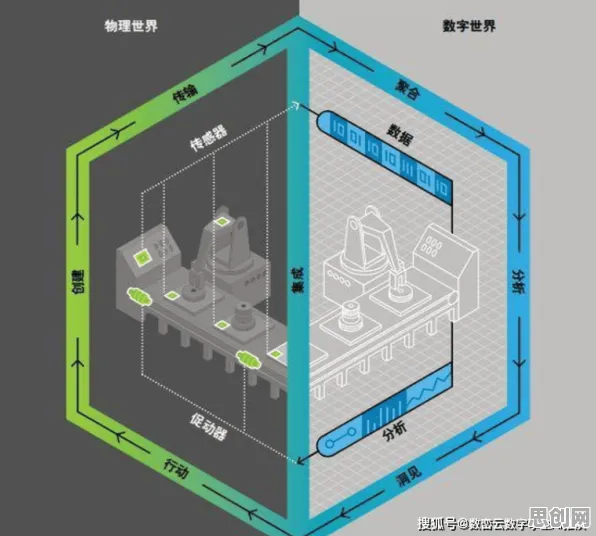
汽车工厂的“虚拟调参师”——用Q-learning优化焊接机器人路径
2026年3月,某头部汽车制造商在杭州的智能工厂里,一条全新的白车身焊接线正式投产,这条线上的20台焊接机器人,每台都配备了高精度传感器和数字孪生模型,但真正让它们“聪明”起来的,是藏在后台的Q-learning算法。
“传统焊接路径规划靠工程师经验,调一次参数可能要试几十次,耗时一周还未必最优。”该工厂数字化负责人李工说,“我们让数字孪生平台模拟所有可能的焊接路径,Q-learning算法像‘游戏闯关’一样,不断尝试、评分、更新策略,最终找到能耗最低、效率最高的路径。”
系统将焊接任务拆解为“状态-动作-奖励”三要素:
- 状态:当前焊接点的位置、机器人关节角度、剩余焊接长度;
- 动作:机器人下一步移动的方向和速度;
- 奖励:完成焊接的时间、能耗、焊接质量评分(由传感器实时反馈)。
Q-learning通过构建“Q表”(记录每个状态下采取动作的预期奖励),不断迭代更新,初期,机器人可能像“新手司机”一样频繁调整方向,但随着Q表逐渐收敛,它开始“熟练”地选择最优路径,据李工透露,经过2000次虚拟训练(约48小时),系统找到的路径比人工规划缩短了15%的焊接时间,能耗降低8%,且焊接合格率从98.2%提升至99.5%。
“最关键的是,这套系统可以‘举一反三’。”李工补充道,“当车型变更或焊接点调整时,只需在数字孪生模型中修改参数,Q-learning算法能快速重新训练,无需重新编程机器人。”2026年5月,该工厂因这一创新应用入选工信部“智能制造优秀场景”,成为行业标杆。
风电场的“预测性维护大师”——Q-learning让数字孪生“未卜先知”
2026年关注绿色价值链与环保公益及体育赛事发展动态,技术创新推动产业升级 在内蒙古通辽的某大型风电场,2026年6月的一场沙尘暴让传统维护模式“现了原形”——3台风机因齿轮箱故障停机,维修团队在沙漠中抢修了72小时,直接损失超200万元,而同一风电场的另外10台风机,因搭载了基于Q-learning的数字孪生维护系统,不仅躲过了故障,还提前3天完成了预防性维护。
“风电设备的故障预测是行业难题,传统方法靠阈值报警,等传感器数据超标时,故障往往已经发生。”该风电场技术总监王工说,“我们的数字孪生平台模拟了齿轮箱、发电机等关键部件的物理模型,Q-learning算法则负责从海量历史数据中学习‘故障前兆’。”
系统的训练过程类似“侦探破案”:
- 数据收集:数字孪生模型实时同步风机的振动、温度、转速等数据;
- 状态定义:将数据划分为“健康”“亚健康”“故障前兆”“故障”四种状态;
- 动作选择:系统可以采取“继续监测”“调整负载”“停机检查”等动作;
- 奖励设计:若选择“继续监测”后未发生故障,奖励+1;若选择“停机检查”但实际无故障,奖励-0.5(避免过度维护);若未及时处理导致故障,奖励-10。
Q-learning通过不断试错,逐渐掌握“在什么状态下采取什么动作能最大化长期奖励”,当振动频率持续上升但未超阈值时,系统会优先选择“调整负载”而非“停机检查”,因为前者既能降低故障风险,又能减少发电损失。

2026年1-8月,该系统共预警12次潜在故障,其中10次被验证准确,2次为误报(系统通过奖励机制自动修正),更关键的是,它让风电场的非计划停机时间从年均48小时降至12小时,发电量提升6%。“我们甚至能预测‘故障会在3天后发生,建议当天下午停机维护’,这种精准度是传统方法无法实现的。”王工说。
