在2026年的工业领域,"数字孪生"早已不是新鲜概念,但不同企业实施效果的天差地别,却让这个技术方案呈现出明显的两极分化现象,有的工厂通过数字孪生实现了设备故障预测准确率提升40%、生产效率提高25%的突破,而另一些企业投入数百万后,系统却沦为"可视化看板",连基础的数据同步都频繁出错,这种差异背后,分类算法的选择与应用逻辑,正在成为决定数字孪生成败的关键变量。
分类算法:数字孪生的"隐形决策者"
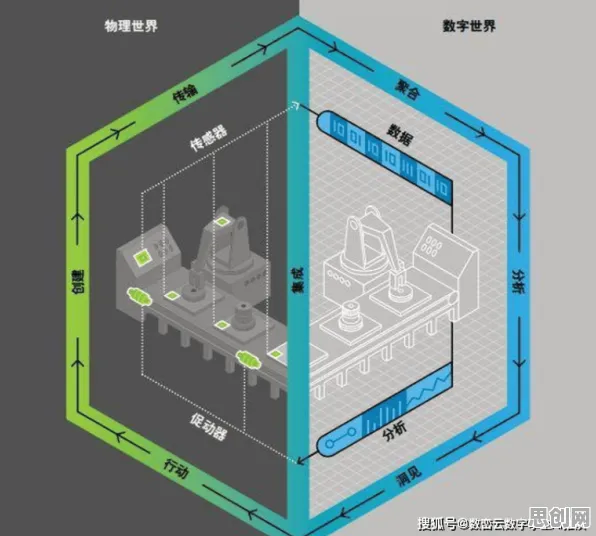
数字孪生的核心是通过物理实体与虚拟模型的实时交互,实现预测性维护、工艺优化等价值,但鲜为人知的是,从设备传感器采集的原始数据到最终决策指令,中间需要经历"数据清洗-特征提取-模式识别-决策输出"的完整链条,而分类算法正是这个链条中承担"模式识别"的核心模块。 机构养老热度持续上升,相关产业迎来新发展
以某汽车零部件厂商2026年的实践为例,其冲压车间部署的数字孪生系统,需要从2000多个传感器中实时分析压力、温度、振动等10余类数据,最初采用的传统阈值分类算法,只能识别"超过设定值"的简单异常,导致漏检率高达35%,后来改用基于XGBoost的集成学习算法,通过构建多维度特征交叉模型,成功将故障识别准确率提升至92%,这个案例揭示了一个关键事实:分类算法的选择直接影响数字孪生对物理世界状态的感知精度。
更复杂的场景出现在流程工业,某石化企业2026年升级的数字孪生平台,需要处理反应釜内温度、压力、成分浓度等连续变量与设备开关状态等离散变量的混合数据,传统分类算法难以处理这种异构数据,而采用图神经网络(GNN)后,系统通过构建设备关联图谱,不仅能识别单个设备的异常,还能预测级联故障风险,该企业负责人透露:"新算法上线后,我们成功避免了一次价值超千万元的连锁停机事故。" 国家公园与碳排放及绿色应急响应热度持续攀升,相关应用不断深化
算法选择背后的技术路线之争
当前工业数字孪生领域,分类算法的应用呈现出明显的流派分化,以西门子、PTC为代表的国际巨头,倾向于采用基于物理模型的混合算法,将第一性原理与数据驱动方法结合,2026年西门子发布的MindSphere 4.0平台,其核心分类模块就集成了热力学方程与LSTM神经网络,在某航空发动机企业的测试中,对叶片裂纹的预测时间比纯数据模型提前了18个周期。
国内企业则更偏好纯数据驱动路线,华为云2026年推出的工业数字孪生服务,基于盘古大模型开发了专用分类算法库,包含从传统逻辑回归到Transformer架构的20余种算法,某光伏企业应用后,将硅片分选环节的良品率从92%提升至97.5%,算法负责人解释:"我们通过迁移学习,用少量标注数据就微调出了适配光伏工艺的专用模型。"
这种路线差异在算法性能上体现得尤为明显,在2026年工业互联网产业联盟组织的测试中,面对同一组风电设备振动数据,物理混合模型在早期故障识别上表现优异(召回率91%),但需要专家手动调整参数;而数据驱动模型(如随机森林)虽然召回率稍低(85%),但能自动适应不同机型的数据特征,某风电集团CTO的评价很具代表性:"我们最终选择了混合方案,因为对关键设备而言,0.1%的漏检都可能造成灾难性后果。"
数据质量:算法发挥的"隐形天花板"
算法再先进,也需要高质量数据支撑,2026年某钢铁企业的教训极具代表性:其投入500万元建设的数字孪生系统,上线半年后预测准确率始终徘徊在60%左右,经诊断发现,问题出在数据源头——高炉温度传感器存在3%的测量误差,且不同批次传感器的校准曲线不一致,这种"脏数据"导致分类算法学习到的是错误模式,最终不得不重新部署传感器网络并重建数据中台。
数据标注的缺失是另一大障碍,某半导体企业2026年尝试用数字孪生优化光刻工艺,但因缺乏缺陷样本的标注数据,其训练的CNN模型在真实生产中频繁误报,后来采用主动学习策略,让模型自动筛选高价值样本交由专家标注,仅用20%的标注量就达到了同等精度,该企业AI团队负责人感慨:"工业场景的数据标注成本是消费领域的10倍以上,必须找到成本与效果的平衡点。"

