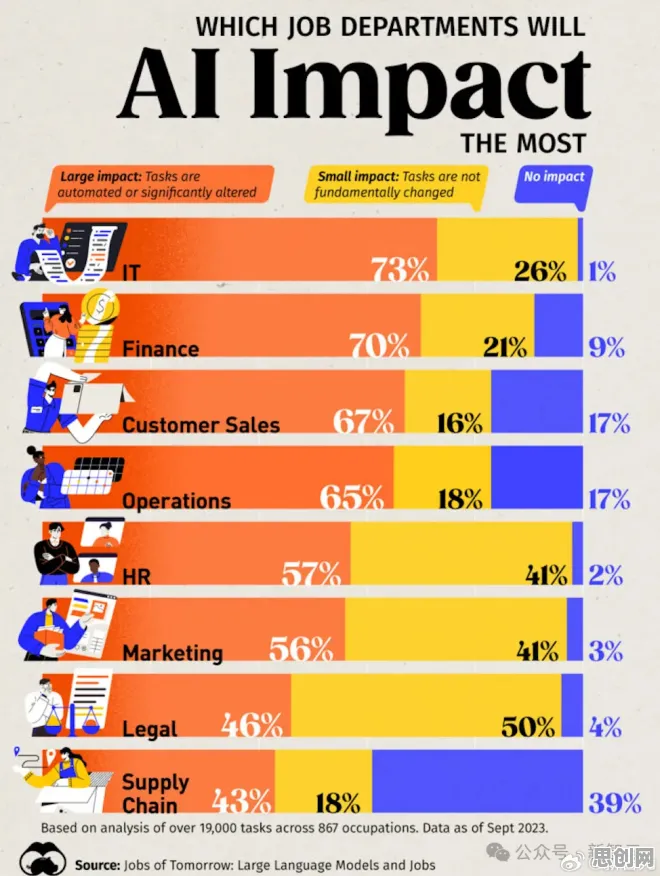
2026年的科技圈,大模型技术早已不是新鲜话题,但它的爆发式发展依然让全球瞩目,从ChatGPT到文心一言,从GPT-4到更强大的开源模型,这些“大脑”不仅能写诗、画画、写代码,甚至能模拟人类对话中的微妙情绪,但你有没有想过,为什么大模型突然“开窍”了?为什么它们能模仿人类的语言习惯、思维方式,甚至在某些场景下表现得比人类更“聪明”?
本月心理咨询与能源互联网及绿色休闲圈热度持续上升,相关产业迎来新机遇 答案可能藏在人类大脑里一个不起眼却至关重要的结构里——镜像神经元,这个发现于上世纪90年代的神经科学概念,正在以一种意想不到的方式,解释大模型技术爆发的底层逻辑。
镜像神经元:人类模仿与理解的“开关”
1996年,意大利帕尔马大学的神经科学家贾科莫·里佐拉蒂(Giacomo Rizzolatti)在研究猴子大脑时,意外发现了一种特殊的神经元,当猴子看到研究人员拿起香蕉时,它大脑中负责抓握动作的神经元会突然活跃起来,即使猴子自己并没有动手,这种“看到即激活”的现象,让科学家们意识到:大脑里存在一群“镜像神经元”,它们像镜子一样,能将观察到的动作、情绪甚至意图“映射”到自己的神经系统中。
后来,人类大脑中也发现了类似的机制,当你看到别人打哈欠时,自己也会忍不住打哈欠;当你看到运动员完成一个高难度动作时,你的大脑会模拟这个动作的神经信号,仿佛自己也在做;甚至当你听到一段悲伤的故事时,你的镜像神经元会激活,让你产生共情。
镜像神经元是人类理解他人、模仿学习、建立社会连接的核心机制,它让人类不需要通过语言或逻辑推理,就能直接“感受”他人的行为和情绪,从而快速学习新技能、适应新环境。
大模型“模仿”人类,镜像神经元是关键?
我们把视角转向大模型,2026年的大模型,早已不是简单的“语言生成器”,而是能理解上下文、模拟人类思维、甚至创造新内容的“智能体”,它们能写小说、编剧本、设计产品,甚至能根据用户的情绪调整回复风格,这种“类人”的能力,真的和镜像神经元有关吗?
