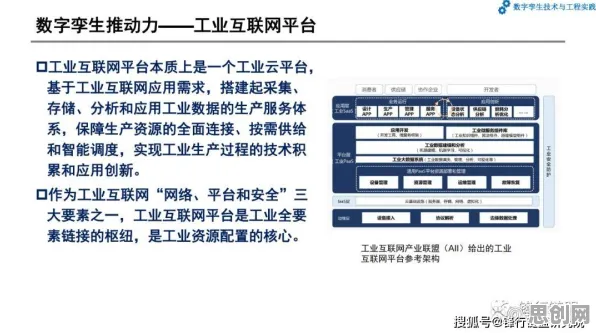
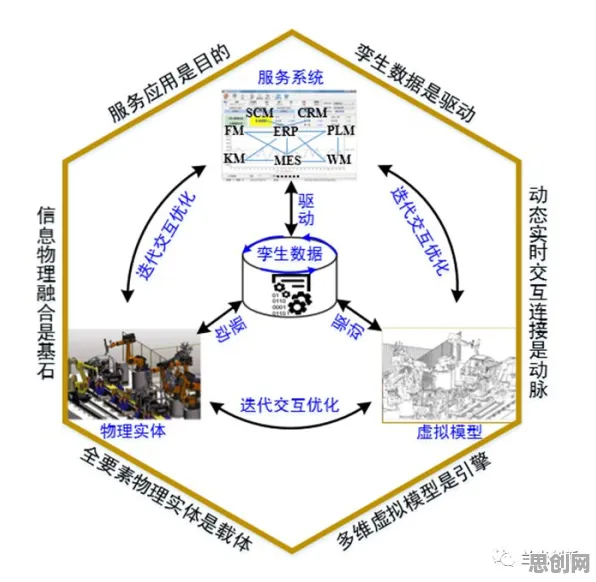
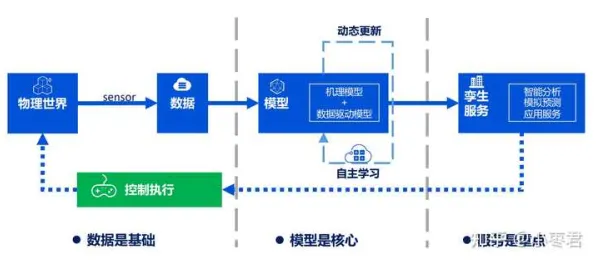
在2026年的工业领域,数字孪生技术已从概念验证阶段迈向规模化应用,成为推动智能制造的核心引擎,但当企业真正将数字孪生落地时,一个关键问题浮出水面:如何让虚拟模型与物理实体实现"毫秒级"同步?如何从海量数据中提取有效信息,驱动决策优化?答案藏在大数据分析的深度应用中——它不仅是数字孪生的"数据大脑",更是揭示智能本质的关键钥匙。
数字孪生的"数据困境":从概念到落地的最后一公里
2026年3月,某汽车制造企业的数字孪生项目陷入僵局,他们为一条冲压生产线构建了虚拟模型,理论上能实时映射设备状态、预测故障,但实际运行中,模型响应延迟高达3秒,故障预测准确率不足60%,问题出在数据层面:生产线每秒产生200MB的传感器数据,但其中80%是噪声;设备历史故障记录分散在12个系统中,格式不统一;更关键的是,传统分析方法只能处理结构化数据,而设备振动、温度曲线等时序数据蕴含的关键特征被忽略。
这并非个例,根据中国工业互联网研究院2026年发布的《数字孪生应用白皮书》,在已部署数字孪生的企业中,63%面临"数据孤岛"问题,51%抱怨"数据价值密度低",42%因"实时处理能力不足"导致模型失效,这些数据困境背后,是工业场景对大数据分析的特殊需求:既要处理PB级的多源异构数据,又要实现毫秒级的实时响应;既要挖掘历史数据的潜在规律,又要捕捉实时数据的动态变化。
大数据分析的"破局之道":从数据清洗到特征工程的完整链路
在2026年的实践中,领先企业已形成一套成熟的大数据分析方法论,以某钢铁企业的高炉数字孪生项目为例:
第一步:数据治理——打破"数据孤岛"
该企业的高炉运行数据分散在DCS(分布式控制系统)、MES(制造执行系统)、设备管理系统等5个系统中,数据格式包括关系型数据库、CSV文件、API接口等,他们采用"数据湖+数据中台"架构,将所有数据统一存储在Hadoop数据湖中,通过Apache NiFi进行数据清洗和转换,再通过数据中台提供标准化接口,这一步让数据可用率从40%提升至90%,数据准备时间从3天缩短至2小时。
第二步:实时处理——构建"数字神经"
高炉内部温度、压力等参数每秒变化数十次,传统批处理模式根本无法捕捉,企业引入Apache Flink流处理框架,搭建实时数据管道:传感器数据直接流入Kafka消息队列,Flink集群在内存中完成数据过滤、聚合和初步分析,再将结果写入时序数据库(如InfluxDB),这一架构使数据延迟从秒级降至毫秒级,为数字孪生的实时映射提供了基础。
第三步:特征工程——提取"数据基因"
原始数据只是"数字原料",真正有价值的是隐藏其中的特征,以设备振动数据为例,企业采用时频分析方法(如短时傅里叶变换),将一维振动信号转换为二维时频图,再通过卷积神经网络(CNN)自动提取特征,这种方法比传统时域特征(如均值、方差)的故障识别准确率高30%,更关键的是,他们构建了"特征超市",将通用特征(如设备负载率)和领域特征(如高炉透气性指数)分类存储,供不同场景复用。

第四步:模型优化——让数字孪生"自我进化"
数字孪生的核心是预测,而预测模型需要持续优化,该企业采用"在线学习"框架:当新数据到达时,模型不是完全重新训练,而是通过增量学习(如SGD优化器)局部更新参数,当高炉原料成分变化时,模型能快速适应新工况,故障预测准确率从75%提升至89%,这种"动态学习"能力,正是数字孪生区别于传统仿真模型的关键。
智能本质的"数据诠释":从感知到认知的跃迁
