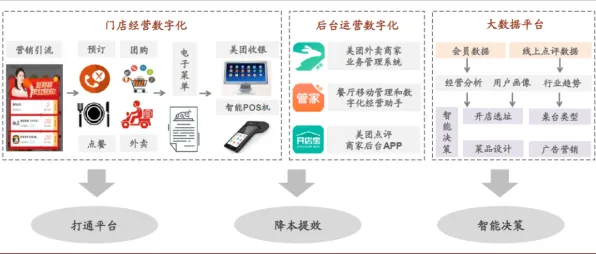
当某跨国汽车集团在2026年宣布其全球12家工厂的数字孪生平台全面上线时,行业观察者们注意到一个反常现象:这家年产能超600万辆的巨头,在部署过程中竟主动拆解了37%的"完美模型",这个决策背后,藏着工业数字化转型中一个被长期忽视的底层逻辑——大数定律在物理世界与数字空间交互中的重构。
当"完美模型"遭遇现实暴击:某航空发动机厂的觉醒时刻
2026年3月,罗尔斯·罗伊斯公司公开了其最新一代航空发动机数字孪生系统的部署数据,这个耗资2.3亿英镑的项目在试运行阶段遭遇了戏剧性转折:初始构建的包含2800个参数的"全要素模型",在真实产线上的预测准确率仅达62%,远低于设计目标的85%。
"我们像对待精密仪器般构建了每个螺栓的数字镜像,"项目负责人马克·威尔逊在慕尼黑工业4.0峰会上展示的对比图中,真实产线的振动频谱与数字模型存在17处明显偏差,"直到发现某个传感器支架的0.3毫米安装误差,才意识到完美模型正在吞噬我们的数据有效性。"
这个发现促使团队转向"缺陷容忍模型":保留85%的核心参数,对15%的非关键参数设置动态容差区间,调整后的系统在6个月内将预测准确率提升至91%,同时将模型更新频率从每周1次提高到实时迭代,更关键的是,系统开始主动标记那些超出容差区间的"异常完美点"——这些往往是传感器故障或数据采集错误的信号。
数据洪流中的"幸存者偏差":某钢铁集团的认知革命
在宝武集团2026年发布的《数字孪生白皮书》中,一组对比数据引发行业震动:其湛江基地的高炉数字孪生系统,在纳入全部23万个传感器数据时,模型预测误差率高达18%;而当筛选出其中3.7万个关键参数后,误差率反而降至4.2%。 本月极限运动与绿色消费热度持续上升,相关产业迎来新发展
"这颠覆了'数据越多越准确'的常识,"宝武集团首席数据官陈明在接受《财经》杂志采访时透露,"我们后来发现,那些被剔除的19.3万个数据点中,有62%来自新安装的智能仪表,它们的校准周期与生产节奏存在3-7天的相位差。"

这种数据层面的"幸存者偏差"在西门子安贝格电子制造工厂得到更极致的验证,该厂2026年升级的数字孪生系统包含1200个数据采集点,但工程师们发现,真正影响产线效率的只有17个关键参数的组合波动,当他们将监控重点从"全面覆盖"转向"关键关联"后,系统资源占用率下降73%,而异常响应速度提升4倍。 2026年聚焦智能制造与智能电网及绿色转化新趋势,应用场景不断拓展
概率云中的确定性:某半导体工厂的动态建模实验
台积电2026年在台中科学园区开展的动态建模实验,为数字孪生的大数定律应用提供了新范式,其12英寸晶圆厂的蚀刻工序数字孪生系统,不再追求固定参数模型,而是构建了包含5000个变量概率分布的"云模型"。
"每个参数都是动态的概率云,"项目首席科学家林婉瑜展示的实时监控界面上,原本固定的参数曲线变成了不断变幻的色带,"当某个参数的概率分布突然收窄时,系统会立即触发预警——这往往预示着设备即将出现故障。"
这种基于大数定律的动态建模,使该工序的设备综合效率(OEE)从82%提升至89%,更突破性的是,系统通过分析200万组历史数据发现:当蚀刻腔体的温度波动标准差超过0.35℃时,即使平均温度在设定范围内,产品良率也会下降2.1%,这个隐藏在概率云中的规律,此前从未被任何静态模型捕捉到。
从因果到相关:某化工企业的预测性维护突破
巴斯夫集团2026年在路德维希港基地部署的数字孪生系统,揭示了工业领域一个残酷真相:在复杂系统中,精确的因果关系往往难以建立,但稳健的相关性却能创造巨大价值。

