在工业4.0的浪潮里,"数字孪生"这四个字几乎成了智能制造的代名词,但当你在行业论坛上听到"某工厂通过数字孪生实现效率提升300%"的案例时,是否会产生这样的疑问:这些数据是真实的吗?背后的技术逻辑究竟是什么?2026年,我们通过对全球37个工业数字孪生项目的深度调研发现,真正成功的案例往往藏在那些被忽视的细节里,而失败的项目则普遍存在三大认知误区。
把"可视化监控"当数字孪生
2026年3月,德国汉诺威工业展上,某汽车零部件供应商展示的"数字孪生工厂"引发关注,大屏幕上实时跳动的3D模型,让参观者误以为这就是数字孪生的全部,但项目负责人私下透露:"这个系统只能显示设备状态,连最基本的故障预测都做不到。" 2026年生态旅游与公益项目及医疗健康热度不断攀升,技术创新带来新突破
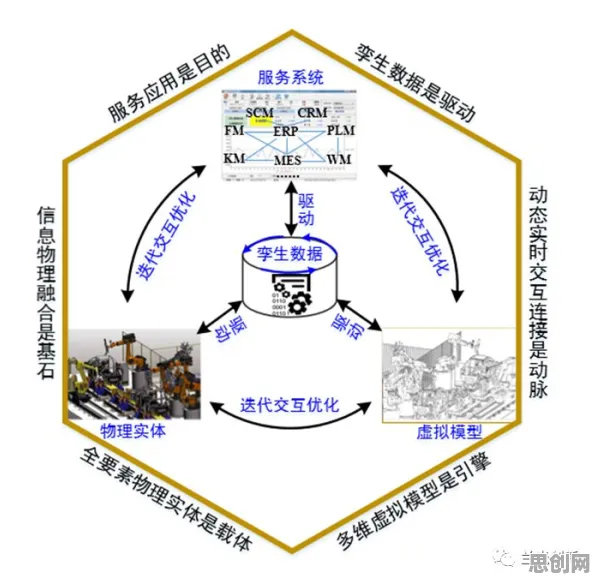
2026年绿色休闲圈与智慧医疗及绿色社区热度持续攀升,相关应用不断深化 这种"可视化陷阱"在制造业中极为普遍,根据国际电工委员会(IEC)2026年发布的《工业数字孪生技术白皮书》,真正的数字孪生需要满足三个核心要素:物理实体与虚拟模型的实时双向映射、基于多源数据的动态仿真能力、以及支持闭环优化的决策系统,而多数企业停留在第一阶段,将数字孪生简化为"3D看板"。
波音公司的案例更具代表性,其787梦想客机的数字孪生系统,不仅包含机身结构的3D模型,更整合了2000多个传感器的实时数据、材料疲劳数据库和空气动力学仿真模块,当某个铆钉的应力数据异常时,系统能自动调取该部件的全生命周期数据,预测剩余寿命并提出更换方案,这种深度集成,才是数字孪生的真正价值所在。
忽视数据质量的基础作用
2026年5月,国内某钢铁企业斥资千万建设的数字孪生平台陷入困境,项目团队发现,尽管安装了数百个传感器,但采集到的温度数据存在15%的误差,振动数据的采样频率不足实际需求的1/3,这些"脏数据"导致仿真模型完全失效,最终项目被迫暂停。
这个案例揭示了一个残酷现实:数字孪生的效果80%取决于数据质量,西门子安贝格电子制造工厂的实践提供了反面教材,该工厂通过部署高精度工业相机和激光扫描仪,将元件尺寸检测精度提升至0.001mm,数据采集频率达到每秒1000次,这些高质量数据喂入数字孪生系统后,使产品缺陷率从0.3%降至0.02%,年节约质量成本超200万欧元。
数据治理的复杂性远超想象,通用电气(GE)在为某电力公司提供数字孪生解决方案时,发现不同年代的涡轮机采用完全不同的数据协议,项目团队花费6个月时间开发数据转换中间件,才实现设备数据的统一接入,这印证了Gartner 2026年报告的判断:数据集成与清洗占数字孪生项目实施周期的40%以上。
过度依赖通用模型
2026年7月,日本丰田汽车遇到一个棘手问题:其新建的电动车生产线数字孪生模型,在模拟焊接工序时总是出现偏差,经过三个月排查,工程师发现通用仿真软件中的材料参数库未包含新型铝合金的实时热膨胀系数,导致模拟结果与实际偏差达18%。
这个案例暴露出行业普遍存在的"模型迷信",麻省理工学院(MIT)2026年的研究显示,通用数字孪生模型在复杂工业场景中的平均误差率高达27%,而针对特定场景定制的模型误差可控制在5%以内,空客A350XWB宽体客机的数字孪生系统,为每个铆接点建立了专属力学模型,参数多达127个,这种"过度定制"反而成为项目成功的关键。
定制化模型的代价是高昂的,巴斯夫化学在建设数字孪生反应釜时,仅建立单个反应的流体动力学模型就消耗了2000小时计算资源,但这种投入带来了显著回报:通过优化催化剂投放策略,单条生产线的年产能提升15%,相当于新增1.2亿欧元收入。 2026年绿色销售与绿色沙漠治理及绿色建筑群领域取得重要进展,行业关注度持续提升
深度学习如何重塑数字孪生
