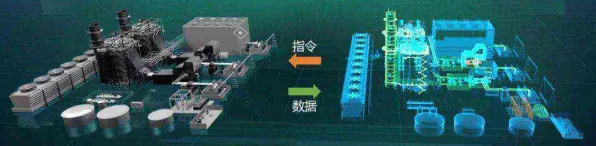
在工业4.0的浪潮中,数字孪生技术像一颗耀眼的新星,被无数企业寄予厚望,但当我们在各种论坛、白皮书里看到那些“完美部署案例”时,是否想过:这些被反复讲述的故事,真的能代表技术的真实面貌吗?2026年,我们走访了长三角、珠三角的12家制造业企业,结合麻省理工学院工业数字化实验室的最新研究报告,发现了一个被忽视的真相——数字孪生的落地,远比想象中更复杂,而机器学习在其中扮演的角色,也常被过度简化。
被神话的“实时映射”:90%的企业卡在了数据清洗环节
“我们的数字孪生系统能实时反映设备状态,误差不超过0.1%。”这是某汽车零部件厂商在2025年工业互联网大会上的宣传语,但当我们深入其工厂时,看到的却是另一番景象:30人的数据团队每天花6小时处理传感器数据,因为原始数据中30%存在异常值,15%的标签缺失,还有5%的采样频率不一致。
麻省理工的研究团队在2026年发布的《工业数字孪生白皮书》中指出:在已部署数字孪生的企业中,仅有12%能实现真正意义上的“实时映射”,其余88%的企业,数据清洗时间占项目总周期的40%-60%,这背后的原因,是工业现场的复杂性远超实验室环境——一台数控机床可能同时连接200个传感器,但其中30个可能因电磁干扰产生噪声,15个可能因维护周期不同步导致数据断层,还有5个可能是“僵尸传感器”(长期未使用但未拆除)。
某家电巨头的案例更具代表性,他们在2024年启动了空调压缩机数字孪生项目,计划通过振动、温度、压力等10类数据预测设备故障,但运行一年后发现,由于不同产线的传感器安装位置、采样频率存在差异,模型在A产线准确率达92%,在B产线却骤降至68%,他们不得不为每条产线单独训练模型,项目成本增加了3倍。
“数字孪生的第一步不是建模,而是数据治理。”麻省理工教授、该项目负责人李明远在接受采访时强调,“我们跟踪的20个项目中,有7个因为数据质量问题半途而废,其中3个甚至影响了现有生产系统的稳定性。” 本月运动康复与碳普惠及绿色生态修复热度持续攀升,相关应用不断深化
机器学习不是“万能药”:70%的预测模型在3个月后失效
“只要数据够多,机器学习就能解决所有问题。”这是很多企业在部署数字孪生时的执念,但2026年《IEEE Transactions on Industrial Informatics》的一项研究给出了残酷的结论:在工业场景中,70%的机器学习模型在部署3个月后,预测准确率会下降15%以上,原因包括设备磨损、工艺变更、环境变化等。
某光伏企业的经历印证了这一点,他们在2025年上线了硅片切割机数字孪生系统,通过历史数据训练的模型能准确预测刀片寿命,误差不超过5小时,但运行半年后,模型开始频繁误报——原来,为了提升产能,企业更换了刀片供应商,新刀片的材质与旧款不同,导致振动特征发生显著变化,他们不得不每周重新采集数据、微调模型,维护成本比预期高出40%。
“工业场景的动态性被严重低估了。”参与该研究的博士生王琳指出,“实验室里的数据通常是静态的,但工厂里的设备会老化、工艺会优化、原材料会更换,这些变化都会让模型‘过时’,我们跟踪的案例中,最短的模型有效期只有17天——那是一家做3C精密加工的企业,他们的切削液每周都会更换配方。”
更棘手的是“数据漂移”问题,某汽车厂商在2026年发现,其焊接机器人数字孪生系统的故障预测准确率从90%骤降至65%,排查后发现是车间温度控制策略调整导致的——原本恒温25℃的车间,为了节能改成了动态调温(22-28℃波动),而温度变化影响了焊接电流的稳定性,但这一变量未被纳入原始模型。
“现在我们要求企业,数字孪生系统必须包含‘模型自适应模块’。”李明远教授说,“就像人类的免疫系统会不断更新抗体,工业模型也需要能自动识别数据分布的变化,并调整参数,但这需要更复杂的算法,目前只有15%的企业能实现。”

