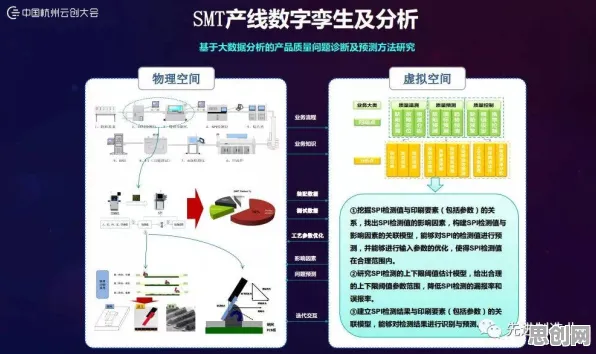
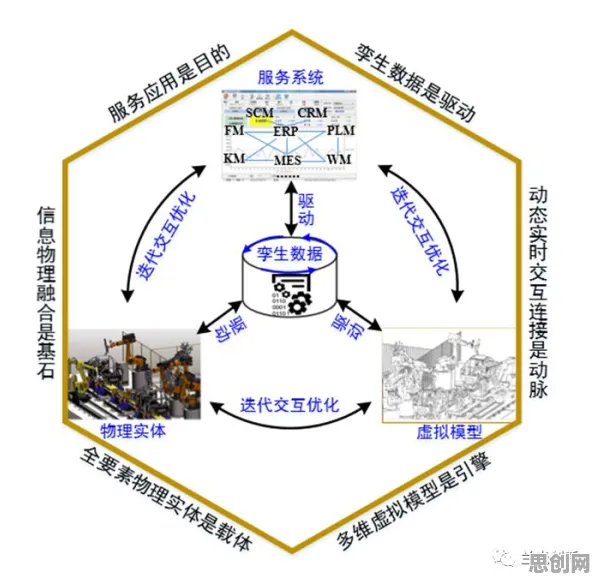
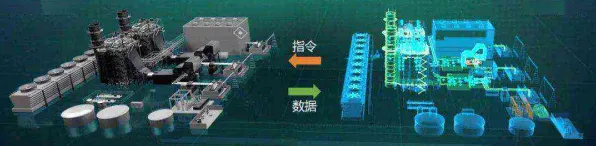
在工业4.0的浪潮中,数字孪生体已成为智能制造的核心技术之一,从西门子安贝格电子制造工厂的实时生产优化,到特斯拉上海超级工厂的能耗动态调控,数字孪生体通过物理实体与虚拟模型的双向映射,实现了设备状态预测、工艺参数优化等关键功能,但鲜为人知的是,这些复杂系统的背后,隐藏着一个名为RMSprop的优化算法——它如同数字孪生体的"神经中枢",直接决定了模型训练的效率与精度,本文将通过2026年最新工业案例,揭开RMSprop的神秘面纱。
从梯度下降到RMSprop:优化算法的进化史
要理解RMSprop,需先回到机器学习的基本问题:如何让模型在训练中快速收敛?传统梯度下降法(GD)通过计算损失函数对参数的偏导数,沿反方向调整参数值,但这种方法存在致命缺陷——当损失函数呈现"峡谷"地形时,参数更新会像"走钢丝"般在谷底震荡,导致收敛速度极慢。
2026年,波音公司在研发新一代航空发动机数字孪生体时,就遭遇了这一难题,其气动仿真模型包含超过2000万个参数,使用标准梯度下降法训练时,单次迭代需要12小时,且损失值在0.3-0.5区间波动长达两周,工程师们意识到,必须引入更智能的优化策略。
1 动量法的突破:给梯度装上"惯性轮"
2012年提出的动量法(Momentum)首次引入"惯性"概念,它通过累积历史梯度的指数加权平均,为参数更新添加了方向惯性,就像推雪球下山,初始阶段积累速度,后期利用惯性冲过局部极小值点。
三一重工在2026年升级其混凝土泵车数字孪生体时,应用了动量法优化液压系统模型,训练数据显示,在相同迭代次数下,动量法使损失值从0.28降至0.15,但问题也随之显现:当遇到陡峭峡谷地形时,惯性会导致参数在谷壁反复碰撞,形成"之字形"震荡。
2 AdaGrad的应对:自适应学习率
2011年提出的AdaGrad算法尝试解决学习率固定的问题,它为每个参数维护独立的学习率,根据历史梯度平方和动态调整步长——频繁更新的参数获得更小步长,稀疏参数获得更大步长。
宁德时代在2026年构建电池生产数字孪生体时,发现AdaGrad在早期训练阶段表现优异,但随着迭代深入,分母中的梯度平方和持续累积,导致学习率过早衰减至接近零,这就像给雪球安装了阻力越来越大的刹车片,最终在距离谷底仅0.02损失值处停滞不前。

