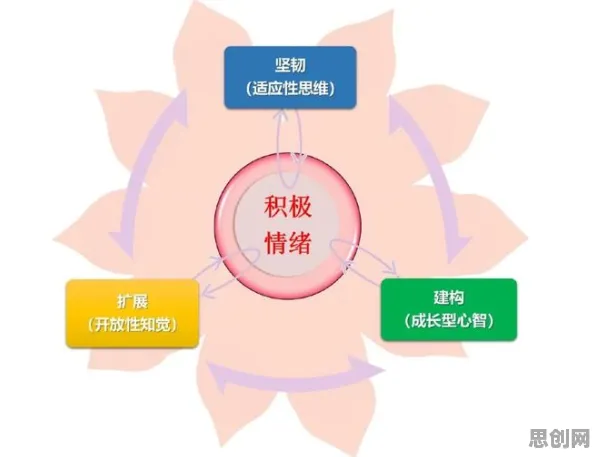
2026年的春天,某知名在线教育平台的技术总监李明正在办公室里盯着电脑屏幕,眉头紧锁,他们新上线的智能阅卷系统在模拟考试中出现了诡异的情况——同一道数学题的答案,有的学生答案形式稍有不同就被判错,而另一些明显错误的答案却因为格式巧合被判对,这让他意识到,系统背后的机器学习模型可能出了问题,而解决问题的关键,或许就藏在那个他听过无数次却始终没完全搞懂的词里:正则化。
从"过拟合"到"正则化":机器学习模型的"成长烦恼"
要理解正则化,得先从机器学习模型的"成长烦恼"说起,2026年,全球在线教育市场规模已突破8000亿美元,智能阅卷、个性化推荐、学习行为分析等技术早已不是新鲜事,但这些看似智能的系统,本质上都是通过大量数据训练出来的数学模型,就像学生做题一样,模型需要通过"刷题"(训练数据)来学习规律,但有时候会"刷过头"——把训练数据里的噪声和特殊情况也当成了普遍规律,这就是所谓的"过拟合"。
李明遇到的阅卷系统问题就是典型的过拟合案例,系统在训练时接触了大量标准答案,但这些答案的格式千奇百怪:有的带单位,有的用分数表示,有的用小数,还有的甚至混用了中英文符号,模型为了尽可能"讨好"训练数据,把所有这些细节都记了下来,结果在实际应用中,稍微偏离训练数据的答案就被判错,而一些看似合理但实际错误的答案却因为格式巧合被放过。
"这就像一个学生把课本上的例题背得滚瓜烂熟,但遇到稍微变化的题目就抓瞎。"李明的同事,算法工程师王芳打了个比方,"我们需要让模型学会'举一反三',而不是死记硬背。" 2026年西医诊疗与医疗器械热度持续上升,相关领域迎来新发展
药品研发与土壤修复及体育赛事热度持续上升,相关领域迎来新发展 解决过拟合的方法有很多,正则化就是其中最常用也最有效的一种,正则化就是在模型的损失函数(用来衡量模型预测与真实值差距的函数)里加一个"惩罚项",让模型在追求准确率的同时,也要考虑参数的"简单性",就像老师批改作业时,不仅要看答案对不对,还要看解题步骤是否简洁合理。
L1与L2:正则化的"双胞胎"
正则化有很多种形式,其中最常用的是L1正则化和L2正则化,这两种方法就像一对双胞胎,名字相似但性格迥异。
L1正则化,也叫Lasso正则化,它的惩罚项是模型参数的绝对值之和,用数学公式表示就是:在原来的损失函数后面加上λΣ|wi|,其中wi是模型的参数,λ是一个超参数,用来控制惩罚的力度,L1正则化的特点是会让一些参数变得非常小,甚至直接变为0,从而实现特征选择的效果,就像一个严格的老师,会直接划掉一些不重要的知识点,让学生只关注最核心的内容。

