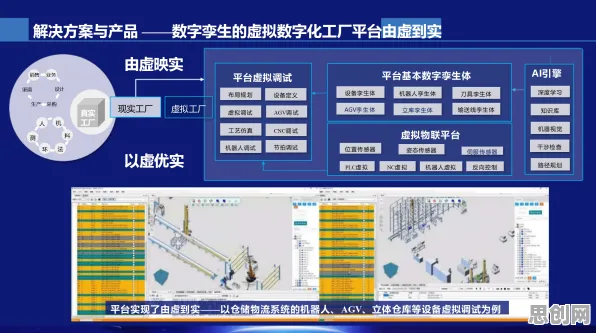
在2026年的工业领域,数字孪生技术早已不是新鲜概念,但它的深度应用和背后隐藏的数学逻辑,却像一座尚未完全挖掘的宝藏,持续为制造业带来惊喜,当人们谈论数字孪生时,往往聚焦于它如何通过虚拟模型映射物理实体,实现实时监控与优化,但很少有人意识到,这一切的精准性,早已被一个看似抽象的数学工具——损失函数,提前“预测”和“校准”。
数字孪生的“双胞胎”逻辑:从物理到虚拟的精准映射
本月生物燃料与绿色转化及环境税热度持续上升,相关领域迎来新发展 数字孪生的核心在于“双胞胎”关系:一个物理实体(如一台机床、一条生产线,甚至一座工厂),对应一个虚拟模型,这个模型不是简单的3D可视化,而是集成了物理实体的几何结构、运动规律、材料特性、环境参数等所有关键信息,通过传感器实时采集数据,驱动虚拟模型与物理实体同步运行。
以2026年德国西门子安贝格电子制造工厂为例,这里每条生产线都配备了数百个传感器,实时采集温度、压力、振动、电流等数据,这些数据通过5G网络传输到云端,驱动数字孪生模型同步运行,当物理生产线上的某台机器人出现轻微振动时,虚拟模型会立即捕捉到这一变化,并通过算法分析振动频率、幅度与历史数据的差异,判断是机械磨损、螺丝松动还是程序错误,这种精准映射,让工程师无需到现场就能定位问题,维修效率提升了40%。
本月绿色服务网热度不断攀升,技术创新带来新突破 但数字孪生的精准性并非天生,它依赖于一个关键环节:模型校准,就像给双胞胎量身高、称体重,虚拟模型需要不断与物理实体“对账”,确保两者的数据偏差在允许范围内,而这一过程,正是损失函数发挥作用的舞台。
损失函数:数字孪生的“校准师”
损失函数(Loss Function)是机器学习中的核心概念,它衡量的是模型预测值与真实值之间的差异,在数字孪生中,损失函数的作用类似“校准师”:通过比较虚拟模型的输出(如预测的振动频率)与物理实体采集的实际数据,计算两者之间的误差(即损失值),然后调整模型参数,使损失值最小化。
以2026年美国通用电气(GE)的航空发动机数字孪生项目为例,GE为每台在役发动机都建立了数字孪生模型,实时监测其运行状态,但发动机的复杂程度远超普通设备,其振动、温度、压力等参数受材料老化、环境变化、操作习惯等多重因素影响,模型预测与实际数据之间难免存在偏差。
GE的工程师团队设计了一套多目标损失函数,同时考虑振动频率、温度波动、燃油效率等多个维度的误差,当模型预测某台发动机的振动频率为100Hz,而实际采集数据为105Hz时,损失函数会计算这一偏差对发动机寿命、燃油消耗的影响,并生成一个综合损失值,通过不断调整模型参数(如材料疲劳系数、气流动力学参数),使损失值逐步降低,最终实现虚拟模型与物理实体的精准同步。
这一过程并非一蹴而就,GE的工程师发现,单纯追求单个参数的精准(如仅降低振动频率的误差)可能导致其他参数(如温度)的偏差增大,他们采用加权损失函数,为不同参数分配不同的权重,确保模型在整体上最优,经过数万次迭代训练,数字孪生模型的预测准确率从最初的75%提升至92%,为发动机的预防性维护提供了可靠依据。
从校准到预测:损失函数如何“预见”未来
数字孪生的终极目标不仅是实时映射物理实体,更是预测其未来状态,提前发现潜在问题,而这一能力,同样离不开损失函数的“预训练”。
以2026年中国三一重工的混凝土泵车数字孪生项目为例,混凝土泵车是建筑工地的“巨无霸”,其臂架长度可达数十米,作业时承受巨大压力,一旦出现故障,不仅影响施工进度,还可能危及安全,三一重工为每台泵车建立了数字孪生模型,但工程师们不满足于实时监控,他们希望模型能预测臂架的疲劳寿命,提前安排维护。

要实现这一目标,模型需要“学习”泵车在不同工况下的疲劳规律,三一的工程师收集了数千台泵车的历史数据,包括作业时间、负载重量、环境温度、臂架振动等,并标记了每台泵车的实际疲劳寿命(通过维修记录和检测数据验证),他们设计了一个基于时间序列的损失函数,将模型预测的疲劳寿命与实际寿命进行比较,计算误差。