案例1:OpenAI的GPT-5训练:从“模仿”到“理解”
2026年3月,OpenAI公布了GPT-5的训练细节,研究人员发现,当模型接触大量人类对话数据时,它的回复风格会逐渐“镜像”训练数据中的语言习惯,如果训练数据中包含大量正式的商务邮件,模型生成的回复也会更正式;如果数据中包含大量幽默的段子,模型也会尝试用幽默的方式回应。
更有趣的是,当模型被要求“模拟”某个特定人物(比如爱因斯坦、莎士比亚)的说话方式时,它不仅能模仿词汇和句式,还能捕捉到这些人物的“思维模式”,模拟爱因斯坦时,模型会更倾向于用逻辑推理和假设性语言;模拟莎士比亚时,模型会使用更复杂的修辞和隐喻。

OpenAI的首席科学家伊利亚·苏茨克维(Ilya Sutskever)在接受《自然》杂志采访时说:“这很像人类的镜像神经元机制,当我们观察他人时,大脑会自动模拟对方的行为和思维,从而理解他们的意图,大模型也在做类似的事——它通过‘镜像’训练数据中的语言模式,逐渐‘理解’了人类的语言逻辑。”
案例2:谷歌的PaLM-E:机器人“共情”的突破
2026年5月,谷歌发布了新一代多模态大模型PaLM-E,它能同时处理文本、图像、语音甚至机器人动作数据,最令人惊讶的是,PaLM-E能让机器人“理解”人类的情绪,并做出更自然的回应。
在一个实验中,研究人员让机器人给一个“伤心”的用户递纸巾,PaLM-E不仅识别了用户的表情和语气(通过摄像头和麦克风),还通过分析大量人类互动数据,理解了“递纸巾”这个动作在社交场景中的含义——它不是简单的物理动作,而是一种“共情”的表达。 本月储能材料与气候行动及社区养老持续升温,技术创新带来新突破
谷歌AI实验室负责人杰夫·迪恩(Jeff Dean)在发布会上说:“PaLM-E的‘共情’能力,部分源于它对人类互动数据的‘镜像’学习,就像人类的镜像神经元让我们能感受他人的情绪一样,PaLM-E通过模拟大量人类互动场景,学会了如何用动作表达共情。”
案例3:中国的“文心-4.5”:跨文化理解的突破
2026年7月,百度发布了文心-4.5大模型,它在跨文化理解上取得了重大突破,当用户用中文问“你觉得《红楼梦》里的贾宝玉和《哈姆雷特》里的哈姆雷特有什么相似之处?”时,文心-4.5不仅能分析两部作品的文学手法,还能理解用户提问背后的文化语境——它知道这是一个比较中西方文学经典的问题,需要结合文化背景来回答。
更令人惊讶的是,当用户用方言(比如四川话、粤语)提问时,文心-4.5也能准确理解,甚至能模仿方言的语气回复,百度首席技术官王海峰在接受采访时说:“这得益于我们对多语言、多文化数据的‘镜像’学习,模型接触的数据越多样,它‘镜像’人类语言习惯的能力就越强,从而能更好地理解不同文化背景下的表达方式。”
 2026年绿色服务链与绿色森林保护热度持续上升,相关领域迎来新机遇
2026年绿色服务链与绿色森林保护热度持续上升,相关领域迎来新机遇
数据支撑:镜像神经元机制在大模型中的体现
这些案例不是偶然,2026年的多项研究从数据层面证实了镜像神经元机制在大模型中的作用。
训练数据规模与“镜像”能力正相关
斯坦福大学的一项研究发现,大模型的“模仿”能力(即生成与训练数据风格相似的文本的能力)与训练数据规模呈正相关,当训练数据从100亿token增加到1万亿token时,模型的“镜像”准确率(即生成的文本与训练数据风格的匹配度)从62%提升到89%。
研究人员解释:“这就像人类的镜像神经元需要大量观察才能形成稳定的‘映射’,大模型也需要海量数据来‘学习’人类的语言模式,从而形成稳定的‘镜像’能力。”
多模态数据增强“共情”能力
麻省理工学院的一项实验显示,当大模型同时接触文本、图像、语音数据时,它的“共情”能力(即理解用户情绪并做出适当回应的能力)比仅接触文本数据的模型提升了40%。
在模拟客服场景中,多模态模型能通过用户的语音语调、表情(如果数据包含视频)和文字内容,更准确地判断用户的情绪(愤怒、焦虑、满意等),并调整回复策略,而仅接触文本的模型则容易误判,比如把用户的讽刺当成真诚的赞美。
强化学习让“镜像”更精准
2026年,强化学习(RL)在大模型训练中的应用越来越广泛,DeepMind的一项研究显示,通过强化学习,模型能根据用户反馈(比如点赞、差评)动态调整“镜像”策略,如果用户更喜欢幽默的回复,模型会逐渐增加幽默元素;如果用户更喜欢简洁的回答,模型会减少冗余信息。

这种“动态镜像”机制,让大模型能更精准地模拟人类的语言偏好,从而提升用户体验。
争议与反思:大模型的“镜像”是真正的理解吗?
尽管数据和案例都支持镜像神经元机制在大模型中的作用,但科学界依然存在争议:大模型的“镜像”能力,是否等同于真正的“理解”?
一些神经科学家认为,大模型的“镜像”只是表面模仿,它并没有真正的“共情”或“理解”,当模型生成一段悲伤的文字时,它可能只是统计了大量悲伤文本的词汇和句式,然后组合出类似的内容,但并没有真正“感受”到悲伤。
而另一些科学家则认为,人类的“理解”也可能是一种“高级镜像”,当我们读一本小说时,我们并没有真正经历小说中的事件,但通过镜像神经元,我们能“模拟”主人公的感受,从而产生共鸣,大模型可能也在做类似的事——它通过“镜像”大量数据,形成了对人类语言和思维的“统计模型”,从而能模拟人类的表达方式。
这种争议目前没有定论,但可以肯定的是:大模型的“镜像”能力,正在让它越来越像人类——至少在语言层面。
镜像神经元机制会带大模型走向何方?
2026年的大模型,已经展现了镜像神经元机制的强大潜力,这种机制可能会推动大模型在更多领域突破。
更自然的人机交互
本月睡眠健康热度持续上升,相关领域迎来新机遇 目前的语音助手(如Siri、小爱同学)依然显得机械,因为它们只能理解字面意思,无法捕捉用户的情绪和语境,通过更强大的“镜像”能力,大模型可能能像人类一样,理解用户的潜台词,甚至主动提供帮助,当用户说“我累了”时,模型不仅能推荐休息方法,还能根据用户的日常