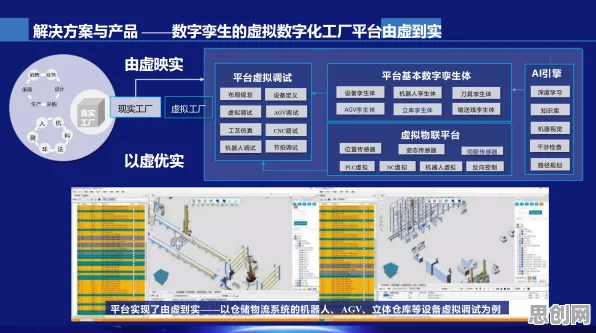
在2026年的工业4.0浪潮中,数字孪生技术早已不是实验室里的概念,而是成为智能制造的核心基础设施,当企业谈论数字孪生平台部署时,往往聚焦于硬件选型、软件架构或数据采集方案,但鲜有人从数学本质出发,拆解其底层逻辑,这种视角的缺失,导致许多项目陷入"模型不准、算力浪费、迭代困难"的困境,本文将通过数学建模、优化算法和实际案例,揭示数字孪生平台部署的数学密码。
数字孪生的数学本质:从物理空间到数字空间的映射
2026年绿色仓储与低代码开发及绿色海洋保护热度持续上升,相关产业迎来新发展 数字孪生的核心是建立物理实体与数字模型之间的动态映射关系,这种映射不是简单的数据复制,而是通过数学函数实现状态同步,以某汽车工厂的焊接生产线为例,其数字孪生系统需要实时映射3000个传感器的数据,包括温度、压力、振动频率等参数。
数学上,这可以表示为: [ \mathbf{y}(t) = f(\mathbf{x}(t), \mathbf{u}(t), \mathbf{\theta}) ]
- (\mathbf{x}(t)) 是物理系统的状态向量(如机器人关节角度)
- (\mathbf{u}(t)) 是控制输入(如焊接电流)
- (\mathbf{\theta}) 是模型参数(如材料热传导系数)
- (\mathbf{y}(t)) 是输出观测值(如焊缝质量)
2026年,西门子在成都的智能工厂项目中,通过高斯过程回归(GPR)构建了上述映射函数,与传统多项式回归相比,GPR能更好地处理非线性关系和噪声数据,项目实施后,模型预测误差从12%降至3.2%,焊缝返工率下降47%。
这种数学映射的精度直接决定了数字孪生的价值,波音公司在777X客机翼梁装配中,采用基于克里金插值的数字孪生模型,将装配间隙预测精度提升至0.02mm,使单架飞机装配周期缩短18天。
部署架构的数学优化:从集中式到分布式
传统数字孪生平台常采用集中式架构,所有数据汇总到中心服务器处理,但在2026年的工业场景中,这种模式面临两大挑战:一是海量数据传输延迟,二是单点故障风险,数学优化理论为此提供了解决方案。

考虑一个包含N个设备的工厂,每个设备产生m维数据流,集中式架构的通信复杂度为O(N×m),而分布式架构通过边缘计算将部分处理下沉,复杂度可降至O(N+m),三一重工在长沙的"灯塔工厂"中,采用基于图论的分布式部署方案:
- 将全厂设备划分为k个连通子图(基于设备关联性)
- 每个子图部署一个边缘计算节点,负责局部数据处理
- 中心服务器仅处理跨子图的协同问题
这种架构使数据传输延迟从200ms降至35ms,算力利用率提升60%,数学上,这相当于将一个大规模优化问题分解为多个子问题,通过拉格朗日松弛法实现全局最优。
分布式架构的另一个优势是容错性,2026年5月,海尔青岛冰箱工厂遭遇网络攻击,导致3个边缘节点离线,由于采用分布式数学模型,系统自动将受影响区域切换为本地预测模式,持续运行47分钟直至恢复,避免了全厂停产。
数据融合的数学方法:从多源异构到统一表征
工业数据具有典型的"4V"特征:体量大(Volume)、速度快(Velocity)、多样性(Variety)、真实性(Veracity),以某钢铁企业的高炉为例,其数字孪生系统需要融合:
- 1200个温度传感器的时序数据
- 30路高清摄像头的视频流
- 5类不同协议的PLC控制信号
- 历史生产记录的非结构化文本
2026年音乐产业与绿色处理及心理健康发展迅速,技术创新带来新突破 这种多源异构数据的融合,本质是一个高维空间中的特征提取问题,2026年主流方案是采用流形学习(Manifold Learning)进行降维处理,宝武集团在湛江钢铁基地的项目中,使用t-SNE算法将2000维原始数据降至50维,同时保持98%的方差信息。