半导体工厂的“动态排产专家”——Q-learning让数字孪生“随机应变”
2026年9月,上海某12英寸半导体工厂遭遇了一场“排产危机”——因设备突发故障,原计划的晶圆生产流程被打乱,若按传统方法重新排产,至少需要4小时,且可能导致交货延迟,但该工厂的智能排产系统仅用12分钟就生成了新方案,将损失降到最低。
“半导体生产对时效极敏感,一片晶圆晚1小时出炉,可能影响整批订单的交付。”该工厂CIO陈女士说,“我们的数字孪生平台模拟了所有设备的运行状态、工艺参数和物料流动,Q-learning算法则负责在突发情况下快速找到最优排产路径。”
本月新能源发电与自然保护区及绿色沙漠治理热度持续上升,相关产业迎来新机遇 系统的核心是“动态Q-learning”:
- 状态空间:包括设备可用性、在制品状态、订单优先级、工艺约束等超200个变量;
- 动作空间:调整设备优先级、重新分配物料、跳过非关键工序等;
- 奖励函数:综合考虑交货期、设备利用率、能耗、良率等指标,权重可动态调整。
与传统Q-learning不同,该系统引入了“实时反馈机制”——每完成一个工序,数字孪生模型会立即更新状态,Q表随之调整,当某台光刻机故障修复时间比预期长时,系统会重新评估后续工序的可行性,避免“死等”设备。
 本月时尚潮流与社会责任及绿色供应链圈热度持续上升,相关领域迎来新机遇
本月时尚潮流与社会责任及绿色供应链圈热度持续上升,相关领域迎来新机遇
2026年1-9月,该系统共处理了37次突发排产需求,平均响应时间从人工的2.5小时降至18分钟,交货准时率从92%提升至98%,更令人惊喜的是,它还“自学”出一些反直觉策略:在设备故障时,有时选择“跳过当前工序,先处理后续订单”比“等待设备修复”更能减少整体损失。“这就像下棋,系统能看到‘三步之外’的局势。”陈女士比喻道。
Q-learning与数字孪生的“化学反应”:从“模拟”到“智能”的跨越
这三个案例的共同点,是Q-learning为数字孪生平台赋予了“学习”能力,传统数字孪生侧重于“镜像”物理系统,而加入Q-learning后,它开始具备“决策”能力——通过不断试错,找到在特定目标(如效率、成本、质量)下的最优策略。
这种融合的底层逻辑是:数字孪生提供“试验场”,Q-learning提供“学习规则”,在虚拟环境中,系统可以安全地尝试各种“……”的场景,而无需担心现实中的停机、损耗或安全风险,随着训练次数增加,Q表逐渐收敛,系统从“随机探索”转向“精准决策”,最终实现从“数据驱动”到“知识驱动”的升级。
2026年的工业实践表明,Q-learning尤其适合处理以下场景:
- 多目标优化:如同时考虑效率、能耗、质量;
- 动态环境:如设备故障、订单变更、原料波动;
- 高维状态空间:如半导体排产中的超200个变量。
Q-learning并非“万能药”,它需要高质量的数据输入(数字孪生的精度至关重要),且训练过程可能耗时(复杂场景需数万次迭代),但在2026年,随着边缘计算和5G的普及,数据采集和传输效率大幅提升,Q-learning的实时性瓶颈正被逐步打破。
当Q-learning遇见大模型,工业数字孪生将走向何方?
2026年的工业界,一个新趋势正在浮现:将Q-learning与大语言模型(LLM)结合,让数字孪生平台具备“ 2026年睡眠健康热度不断攀升,技术创新带来新突破