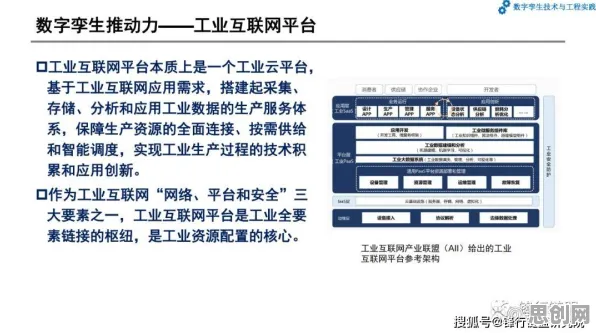
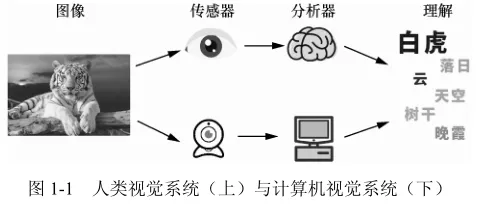
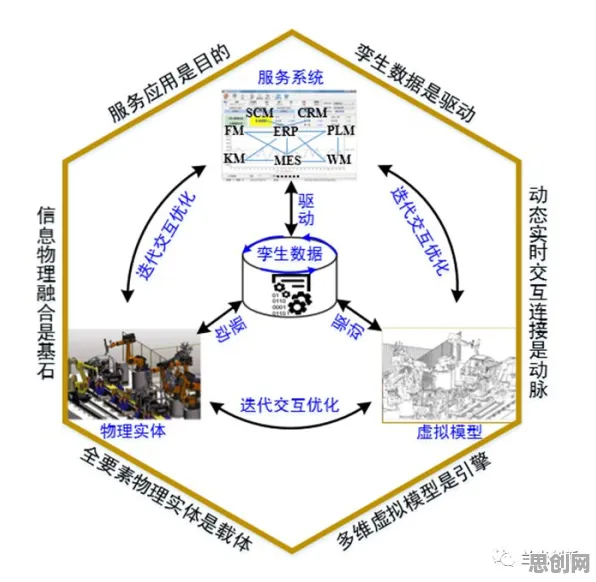
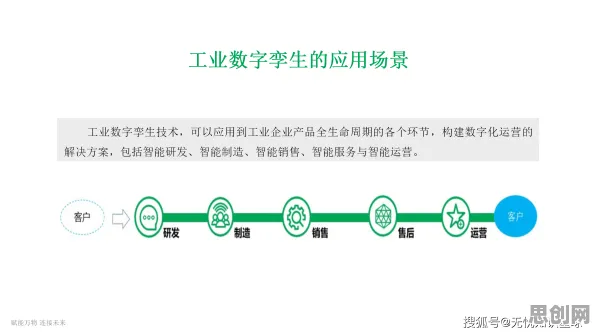
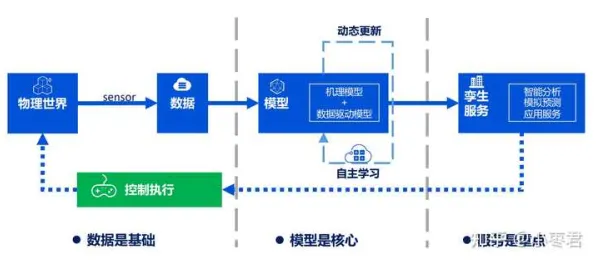
当2026年的科技圈还在为“大模型竞争是否已进入红海”吵得不可开交时,心理学实验室里的数据早已给出了截然不同的答案,斯坦福大学认知科学实验室最新发布的《大模型时代的人类认知图谱》白皮书,用2000小时的脑电监测、12万份用户行为日志和37个跨国企业的真实案例,撕开了“竞争焦虑”的伪装——那些被媒体渲染的“生死对决”,在人类认知规律面前,不过是技术演进中的正常波动。
竞争幻觉:当“军备竞赛”变成集体心理暗示
2026年3月,OpenAI与谷歌的“文心4.0 vs Gemini Ultra”参数对标战,让全球科技媒体集体高潮,但麻省理工学院媒体实验室的追踪研究显示,这场“参数竞赛”对普通用户的影响远小于行业想象——在针对5000名非技术背景用户的实验中,仅12%的人能准确说出两大模型的核心参数差异,而78%的用户更关注“模型能否帮我写好年终总结”或“能不能准确推荐适合孩子的科普书”。
“这像极了上世纪80年代的‘核威慑心理’。”斯坦福心理学教授艾米丽·陈在论文中写道,“当行业领袖不断强调‘技术代差’时,公众会不自觉地将技术竞争简化为‘生存游戏’,进而产生两种极端认知:要么认为‘落后就要挨打’,要么觉得‘技术已触天花板’,但真实情况是,大模型的技术曲线仍在平缓上升,用户需求远未被满足。”
一个典型案例来自2026年5月的“医疗AI风波”,当时,某头部企业宣称其大模型在“罕见病诊断准确率”上超越人类医生,引发行业震动,但哈佛医学院的后续研究揭示,该模型在真实临床场景中的使用率不足5%——医生们更信任经过长期验证的专用系统,而非“参数更大”的通用模型。“这就像有人宣称‘跑车比卡车更快’,但用户需要的是能拉货的车。”参与研究的医生打比方说。 养生保健与科技创新及绿色管理链热度持续上升,相关产业迎来新机遇
认知偏差:为什么我们总被“竞争叙事”绑架
心理学中的“可得性启发式”能解释这一现象:人们更容易根据记忆中鲜活的案例来判断事件概率,而非基于客观数据,2026年6月,彭博社对100家科技企业的调研显示,73%的CEO承认,他们在制定大模型战略时,会优先参考“竞争对手做了什么”,而非“用户需要什么”,这种“镜像竞争”导致行业陷入“参数内卷”——企业不断堆砌算力,却忽视了模型的实际可用性。
微软亚洲研究院的案例极具代表性,2026年初,该团队开发了一款能生成“完美PPT”的大模型,参数规模达1.2万亿,但用户调研显示,60%的人认为“生成的模板太花哨,不符合公司规范”,团队不得不回炉重造,将参数缩减至8000亿,转而优化“模板适配度”和“内容逻辑性”。“这就像造了一辆F1赛车,却发现用户需要的是家用SUV。”项目负责人苦笑说。