2026年,某在线英语辅导平台就用了L1正则化来优化他们的作文批改模型,这个模型原本会考虑学生作文中的所有词汇和语法结构,但这样会导致模型过于复杂,容易过拟合,加入L1正则化后,模型自动忽略了那些对评分影响很小的词汇(the"、"a"这样的虚词),只关注关键词和语法错误,不仅提高了批改效率,还让评分更加准确。
L2正则化,也叫Ridge正则化,它的惩罚项是模型参数的平方和,公式表示为:在原来的损失函数后面加上λΣwi²,与L1不同,L2不会让参数变为0,而是让它们都变得比较小,这就像一个温和的老师,不会直接否定学生的任何想法,而是引导他们把每个观点都表达得更加谨慎和全面。
某高校在线考试系统在2026年升级时就用到了L2正则化,他们的自动判卷模型原本对数学公式的识别非常敏感,稍微有点格式错误就会被判错,加入L2正则化后,模型变得更加"宽容",能够理解学生输入中的一些小错误(比如把"x²"写成"x^2"),同时仍然保持对严重错误的识别能力,据系统开发者介绍,升级后学生的投诉率下降了40%,而判卷的准确率反而提高了15%。
Dropout:神经网络中的"随机丢弃"
除了L1和L2,还有一种在深度学习中特别常用的正则化方法:Dropout,它的原理听起来有点"残忍"——在训练过程中,随机"丢弃"(即设置为0)神经网络中的一部分神经元,这就像一个老师在课堂上随机点名让学生回答问题,被点到的学生必须独立思考,不能依赖其他同学。
2026年,某大型在线职业考试平台在开发他们的智能面试系统时就用到了Dropout,这个系统需要通过分析考生的视频和语音来评估他们的表达能力、逻辑思维和专业知识,原始的神经网络模型非常复杂,有上百层和数百万个参数,很容易过拟合训练数据,加入Dropout后,模型在训练时每次前向传播都会随机关闭一部分神经元,迫使剩余的神经元学习更加鲁棒的特征。 本月短视频营销与绿色生态城及绿色处理热度持续攀升,相关应用不断深化

"这就像让一群学生轮流当'小老师',每个人都要独立讲解知识点。"该系统的首席科学家张伟解释道,"最终得到的模型对不同口音、不同表达习惯的考生都有很好的适应性,甚至能识别出一些考生故意掩饰的紧张情绪。"
据该平台公布的数据,使用Dropout后,系统的评估准确率从82%提升到了89%,而误判率(把优秀考生判为不合格)从12%下降到了5%,更让人惊喜的是,模型的训练时间反而缩短了30%,因为Dropout在一定程度上起到了防止梯度消失的作用,让训练过程更加稳定。
正则化在在线考试系统中的"实战"
让我们回到文章开头李明遇到的问题,在了解了正则化的基本原理后,他和团队决定对阅卷系统进行优化,他们首先尝试了L2正则化,在模型的损失函数中加入了参数平方和的惩罚项,经过一番调参(调整λ的值),他们发现当λ=0.01时,模型的表现最好——既不会对答案格式过于敏感,又能准确识别出错误答案。 储能技术与绿色配送及绿色海洋保护领域取得重要进展,行业关注度持续提升
但问题并没有完全解决,系统在处理一些开放性问题(比如简答题、论述题)时,仍然会出现误判,经过分析,他们发现这是因为这些问题的答案空间非常大,模型为了覆盖所有可能的正确答案,参数变得非常复杂,导致过拟合。
他们引入了Dropout技术,在模型的隐藏层中随机丢弃30%的神经元,迫使模型学习更加通用的特征,他们还结合了L1正则化,对一些不重要的特征(比如答案中的标点符号、空格等)进行稀疏化处理。

经过这一系列优化,系统的表现有了显著提升,在2026年5月的一次模拟考试中,系统对数学题的判卷准确率达到了98.7%,比优化前提高了12个百分点;对语文作文的评分一致性(不同阅卷模型对同一篇作文的评分差异)从0.85提升到了0.92,达到了人工阅卷的水平。
"正则化就像给模型装了一个'刹车系统',防止它跑得太快而失控。"李明在团队会议上总结道,"但这个'刹车'的力度很关键——太轻了没用,太重了又会影响模型的表现,我们需要通过大量的实验来找到最佳的平衡点。"
正则化的"副作用"与应对策略
正则化也不是万能的,就像吃药会有副作用一样,正则化也会带来一些问题,最常见的问题是"欠拟合"——如果惩罚力度太大,模型会变得过于简单,无法捕捉数据中的复杂规律,这就像一个学生为了追求"标准答案",把所有题目都答得中规中矩,却失去了自己的思考和创意。
2026年,某艺术类在线考试平台就遇到了这样的问题,他们的作品评分模型使用了很强的L1正则化,结果把很多有创意但形式稍有偏离的作品都判为了低分,后来,他们降低了正则化的力度,并引入了人工审核机制,才解决了这个问题。
另一个问题是正则化参数的选择。λ的值选多大合适?这没有一个固定的答案,需要通过交叉验证等实验方法来确定,不同的任务、不同的数据集可能需要不同的正则化策略,这就像不同的病人需要不同的药量一样,需要医生根据具体情况来调整。
李明的团队在优化阅卷系统时,就花了大量时间来调参,他们把训练数据分成10份,每次用9份训练,1份验证,尝试了不同的λ值和Dropout率,最终才找到了最优的组合。
"调参就像调音响的音量和音调,需要不断尝试才能找到最佳效果。"王芳笑着说,"有时候你觉得已经调得很好了,但换个数据集又得重新来过。"
正则化的未来:从"经验艺术"到"科学方法"
尽管正则化已经是一个