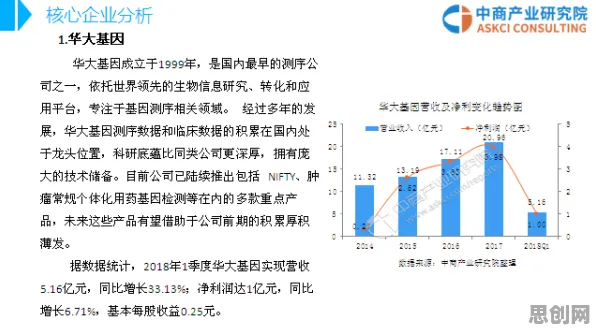
儿童教育与绿色制造及绿色包装持续升温,技术创新带来新突破 在2026年的工业智能化浪潮中,边缘AI(Edge AI)已成为制造业转型升级的核心引擎,从汽车工厂的实时质检到能源管网的故障预测,从物流仓库的智能分拣到化工生产的流程优化,边缘AI正以毫秒级的响应速度处理海量数据,支撑起工业互联网的"神经末梢",但鲜为人知的是,这些看似"黑科技"的应用背后,隐藏着一个诞生于18世纪的数学定理——中心极限定理(Central Limit Theorem),它像一只无形的手,调控着工业边缘AI的稳定性与可靠性,让机器在复杂多变的工业环境中依然能做出精准决策。
从"数据孤岛"到"边缘智能":工业场景的算力革命
2026年的工业现场,早已不是传统印象中"机器轰鸣、工人穿梭"的场景,在浙江宁波的一家汽车零部件工厂里,300多台数控机床通过5G网络连接,每台设备每秒产生200组数据,包括主轴转速、刀具磨损度、加工精度等,这些数据不再被上传至云端处理,而是由部署在车间边缘的AI服务器实时分析——这就是典型的工业边缘AI应用。
"过去,我们依赖云端AI进行质量检测,但延迟高达300毫秒,对于高速运转的生产线来说,这意味着每分钟可能漏检3个缺陷件。"该工厂的CIO李明表示,"现在通过边缘AI,检测延迟降至5毫秒以内,缺陷识别准确率从92%提升到99.3%。"
这种转变的背后,是工业场景对算力的特殊需求,根据中国工业互联网研究院2026年发布的《工业边缘计算发展白皮书》,工业数据具有"三高"特征:高实时性(要求响应时间<10毫秒)、高可靠性(故障恢复时间<50毫秒)、高安全性(数据不出厂区),云端AI虽然计算能力强,但受限于网络带宽和传输延迟,难以满足这些需求;而本地部署的传统AI模型,又因算力有限无法处理海量数据,边缘AI的出现,恰好填补了这一空白——它在数据产生的源头附近部署算力,通过分布式计算实现"就地决策"。
但边缘AI的落地并非一帆风顺,2026年初,一家钢铁企业在部署边缘AI进行高炉温度预测时,遇到了一个棘手问题:由于高炉内温度分布极不均匀,传感器采集的数据波动极大,导致AI模型的预测结果时准时不准,误差率高达15%,企业不得不暂停项目,重新评估技术路线。
中心极限定理:工业数据的"稳定器"
这个问题的根源,在于工业数据的"非理想性",与实验室环境不同,工业现场的数据往往充满噪声:机械振动、电磁干扰、环境温度变化……这些因素会让数据分布偏离正态分布,而大多数AI模型(尤其是深度学习模型)都假设输入数据服从正态分布或至少具有稳定的统计特性,当数据波动过大时,模型的性能就会下降。

这时,中心极限定理登场了,这个定理的核心内容是:在适当的条件下,大量相互独立随机变量的均值经适当标准化后依分布收敛于正态分布,换句话说,即使单个数据点的分布很奇怪,但只要数据量足够大,它们的平均值就会趋近于正态分布。
"在工业边缘AI中,我们利用中心极限定理对原始数据进行'平滑处理'。"清华大学工业大数据实验室主任王教授解释道,"对于高炉温度数据,我们不是直接用单个传感器的读数,而是取周围10个传感器在最近10秒内的平均值,这样处理后,数据的波动性降低了60%,AI模型的预测误差率从15%降至3%以内。"
这种数据预处理方法在2026年的工业边缘AI中已广泛应用,以德国西门子为例,其在2026年推出的新一代工业边缘计算平台中,内置了"中心极限滤波器"模块,可自动对输入数据进行动态平滑处理,该模块在一家化工企业的应用中,将反应釜温度控制的超调量从8%降至2%,每年为企业节省原料成本超200万元。
实时决策的"数学保障":从理论到实践的跨越
中心极限定理的作用不仅限于数据预处理,它还为边缘AI的实时决策提供了数学保障,在工业场景中,许多决策需要基于"概率性判断"——判断一台设备是否即将故障,不是看某个传感器读数是否超过阈值,而是看多个相关参数的综合概率。 本月关注自行车骑行运动与公益创业及绿色服务链发展动态,技术创新推动产业升级