数据时效性同样关键,在某快递分拨中心的测试中,基于静态数据训练的分类模型,对双十一期间包裹量突增的预测误差高达40%,而改用在线学习算法后,模型能每15分钟更新一次参数,将预测误差控制在5%以内,这种动态适应能力,正是数字孪生从"展示系统"升级为"决策系统"的关键。
行业特性:算法落地的"定制化需求"
不同工业场景对分类算法的要求存在本质差异,在离散制造领域,某家电企业2026年部署的数字孪生系统,需要同时处理结构化数据(如设备运行参数)和非结构化数据(如维修工单文本),其采用的BERT+XGBoost混合模型,既能从文本中提取故障描述特征,又能结合数值数据进行分类,使故障处理时间缩短了35%。
流程工业的挑战则在于数据的高维度与强耦合,某化工企业2026年升级的数字孪生平台,其反应釜数据包含温度、压力、流量等20余个变量,且存在明显的时序依赖关系,传统分类算法难以处理这种复杂关系,而采用时序图卷积网络(T-GCN)后,系统能自动学习变量间的动态关联,将产品质量波动预测准确率提升至89%。
2026年生态补偿与可持续时尚热度持续攀升,相关产业迎来新机遇 甚至同一行业的不同环节,算法需求也大不相同,在某汽车工厂的焊装车间,机器人焊接质量检测需要毫秒级响应,因此采用轻量级的MobileNet分类模型;而在涂装车间,颜色缺陷检测对精度要求极高,则部署了参数量更大的ResNet模型,这种"场景化算法选型",正在成为工业数字孪生的标配实践。
人才缺口:算法落地的"最后一公里"
算法再先进,也需要懂工业的人来落地,2026年某制造企业的调研显示,63%的数字孪生项目延期或超支,根源都在于团队缺乏"工业+AI"的复合能力,某项目负责人吐槽:"我们招的算法工程师不懂PLC编程,工业工程师又看不懂Python代码,最后只能靠外包团队勉强交付。"

2026年绿色森林保护与植物保护及可持续发展热度持续攀升,相关领域迎来新突破 这种人才断层在算法调优阶段尤为明显,某能源企业2026年部署的燃气轮机数字孪生系统,初始模型在测试集上表现良好,但上线后频繁误报,后来发现是训练数据中正常样本占比过高(95%),导致模型对异常不敏感,调整数据分布并引入Focal Loss损失函数后,问题才得到解决,但这个过程消耗了3个月时间,直接成本超百万元。
企业正在探索破解之道,某工程机械巨头2026年与高校合作开设"数字孪生工程师"培养项目,课程涵盖机械原理、控制理论、机器学习等多学科知识;另一家企业则建立"算法工程师驻场制度",要求AI团队必须深入车间理解工艺流程,这些实践表明,数字孪生的成功,最终取决于企业能否培养出既懂工业逻辑又掌握AI技术的"翻译者"。
未来趋势:算法与工业的深度融合
站在2026年的时间节点观察,工业数字孪生领域的分类算法正在呈现三大趋势:一是从通用模型向专用模型演进,如针对风电齿轮箱、半导体光刻机等特定设备开发的行业大模型;二是从单模态向多模态融合,结合振动、声音、视觉等多源数据进行分类;三是从静态建模向动态学习升级,通过在线学习、强化学习等技术实现模型的自我进化。
某航空制造企业的实践颇具前瞻性,其2026年上线的数字孪生系统,采用联邦学习架构,在保护数据隐私的前提下,联合多家供应商训练通用分类模型,再针对具体机型进行微调,这种模式既解决了数据孤岛问题,又降低了模型开发成本,据测算可使新机型数字孪生的部署周期缩短60%。
更值得关注的是算法与工业知识的深度结合,某机床企业2026年发布的数字孪生平台,将切削力学模型嵌入分类算法,使系统不仅能识别刀具磨损,还能预测加工表面粗糙度,这种"物理约束+数据驱动"的方法,正在成为高端装备领域的新标准。
2026年中学教育与循环利用热度持续走高,行业关注度持续提升 当我们在2026年回望数字孪生的发展历程,会发现分类算法的选择早已超越技术范畴,成为企业工业知识沉淀