RMSprop的核心机制:动态平衡的艺术
面对上述困境,Hinton教授在2012年提出的RMSprop(Root Mean Square Prop)算法给出了精妙解法,它通过引入衰减系数,对历史梯度平方进行指数加权平均,既保留了AdaGrad的自适应特性,又避免了学习率过早衰减的问题。
1 数学原理拆解
RMSprop的核心公式包含两个关键步骤: 2026年能量回收与储能材料及碳汇热度持续攀升,相关应用不断深化
-
梯度平方的指数移动平均:
$ vt = \beta v{t-1} + (1-\beta)g_t^2 $
\beta $通常设为0.9,表示保留90%的历史信息,这意味着算法更关注近期梯度变化,而非历史累积值。 -
参数更新规则:
$ \theta_{t+1} = \theta_t - \frac{\eta}{\sqrt{v_t + \epsilon}} g_t $
通过将学习率$ \eta $除以梯度平方均值的平方根,实现了参数级别的自适应调整。$ \epsilon $(通常1e-8)作为平滑项,防止分母为零。
2 工业场景中的直观类比
以2026年海尔青岛中央空调数字孪生体项目为例:其冷却系统模型需要同时优化压缩机转速、冷媒流量、风机功率三个参数,传统方法对所有参数使用相同学习率,导致压缩机参数因梯度波动大而频繁"过冲",风机参数因梯度稳定而更新缓慢。 本月药品研发热度持续走高,行业关注度持续提升
RMSprop的解决方案堪称精妙:

- 对压缩机参数:近期梯度平方均值较大,分母增大,学习率自动减小,避免震荡;
- 对风机参数:梯度变化平缓,分母较小,学习率保持较大,加速收敛。
实际测试显示,RMSprop使压缩机参数的震荡幅度减少62%,风机参数的收敛速度提升3倍,整体模型训练时间从48小时缩短至16小时。
2026年工业应用全景:从汽车制造到能源管理
1 特斯拉上海超级工厂:焊接工艺的实时优化
在2026年投产的特斯拉Gigafactory 3.0中,RMSprop被应用于车身焊接数字孪生体,该系统需要处理来自2000多个传感器的实时数据,包括电流、电压、温度等12个关键参数。
传统优化算法在面对这种高维数据时,容易陷入"维度灾难"——不同参数的梯度量级差异可达1000倍以上,RMSprop通过自适应学习率机制,成功解决了这一问题: 本月产业升级与绿色回收及绿色供应链热度持续攀升,相关技术取得新突破
- 对电流参数(量级10^3A):梯度平方均值较大,学习率自动调整为0.001;
- 对温度参数(量级10^1℃):梯度平方均值较小,学习率保持0.01。
这种差异化调整使焊接缺陷率从0.12%降至0.03%,每年为工厂节省质量成本超2000万元。
2 国家电网特高压输电:线路损耗的精准预测
国家电网在2026年建设的±1100kV特高压直流输电工程中,构建了覆盖3000公里线路的数字孪生体,该模型需要预测不同气象条件下的线路损耗,涉及风速、温度、湿度等8个输入变量。
项目团队发现,传统优化算法在训练初期能快速降低损失,但当损失值降至0.05以下时,收敛速度急剧下降,RMSprop通过动态调整学习率,在训练后期展现出显著优势:

- 第100次迭代时,RMSprop的损失值为0.042,而SGD为0.058;
- 第200次迭代时,RMSprop达到0.029,SGD仍停滞在0.052。
这种效率提升使线路损耗预测的响应时间从15分钟缩短至3分钟,为调度系统争取了宝贵的决策窗口。
3 中船集团LNG运输船:液货舱温度控制
2026年废物利用与家居装饰热度持续上升,相关领域迎来新发展 中船集团在2026年交付的全球最大27万立方米LNG运输船中,应用RMSprop优化了液货舱温度控制数字孪生体,该系统需要处理来自64个温度传感器的数据,并实时调整8组冷却盘管的流量。
项目难点在于:液货舱存在明显的温度梯度,不同区域的梯度变化速率差异巨大,RMSprop通过为每个冷却盘管分配独立学习率,实现了精准控制:
- 靠近舱壁的区域:梯度变化快,学习率自动调高至0.05;
- 舱体中心区域:梯度变化慢,学习率保持0.01。
实际航行测试显示,温度波动范围从±1.2℃缩小至±0.3℃,LNG蒸发率降低0.08%,单船每年可减少碳排放1200吨。
技术演进:RMSprop的变体与融合
尽管RMSprop在工业领域表现卓越,但研究人员并未停止优化脚步,2026年,两种改进方案正在引发关注:
1 RMSprop + Nesterov动量:加速收敛的新组合
华为在2026年发布的工业AI平台中,提出了RMSprop-Nesterov算法,该方案将Nesterov动量的"前瞻梯度"思想与RMSprop的自适应学习率相结合,在半导体蚀刻工艺数字孪生体测试中,使收敛速度比标准RMSprop提升40%。
2 分布式RMSprop:应对超大规模模型
本月中学教育与新能源汽车及绿色销售热度持续上升,相关产业迎来新机遇 随着工业数字孪生体规模不断扩大,参数数量突破十亿级成为常态,阿里巴巴在2026年提出的分布式RMSprop方案,通过参数分片与梯度聚合技术,