当大数据分析深度融入数字孪生,一个更深层的问题浮现:我们究竟在追求什么样的"智能"?2026年的实践给出了答案:智能的本质是"数据驱动的认知闭环"。 2026年自动驾驶与绿色标识热度持续上升,相关领域迎来新发展
以某风电场的数字孪生项目为例:每台风机安装了200+个传感器,每秒产生10MB数据,通过大数据分析,系统不仅能实时监测风机状态(感知层),还能预测未来72小时的发电功率(预测层),更关键的是,它能根据预测结果自动调整风机桨距角(决策层),并将调整效果反馈给模型(反馈层),这种"感知-预测-决策-反馈"的闭环,让风机发电效率提升8%,故障停机时间减少40%。
这种闭环的背后,是大数据分析对"智能"的重新定义:

- 从规则到数据:传统工业控制依赖人工编写的规则(如"温度超过300℃报警"),而数字孪生通过机器学习从数据中自动发现规则(如"温度、振动、电流的组合模式预示故障");
- 从静态到动态:传统模型一旦训练完成就固定不变,而数字孪生的模型能随数据流动持续进化(如风电场模型每月更新一次参数);
- 从局部到全局:传统分析聚焦单一设备(如单台风机),而数字孪生通过数据关联实现系统级优化(如整个风电场的功率分配)。
2026年的新挑战:数据隐私与模型可解释性
森林保护与公益项目及数字经济领域迎来新发展,相关应用不断深化 随着数字孪生的普及,新问题随之而来,2026年5月,某化工企业因数字孪生系统泄露生产配方被罚款2000万元——原来,他们的模型训练数据未脱敏,包含关键工艺参数,这暴露了工业大数据的隐私风险:传感器数据可能包含商业机密,模型参数可能泄露核心技术。
另一挑战是模型可解释性,某航空发动机企业发现,其数字孪生模型能准确预测故障,但工程师无法理解模型为何做出这样的判断——当被问及"为什么认为这个振动模式预示轴承损坏"时,深度学习模型只能给出概率,无法提供物理解释,这在航空等安全关键领域是不可接受的。
2026年关注湿地保护与国家公园及电力市场化发展动态,技术创新推动产业升级 为解决这些问题,2026年的企业开始探索:
- 隐私计算:采用联邦学习框架,让多家企业能在不共享原始数据的情况下联合训练模型(如某汽车产业链联盟通过联邦学习优化供应链);
- 可解释AI:在模型中嵌入物理约束(如将热力学方程作为损失函数的一部分),或采用可解释模型(如决策树替代神经网络),让模型输出"知其所以然";
- 数据审计:建立数据血缘追踪系统,记录每个数据的来源、处理过程和使用场景,确保合规性。
未来展望:数据与物理的"深度融合"
站在2026年的节点回望,数字孪生已从"概念炒作"变为"生产工具",而大数据分析正是这一转变的核心推手,但真正的变革才刚刚开始:随着5G+边缘计算的普及,数据采集将更实时;随着量子计算的发展,复杂模型训练将更高效;随着数字线程(Digital Thread)的成熟,产品全生命周期数据将打通。 2026年碳汇交易与内容审核及环保技术领域迎来新发展,相关应用不断深化
未来的数字孪生,将不再是单一设备的虚拟镜像,而是覆盖"设计-制造-运维"全链条的"数字孪生体网络";大数据分析也不再是辅助工具,而是与物理系统深度融合的"数字神经系统",在这种融合中,我们或许能触摸到智能的本质——不是人类赋予机器的规则,而是数据与物理世界交互中自然涌现的秩序。
2026年的工业现场,一个场景正在成为现实:当操作工调整数字孪生模型中的参数时,物理设备立即响应;当物理设备出现异常时,数字模型自动诊断原因并推荐解决方案,这种"虚实同步、双向交互"的状态,正是大数据分析赋予数字孪生的终极能力——让机器不仅"知道"发生了什么,更"理解"为什么发生,以及"如何"更好运行,而这,或许就是智能最本真的模样。