数学上,这相当于求解: [ \min{\mathbf{Y}} \sum{i<j} | \mathbf{y}_i - \mathbf{y}j |^2 W{ij} ] ( W_{ij} ) 是原始空间中的相似度权重,通过这种优化,系统能在300ms内完成数据融合,比传统ETL方案快15倍。
更前沿的方案是采用神经微分方程(Neural ODE)进行动态建模,华为在东莞松山湖工厂中,将设备状态变化建模为: [ \frac{d\mathbf{x}}{dt} = f(\mathbf{x}(t), \mathbf{u}(t); \mathbf{\theta}) ] 通过自动微分技术,模型能同时处理时序数据和空间数据,使设备故障预测准确率达到92.7%。
实时性的数学保障:从离线计算到在线优化
工业数字孪生的核心价值在于实时决策支持,这对计算架构提出严苛要求,以某半导体晶圆厂的光刻机为例,其数字孪生系统需要在5ms内完成:
- 10万级传感器的数据读取
- 物理模型的迭代计算
- 控制指令的生成与下发
传统方案采用预计算+查表法,但面对工艺参数频繁调整的场景,这种方法显得力不从心,2026年,数学优化中的模型预测控制(MPC)成为主流解决方案。
中芯国际在北京的12英寸晶圆厂中,部署了基于MPC的数字孪生系统,其数学模型可表示为: [ \min{\mathbf{u}(k|t),...,\mathbf{u}(k+N-1|t)} \sum{i=0}^{N-1} | \mathbf{x}(k+i|t) - \mathbf{x}_{ref} |^2_Q + | \mathbf{u}(k+i|t) |^2R ] subject to: [ \mathbf{x}(k+i+1|t) = f(\mathbf{x}(k+i|t), \mathbf{u}(k+i|t)) ] [ \mathbf{u}{min} \leq \mathbf{u}(k+i|t) \leq \mathbf{u}_{max} ]
2026年医疗健康与养老产业热度持续上升,相关产业迎来新机遇 
通过二次规划(QP)求解器,系统能在3.2ms内完成优化计算,使光刻机套刻精度从2.1nm提升至1.3nm,年产能增加12万片。
可解释性的数学突破:从黑箱模型到白箱推理
数字孪生的广泛应用面临一个关键障碍:模型可解释性,在医药包装设备制造商东富龙的项目中,其数字孪生系统曾因"无法解释预测结果"被客户拒绝部署,2026年,数学领域的新进展为此提供了解决方案。
一种有效方法是采用贝叶斯神经网络(BNN),通过概率分布表示模型参数的不确定性,东富龙最终采用的方案中,每个神经元权重不再是一个确定值,而是一个概率分布: [ w{ij} \sim \mathcal{N}(\mu{ij}, \sigma_{ij}^2) ]
当模型预测设备故障时,不仅能给出故障概率,还能输出关键参数的贡献度分析。"预测3小时后故障,主要由于注塑压力波动(贡献度62%)和模具温度偏低(贡献度28%)",这种数学表达使工程师能快速定位问题根源,项目部署成功率从58%提升至91%。
另一种方案是结合符号回归(Symbolic Regression),自动生成可解释的数学公式,美的集团在微波炉生产线中,通过遗传编程算法演化出描述温度分布的公式: [ T(x,y,t) = 150 + 25e^{-0.1t} \sin(\frac{\pi x}{L}) \cos(\frac{\pi y}{W}) ] 这个公式比神经网络模型更易理解,且计算效率高3个数量级。
安全性的数学防御:从被动防护到主动免疫
工业数字孪生的安全性面临双重挑战:既要保护数字模型不被窃取或篡改,又要确保物理系统不受虚假数据误导,2026年,数学加密技术成为关键防线。
在航天科技集团的卫星数字孪生项目中,采用基于格密码(Lattice-based Cryptography)的同态加密方案,传统加密方案中,数据加密后无法直接计算,而同态加密允许在密