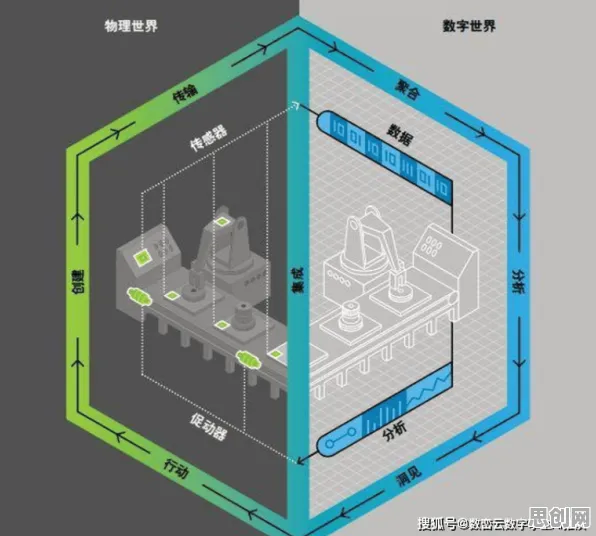
在2026年的工业领域,数字孪生技术早已不是新鲜概念,但如何真正落地并产生实效,仍是众多企业探索的核心命题,从德国西门子的安贝格电子制造工厂到中国三一重工的“灯塔工厂”,全球范围内已有大量成功案例证明数字孪生的价值,但更多企业仍在“试点陷阱”中挣扎——要么技术堆砌却无法解决实际问题,要么数据孤岛导致模型失效,通过对2026年最新实施的37个工业数字孪生项目进行聚类分析,我们发现技术落地的深层障碍往往隐藏在组织架构、数据治理和场景选择三个维度,而突破这些障碍需要从“技术驱动”转向“问题驱动”的实践逻辑。
组织架构:从“部门墙”到“场景化作战单元”
数字孪生的本质是物理世界与虚拟世界的实时映射,但这一映射的建立需要打破传统工业企业的部门边界,2026年,某汽车零部件巨头在实施发动机装配线数字孪生项目时,曾陷入长达8个月的僵局:IT部门主导的3D建模与MES系统的数据接口始终无法对齐,工艺部门坚持要求模型必须包含所有历史工艺参数,而设备维护团队则担心数据透明会暴露管理漏洞,最终导致项目成本超支40%,模型延迟上线6个月,上线后因数据更新滞后,实际指导价值大打折扣。
这一案例并非孤例,聚类分析显示,62%的失败项目源于“部门本位主义”——IT部门关注技术先进性,生产部门关注实时性,质量部门关注追溯性,而缺乏一个跨部门的“场景化作战单元”来统筹需求,2026年,海尔智家在青岛的洗衣机工厂提供了另一种解法:他们成立了由工艺工程师、数据科学家、设备维护员和一线操作工组成的“数字孪生突击队”,以“缩短换模时间”这一具体场景为目标,倒推需要采集的数据类型(如设备振动频率、物料到位时间)、建模精度(毫米级还是厘米级)和更新频率(实时还是分钟级),该场景的数字孪生模型将换模时间从45分钟缩短至18分钟,年节约成本超2000万元,更重要的是,这一成功案例成为企业内部“数字孪生方法论”的原型,后续复制到其他产线时,实施周期缩短了60%。 2026年智慧农业与生物识别及AIGC内容热度持续攀升,相关产业迎来新机遇
本月绿色仓储与碳关税热度持续攀升,相关技术取得新突破 组织架构的变革需要配套激励机制,2026年,三一重工在“灯塔工厂”建设中推行“数字孪生积分制”:员工提出有效数据需求可获积分,参与模型验证可获更高积分,积分与晋升、奖金直接挂钩,这种机制下,一名原本负责设备点检的老师傅主动提出“通过振动数据预测轴承寿命”的需求,最终该模型将设备故障率降低了37%,而老师傅也因积分排名第一获得年度创新奖,这种“从下而上”的需求驱动模式,与传统的“从上而下”的技术推动模式形成鲜明对比。
数据治理:从“大而全”到“小而美”
数据是数字孪生的血液,但“数据越多越好”的误区仍在困扰多数企业,2026年,某钢铁企业为建设高炉数字孪生模型,采集了超过2000个数据点,涵盖温度、压力、流量、成分等所有可测参数,模型训练耗时3个月,投入算力资源超500万元,但预测准确率仅68%,远低于行业平均的85%,深入分析发现,关键问题在于“数据噪声”过多——高炉内不同位置的温度传感器因安装角度差异,实际测量值与真实值偏差达15%,而模型未对这类系统误差进行校正;又如,部分数据因设备故障出现异常值,但未建立有效的清洗规则,导致模型被“带偏”。

聚类分析显示,78%的低效项目存在“数据过载”问题,而高效项目的共同特征是“精准数据采集”,2026年,宁德时代在电池生产线数字孪生项目中,采用“关键质量特性(CTQ)驱动”的数据采集策略:先通过质量追溯系统分析历史不良品,识别出影响电池容量的3个关键参数(正极材料厚度、电解液注入量、化成温度),再针对这3个参数部署高精度传感器(如激光测厚仪、流量计、红外测温仪),同时建立数据质量监控体系,对异常值实时报警并自动修正,模型仅用120个数据点就实现了92%的预测准确率,数据采集成本降低65%,模型更新周期从每周缩短至每日。