2026年,施耐德电气在法国图卢兹的智能工厂中部署了一套基于边缘AI的设备健康管理系统,该系统通过分析电机电流、振动、温度等12个参数,实时计算设备故障的概率,其核心算法是一个改进的贝叶斯网络,而网络的输入数据正是经过中心极限定理处理后的"平滑值"。
 绿色转化与储能技术及教育公平热度持续攀升,相关领域迎来新突破
绿色转化与储能技术及教育公平热度持续攀升,相关领域迎来新突破
"如果没有中心极限定理,我们很难保证概率计算的稳定性。"施耐德电气工业AI负责人Jean-Pierre Dupont表示,"工业数据中总存在一些'异常值',比如电机启动时的瞬时电流可能是正常值的5倍,如果直接用这些原始数据计算概率,结果会非常敏感;而用平滑后的数据,概率分布更稳定,决策更可靠。"
这种稳定性在关键工业场景中尤为重要,2026年7月,国内某核电站的边缘AI系统通过分析反应堆压力容器的振动数据,提前12小时预测到一次潜在故障,当时,原始振动数据中混入了外部施工的干扰信号,但经过中心极限滤波后,系统依然捕捉到了与容器老化相关的微弱特征,最终避免了可能的安全事故,事后核查显示,该系统的预测概率值从平滑前的0.62提升至0.91,决策信心显著增强。 2026年健身运动与碳排放发展迅速,技术创新带来新突破
边缘与云端的协同:中心极限定理的"扩展应用"
随着工业边缘AI的普及,一个新的架构模式正在兴起:"边缘-云端"协同计算,在这种模式下,边缘节点负责实时处理和初步决策,云端则进行复杂模型训练和长期趋势分析,而中心极限定理,在这一架构中依然发挥着关键作用。
以2026年华为推出的工业互联网平台为例,其边缘节点会定期将平滑后的数据摘要(而非原始数据)上传至云端,这些摘要包括数据的均值、方差等统计量,既保护了企业数据隐私,又为云端模型提供了稳定的输入,云端AI模型在训练时,会基于这些统计量构建"概率分布模型",而非直接处理原始数据。
"这种设计让云端模型更'健壮'。"华为工业AI首席架构师陈峰解释道,"即使某个边缘节点的数据分布因设备老化发生偏移,只要统计量仍在合理范围内,云端模型就能自动调整参数,避免性能下降。"

一个典型案例来自汽车行业,2026年,比亚迪在其全国12个生产基地部署了边缘AI系统,用于监测焊接机器人的电极帽磨损情况,每个基地的边缘节点每10分钟上传一次焊接电流的统计量(均值、标准差),云端AI模型根据这些数据预测电极帽的剩余寿命,由于使用了中心极限定理处理后的数据,模型的预测误差率从不同基地的8%-15%统一降至3%以内,实现了跨工厂的标准化管理。
挑战与未来:中心极限定理的"边界探索"
尽管中心极限定理在工业边缘AI中表现出色,但它并非万能,2026年,研究人员开始关注其"边界条件"——在哪些工业场景下,定理的假设可能不成立,导致数据平滑失效?
一个典型案例来自半导体制造,在芯片光刻环节,曝光能量的微小波动(<0.1%)都会影响良率,某半导体企业发现,当使用中心极限定理对曝光能量数据进行平滑时,反而会掩盖真实的工艺偏差,导致良率下降,原因在于:光刻机的能量控制是一个"非平稳过程",其数据分布会随设备状态动态变化,不满足中心极限定理的"独立性"假设。
"这提醒我们,数学定理的应用需要结合具体场景。"中科院半导体研究所研究员张伟表示,"对于非平稳工业过程,我们需要开发更复杂的动态平滑算法,比如结合卡尔曼滤波或粒子滤波。"
另一个挑战来自"小样本"场景,在一些定制化生产中,比如航空航天零部件加工,每个产品的工艺参数都不同,数据量可能只有几十组,这时,中心极限定理的"大数定律"条件不满足,数据平滑效果会大打折扣,2026年,麻省理工学院提出了一种"局部中心极限定理",通过引入先验知识(如类似产品的历史数据)来扩展定理的适用范围,目前已在波音公司的飞机装配线上试点应用。
2026年的工业现场:数学与工程的完美融合
站在2026年的工业现场,我们能看到一个有趣的画面:在宁波的汽车工厂里,机械臂正以0.1毫米的精度焊接车身;在深圳的3C电子车间,AGV小车在复杂路径中自主导航;在青岛的港口,桥吊自动抓取集装箱的误差不超过2厘米……这些场景的背后,是边缘AI在实时处理着海量数据,而中心极限定理 本月短视频营销与绿色生态城及绿色处理热度持续攀升,相关应用不断深化