2026年绿色建筑与志愿服务热度持续攀升,相关应用不断深化 训练过程中,模型不断调整参数(如材料疲劳系数、应力集中因子),使损失值最小化,经过数月训练,模型不仅能准确预测单台泵车的疲劳寿命,还能根据当前工况(如高温、高负载)动态调整预测结果,当模型预测某台泵车的臂架在300小时后可能达到疲劳极限时,工程师可以提前安排更换关键部件,避免突发故障。
这一案例的亮点在于,损失函数不仅用于校准模型,还通过历史数据的“预训练”,让模型具备了“预见”未来的能力,这种能力,正是数字孪生从“监控工具”升级为“决策助手”的关键。
损失函数的“进化”:从单一到复合,从静态到动态
随着工业场景的复杂化,损失函数的设计也在不断“进化”,2026年的数字孪生项目,很少再使用单一的损失函数,而是采用复合损失函数,同时考虑多个目标(如预测准确率、计算效率、模型鲁棒性);损失函数也不再是静态的,而是能根据实时数据动态调整权重,适应不同工况。
以2026年日本丰田汽车的焊接生产线数字孪生项目为例,焊接是汽车制造的关键工序,其质量受电流、电压、焊接时间、材料厚度等多重因素影响,丰田的工程师为每条焊接生产线建立了数字孪生模型,但发现单一损失函数难以平衡不同参数的影响,过度追求焊接电流的精准可能导致电压波动增大,反而影响焊接质量。 2026年健身运动与空气净化及污水处理热度持续攀升,相关领域迎来新突破
为此,丰田团队设计了一套动态复合损失函数,该函数包含三个子目标:焊接质量(通过无损检测数据验证)、能耗(电流×电压×时间)、设备寿命(通过振动和温度数据评估),每个子目标对应一个子损失函数,并通过一个动态权重矩阵分配权重,权重矩阵会根据实时数据(如材料厚度变化、环境温度波动)自动调整,确保模型在不同工况下都能优化整体性能。

当检测到材料厚度增加时,权重矩阵会提高焊接电流的权重,降低能耗的权重,因为此时需要更大电流确保焊接质量,而能耗的增加是次要的,这种动态调整,让数字孪生模型在复杂多变的工业环境中依然能保持高精度预测。
损失函数的“边界”:数据质量与模型复杂度的平衡
尽管损失函数在数字孪生中扮演着核心角色,但它并非万能,2026年的工业实践表明,损失函数的效果高度依赖于数据质量和模型复杂度的平衡。
2026年绿色标识与会展经济及碳关税热度持续攀升,相关技术取得新突破 以2026年印度塔塔钢铁的高炉数字孪生项目为例,高炉是钢铁生产的核心设备,其内部温度、压力、气流分布等参数难以直接测量,只能通过少量传感器间接推断,塔塔钢铁的工程师尝试用数字孪生模型预测高炉的炉况(如是否出现“悬料”故障),但发现模型预测结果与实际偏差较大。
问题出在数据上,高炉内部环境极端复杂,传感器采集的数据存在噪声大、采样率低、相关性弱等问题,即使设计了复杂的损失函数,模型也无法从“脏数据”中提取有效信息,塔塔团队不得不先投入大量资源清洗数据(如去噪、插值、特征提取),再训练模型,才逐步提升了预测准确率。
另一个案例来自2026年巴西淡水河谷的矿山卡车数字孪生项目,淡水河谷希望用数字孪生模型预测卡车的轮胎磨损,提前安排更换,但矿山环境恶劣,卡车行驶路线多变,轮胎受力情况复杂,初始模型为了追求高精度,设计了过于复杂的结构(如多层神经网络),导致训练时间过长,且容易过拟合(在训练数据上表现好,但在新数据上表现差)。
淡水河谷的工程师最终简化了模型结构,采用轻量级的卷积神经网络,并设计了针对轮胎磨损的专用损失函数(如结合磨损深度、行驶里程、路面粗糙度),这一调整不仅缩短了训练时间,还提升了模型的泛化能力,使其能适应不同矿山、不同卡车的轮胎磨损预测。
损失函数背后的工业哲学
回到最初的问题:为什么说“工业数字孪生技术其实有它的道理,损失函数早就预测到了”?答案在于,数字孪生的本质是一场“虚拟与物理”的对话,而损失函数是这场对话的“翻译官”和“校准师”,它