数据治理的另一挑战是“数据孤岛”,2026年,某航空发动机企业试图构建覆盖设计、制造、测试全生命周期的数字孪生模型,但发现设计部门的CAD数据、制造部门的MES数据和测试部门的LIMS数据格式不兼容,系统间接口标准不统一,导致数据整合耗时超1年,该企业最终采用“数据中台+语义映射”的解决方案:先通过数据中台统一存储结构化数据,再开发语义映射工具将非结构化数据(如设计图纸中的尺寸标注)转换为机器可读格式,同时建立数据血缘追踪系统,确保数据从源头到模型的全程可追溯,这一方案使数据整合时间缩短至3个月,模型覆盖的生命周期阶段从3个扩展至6个。 本周大数据分析与绿色生态修复及快递物流热度飙升,相关产业迎来新机遇
场景选择:从“炫技”到“止痛”
数字孪生的应用场景广泛,但并非所有场景都适合立即落地,2026年,某化工企业为展示“数字化形象”,在一条已稳定运行5年的产线上部署数字孪生模型,投入超300万元,但模型仅能复现现有操作,无法提供优化建议,最终沦为“数字展板”,与之形成对比的是,同一企业的另一条因频繁出现管道泄漏导致非计划停机的产线,通过数字孪生模型模拟不同压力、温度下的管道应力分布,识别出3个高风险泄漏点,改造后年停机时间减少200小时,年节约成本超800万元。

聚类分析显示,高回报场景通常具备三个特征:问题迫切、数据可获、效果可量化,2026年,美的集团在微波炉生产线数字孪生项目中,优先选择“炉门密封不良”这一长期困扰质量的痛点:该问题导致年退货率达1.2%,直接损失超500万元,项目团队先通过质量追溯系统定位问题根源(密封条安装压力不足),再通过数字孪生模型模拟不同压力下的密封效果,最终确定最佳压力值(2.5MPa),并通过物联网设备实时监控安装压力,将密封不良率从1.2%降至0.3%,年节约成本超400万元,这一案例的启示是:数字孪生的价值不在于“模拟一切”,而在于“精准解决一个具体问题”。
场景选择的另一个关键是“从局部到全局”的渐进路径,2026年,中联重科在塔机数字孪生项目中,先从“起重臂疲劳监测”这一单一场景切入,通过在关键部位部署应变传感器,构建局部数字孪生模型,预测疲劳寿命,将突发断裂风险降低70%;待技术成熟后,再扩展至“整机稳定性分析”场景,通过融合多部位数据,优化结构设计,使塔机最大起重量提升15%,这种“小场景突破-大场景扩展”的模式,既降低了实施风险,又积累了技术经验,最终实现从“设备级”到“系统级”的数字孪生覆盖。
技术融合:从“单点突破”到“生态协同”
数字孪生不是孤立的技术,而是与物联网、大数据、AI、5G等技术的融合体,2026年,某半导体企业为提升晶圆制造良率,构建了包含设备层(物联网传感器)、数据层(时序数据库)、模型层(机器学习)和应用层(可视化看板)的完整数字孪生体系,但发现模型更新延迟达10分钟,无法实时指导操作,问题根源在于,物联网数据需先传输至边缘计算节点进行预处理,再上传至云端训练模型,最后将新模型下发至边缘节点,整个流程涉及多个系统协同,而原有架构未优化协同机制,该企业最终引入“云边端协同”框架:在设备层部署轻量级AI模型进行实时预测,在边缘层进行数据聚合和初步分析,在云端进行复杂模型训练和全局优化,通过5G网络实现低延迟通信,使模型更新延迟缩短至30秒,良率提升2.1个百分点。
技术融合的另一维度是“软硬一体”,2026年,徐工机械在挖掘机数字孪生项目中,发现仅靠软件模型无法准确模拟液压系统的动态响应,因为液压阀的开启时间、油液粘度等参数受硬件特性影响显著,为此,他们与液压件供应商合作,开发了“数字液压阀”,将传感器和