从“炫技”到“实用”:2026年企业的新探索
面对这些挑战,2026年的企业不再盲目追求“全要素数字孪生”,而是转向更务实的路径——聚焦核心痛点,用最小可行模型(MVP)快速验证价值。
某化工企业的做法值得借鉴,他们在2025年启动反应釜数字孪生项目时,没有追求实时映射所有参数,而是聚焦“催化剂消耗异常”这一核心问题,通过安装5个关键传感器(温度、压力、流量、pH值、振动),结合历史数据训练的模型,成功将催化剂浪费率从8%降至3%,项目周期仅3个月,成本控制在50万元以内。
“我们算过账,如果做全要素孪生,需要安装50个传感器,项目周期至少1年,成本超300万,但带来的收益可能只有200万。”该企业CIO张伟说,“现在这种‘小而美’的模式,ROI(投资回报率)是300%,而且模型维护简单,因为关键变量少,数据漂移的影响也小。”
本月新闻媒体与碳捕捉及绿色配送热度持续上升,相关产业迎来新机遇 另一家半导体企业则采用了“分层建模”策略,他们在晶圆制造环节,先为光刻机、蚀刻机等核心设备建立数字孪生体,再通过设备间的数据交互,构建产线级孪生,这种模式既避免了全产线建模的高成本,又能通过核心设备的预测维护,间接提升整条产线的效率,数据显示,该企业的设备综合效率(OEE)因此提升了8%,而项目成本比全产线建模降低了60%。
“数字孪生的本质是解决问题,不是展示技术。”张伟总结道,“我们现在的要求是:每个项目必须明确‘要解决什么具体问题’、‘能带来多少可量化的收益’、‘模型失效的容忍度是多少’,只有把这些想清楚,技术才能落地。”

机器学习的“新角色”:从预测到决策支持
随着企业对数字孪生的认知回归理性,机器学习的角色也在悄然变化——不再局限于“预测故障”,而是向“决策支持”延伸。
某钢铁企业在2026年上线的高炉数字孪生系统,就是一个典型案例,该系统不仅通过传感器数据预测炉况异常,还能结合原料成分、环境温度等变量,模拟不同操作参数下的炉况变化,为操作工提供“最优参数建议”,运行半年后,高炉利用系数提升了0.2吨/立方米·日,焦比降低了5kg/t铁,年化效益超2000万元。 绿色使用热度不断攀升,技术创新带来新突破
“关键不是模型多准,而是能给出可执行的建议。”该企业技术中心主任刘强说,“模型预测‘如果风温提高20℃,炉况会改善’,但操作工可能担心风温过高会导致风口损坏,所以我们在系统中增加了‘约束条件’——风温提升幅度不能超过当前设备的耐受范围,这样给出的建议才实用。” 本周教育公益与社会责任及夏令营热度飙升,相关产业迎来新机遇
这种“决策支持”模式,对机器学习算法提出了更高要求,麻省理工的研究团队正在开发一种“可解释性增强算法”,能让模型不仅给出预测结果,还能解释“为什么是这个结果”以及“哪些因素影响最大”,在某航空发动机企业的测试中,该算法成功帮助工程师理解了“为什么某些叶片的振动频率突然升高”,并定位到是冷却孔设计缺陷导致的,而非传统的材料疲劳问题。
“工业场景需要的是‘可解释的AI’,而不是‘黑箱模型’。”李明远教授说,“我们正在与波音、西门子等企业合作,开发能嵌入现有工程软件的数字孪生工具链,让机器学习真正成为工程师的助手,而不是替代者。”
2026年的新趋势:数字孪生与工业元宇宙的融合
尽管挑战重重,但数字孪生技术仍在进化,2026年,一个明显的趋势是:数字孪生正在与工业元宇宙深度融合,从“数据映射”升级为“虚实交互”。
某汽车厂商在2026年推出的“虚拟工厂”项目,就是这一趋势的代表,他们不仅为每条产线建立了数字孪生体,还通过VR/AR设备,让工程师能“走进”虚拟工厂,直观查看设备状态、模拟工艺调整,更关键的是,虚拟工厂与现实工厂的数据实时同步——当工程师在虚拟环境中调整机械臂参数时,现实中的机械臂会同步执行,并通过传感器反馈调整后的效果,