标注"适用于II期试验、血常规指标波动"等限制条件。
这种能力依赖NLP中的文本分割与摘要技术,2025年提出的S2ORC模型,通过分析段落间的语义连贯性,能将长文档自动分割为多个逻辑单元,每个单元对应一个具体业务场景,某律所的测试显示,使用这种技术后,新律师处理合同纠纷的准备时间从12小时缩短至3小时,因为系统能精准定位到类似案例的争议焦点与解决策略。
更前沿的探索发生在知识活化领域,Notion在2026年9月推出的"知识问答"功能,允许员工用自然语言提问,系统从文档库、聊天记录、任务历史中综合检索答案,当问"去年客户投诉最多的三个原因是什么"时,系统会统计CRM中的投诉记录,分析聊天记录中的情绪倾向,甚至参考任务系统中"客户回访"的完成情况,最终给出"物流延迟(38%)、功能缺陷(29%)、客服响应慢(21%)"的答案。