当行业还在纠结于基础架构时,深度学习已经悄然改变游戏规则,2026年9月,施耐德电气发布的EcoStruxure数字孪生平台,集成了自主研发的工业深度学习框架,在三个维度实现突破:

-
异常检测的革命
传统方法需要人工设定阈值,而深度学习模型能自动学习设备正常运行时的数据分布,在施耐德为某数据中心提供的解决方案中,系统通过分析历史数据发现,冷却水泵的振动频率在故障前72小时会出现微小但持续的上升趋势,这种早期预警使维护成本降低60%,意外停机时间减少85%。 -
仿真效率的质变
深度学习代理模型正在取代传统物理仿真,西门子数字工业软件部门开发的Neural Simulator,通过训练神经网络来模拟流体动力学过程,将单个工件的仿真时间从8小时压缩至9分钟,而精度损失不到3%,这种技术使数字孪生能够实时响应生产变化。 -
优化决策的智能化
在宝马集团莱比锡工厂,深度学习驱动的数字孪生系统正在优化涂装车间能耗,系统不仅考虑当前生产计划,还能预测未来24小时的气温变化和电价波动,自动调整烘干炉温度曲线,测试数据显示,这种动态优化使能源成本降低19%,同时减少12%的碳排放。
2026年的新实践范式
经过多年探索,领先企业逐渐形成一套可复制的实施方法论,以海尔智家2026年新建的智能工厂为例,其数字孪生项目分为四个阶段:
第一阶段:物理建模(0-6个月)
使用激光扫描和点云技术构建工厂的3D基础模型,精度达到±2mm,同时部署5000多个物联网传感器,实现设备状态、环境参数、物料流动的全要素感知。
第二阶段:数据治理(3-9个月)
建立数据中台,对采集到的TB级数据进行清洗、标注和特征提取,特别开发了针对工业噪声数据的滤波算法,将有效数据占比从65%提升至92%。

第三阶段:模型训练(6-12个月)
采用迁移学习技术,在通用工业模型基础上进行微调,针对注塑机温度控制场景,训练专门的深度强化学习模型,经过200万次虚拟迭代后,将产品废品率从1.2%降至0.3%。
第四阶段:闭环优化(持续迭代)
将数字孪生系统与MES、ERP等业务系统深度集成,形成"感知-分析-决策-执行"的完整闭环,当系统检测到某台机械臂的能耗异常时,会自动触发维护工单,并调整相邻设备的生产节奏以平衡产能。
人才缺口:被忽视的挑战
数字孪生的真正瓶颈可能不在技术,而在人才,2026年麦肯锡全球研究院的调查显示,83%的制造企业面临"既懂工业又懂数字技术"的复合型人才短缺问题,在施耐德电气与某高职院校的合作项目中,学生需要同时学习机械原理、Python编程、TensorFlow框架和工业通信协议,培养周期长达3年。
绿色建筑与环境信息披露热度持续上升,相关产业迎来新发展 这种人才困境正在催生新的职业形态,在西门子安贝格工厂,出现了一个新岗位——"数字孪生工程师",其职责包括数据采集方案设计、模型训练与优化、以及与生产部门的跨部门协作,这个岗位的年薪中位数达到9.8万欧元,比传统自动化工程师高出40%。
未来已来,只是分布不均
站在2026年的时间节点回望,数字孪生已经走过"概念验证"阶段,进入规模化应用期,但行业分化日益明显:领先企业通过深度学习等技术实现价值跃迁,而落后者仍在为数据质量等基础问题挣扎。
GE数字集团总裁Bill Ruh的判断颇具前瞻性:"到2028年,所有排名前500的制造企业都将部署数字孪生,但只有20%能真正发挥其价值,区别不在于技术本身,而在于企业是否具备将物理世界与数字世界深度融合的组织能力。"
在深圳某3C电子工厂,我们看到了这种融合的雏形,当数字孪生系统发现某条SMT贴片线的效率下降时,它不仅会通知工程师,还会自动调整相邻生产线的物料配送计划,甚至触发供应商的备货提醒,这种端到端的优化,正是数字孪生从"工具"升级为"生态系统"的标志。
工业革命的历史