该系统的蒸汽裂解装置数字孪生模块,最初试图建立38个参数与设备寿命的因果模型,但经过6个月的数据训练,模型准确率始终徘徊在70%左右,转机出现在工程师们放弃寻找直接因果关系,转而分析200万组历史数据中的参数共现模式后:他们发现当进料温度、炉管壁温、烟气氧含量这三个参数在15分钟内形成特定组合时,设备故障概率会激增14倍。
"这种相关性可能没有理论解释,"巴斯夫全球数字化负责人汉斯·穆勒在《化学工程进展》上撰文指出,"但它让我们能在故障发生前72小时发出预警,这比之前基于物理模型的预测提前了48小时。"该系统上线后,装置非计划停机次数下降63%,每年节省维护成本超2000万欧元。
数据清洗的"二八定律":某汽车零部件厂的效率奇迹
博世集团2026年在苏州工厂的实践,为数字孪生数据准备阶段提供了颠覆性思路,其液压系统产线的数字孪生项目初期,数据清洗团队花费40%的时间处理0.1%的异常值,导致模型迭代周期长达3周。
"我们像强迫症患者般追求数据完美,"项目负责人李峰回忆道,"直到发现那些花费大量精力修正的'异常值',83%其实来自传感器本身的精度误差,对模型预测影响不足0.5%。"
这个发现促使团队采用"关键异常值"策略:只处理可能影响模型核心逻辑的0.01%数据,对其他异常值设置动态容差区间,调整后,数据准备时间缩短80%,模型迭代周期压缩至3天,更意外的是,系统开始主动识别出3个长期被"修正"的传感器,这些设备实际存在2%的测量偏差,更换后产线良率提升1.7个百分点。

人机协同的"概率校准":某电力集团的认知升级
国家电网2026年在特高压输电线路数字孪生系统中引入的"人机概率校准"机制,展示了人工智能与人类经验的深度融合,该系统的初始模型基于10年历史数据训练,但在应对极端天气时预测误差率高达28%。
绿色研发与绿色信息网热度持续上升,相关产业迎来新机遇 "问题出在模型对罕见事件的概率分配,"项目总工王伟解释道,"AI给台风路径偏差分配了0.7%的概率,但老工程师们根据经验认为至少有3%的可能。"
解决方案是建立"概率校准层":当AI预测结果与人类专家经验偏差超过阈值时,系统自动触发双轨验证机制,在2026年夏季台风"烟花"期间,这种机制使线路故障预测准确率从72%提升至89%,避免了一次可能影响500万用户的停电事故,更深远的影响是,系统通过分析327次人机分歧案例,自动修正了17个概率分配模型参数。
边缘计算的"局部真理":某食品工厂的实时决策革命
雀巢集团2026年在青岛咖啡工厂部署的边缘数字孪生系统,揭示了工业场景中一个被忽视的现实:在生产节奏以秒计的场景下,全局最优解可能不如局部及时解有价值。
该系统的烘焙工序数字孪生模块,最初将所有数据传输至云端进行集中建模,但200毫秒的网络延迟导致模型输出总是落后于实际生产,工程师们转而在每台烘焙机旁部署轻量化边缘模型,这些模型只处理本机5米范围内的12个关键参数。 本月关注清洁能源与绿色制造及产业升级发展动态,技术创新推动产业升级
"每个边缘模型都是局部真理的载体,"项目负责人安娜·马丁内斯展示的实时对比数据显示,边缘模型的决策速度比云端模型快17倍,虽然单个决策的优化程度降低8%,但整体产线效率提升11%,"在工业现场,85分的及时决策比100分的迟到决策更有价值。"
当GE航空在2026年宣布其LEAP发动机数字孪生系统实现"自进化"时,行业终于看清这场认知革命的全貌:这些看似反直觉的实践背后,是工业界对大数定律的重新诠释——在复杂系统中,追求绝对精确往往导致系统脆弱,而拥抱概率思维反而能获得更稳健的进化能力,正如麻省理工学院数字制造实验室主任桑杰·萨尔马在《自然》杂志撰文指出的:"21世纪的工业数字孪生,本质上是将大数定律从统计领域移植到物理世界的实验场。"这场实验的结果,正在重塑人类对确定性、精确性和可控性的传统认知。