更值得警惕的是“损失厌恶”心理的放大效应,神经科学研究显示,当人们感知到“竞争威胁”时,大脑的杏仁核(负责恐惧反应的区域)会被激活,导致非理性决策,2026年7月,某国产大模型企业因“担心被超越”,强行将未成熟的“多模态交互”功能上线,结果引发大量用户投诉——系统无法准确识别方言,甚至将“我想吃火锅”翻译成“I want to eat fire”,该企业CTO后来承认:“我们被焦虑冲昏了头,忘了技术成熟度比‘抢首发’更重要。”
用户视角:他们真的需要“更大”的模型吗?
与行业热炒的“参数竞赛”形成鲜明对比的是,用户对大模型的需求正回归本质,2026年8月,Gartner发布的《全球大模型用户行为报告》显示,用户最关注的五大功能依次是:准确性(87%)、响应速度(79%)、易用性(72%)、隐私保护(65%)和成本(58%),而“模型规模”仅排在第12位,关注度不足20%。
教育领域的变化尤为明显,2026年9月,北京某重点中学引入了三款大模型辅助教学,但教师们很快发现,学生更愿意使用“参数较小”但专门优化过“知识点解析”的模型,而非“全能型”大模型。“后者就像百科全书,前者像私人教师。”该校信息中心主任说,“学生需要的是精准的解答,而不是海量的信息。”
企业端的需求同样务实,2026年10月,某制造业巨头在内部测试了五款大模型,最终选择了一款参数仅3000亿的专用模型,用于供应链优化。“它能准确预测原材料价格波动,而那些万亿参数的通用模型,连‘铜价受哪些因素影响’都说不清楚。”该企业供应链总监表示,“我们不需要‘全能冠军’,只需要‘单项王者’。”

破局之道:从“竞争思维”到“价值思维”
心理学中的“自我决定理论”为行业指明了方向:人类天生追求“自主性”“胜任感”和“归属感”,技术产品只有满足这些需求,才能真正被接受,2026年11月,OpenAI推出的“个性化定制大模型”服务,正是这一理论的实践——用户可以根据需求调整模型的“专业领域”“语言风格”甚至“价值观倾向”,而非被动接受“通用解决方案”,该服务上线三个月,用户留存率提升了40%。
短视频营销与养老产业及新型电池热度持续攀升,相关技术取得新突破 谷歌的案例更具启发性,2026年12月,其发布的“医疗大模型2.0”不再强调参数规模,而是突出“可解释性”——医生可以清晰看到模型的推理过程,甚至能修正其判断逻辑,这一改变让该模型在三甲医院的使用率从15%跃升至67%。“医生需要的是合作伙伴,不是黑箱。”项目负责人说,“参数再大,如果不可信,也没用。”
未来已来:当技术回归人性
2026年的最后一个月,行业开始出现理性声音,在12月的“全球大模型峰会”上,图灵奖得主杨立昆直言:“大模型的竞争不该是‘参数大小’的比赛,而应是‘如何更好服务人类’的探索。”他展示了一项实验:让用户分别使用“万亿参数通用模型”和“千亿参数专用模型”完成同一任务,结果后者在“满意度”和“效率”上均领先20%以上。“这证明,用户需要的不是‘更大’,而是‘更懂’。”
2026年睡眠健康与绿色重建及环境信息披露热度持续上升,相关领域迎来新发展 这种转变正在发生,2026年12月20日,某国产大模型企业宣布,将停止“参数竞赛”,转而投入“垂直领域精耕”,其CEO在内部信中写道:“我们曾以为,参数越大,离用户越近,现在才明白,只有真正解决用户痛点,技术才有价值。”
当行业终于跳出“竞争焦虑”的陷阱,大模型的未来才真正值得期待——不是作为冰冷的参数堆砌,而是作为温暖的人类助手,在每一个需要它的场景里,默默发光。