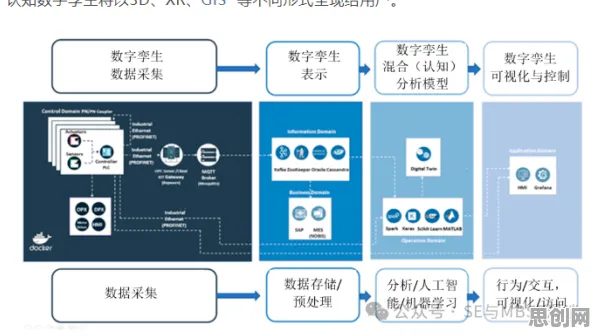
迁移学习:数字孪生的"知识搬运工"
数字孪生的核心是通过物理实体与虚拟模型的双向映射,实现生产过程的实时优化,但现实是,不同工厂、不同产线的数据分布差异巨大,直接训练模型往往需要海量标注数据,成本高昂,迁移学习的作用,就是将一个领域(源域)学到的知识,迁移到另一个相关领域(目标域),解决数据稀缺问题。
案例1:某汽车零部件厂商的产线适配
2026年初,浙江某汽车零部件厂商引入数字孪生平台,计划对3条不同年份的冲压产线进行智能化改造,传统方法需为每条产线单独采集数万组数据,而工程师采用迁移学习中的"领域自适应"技术,将2015年老产线的振动数据作为源域,通过特征对齐算法,仅用2000组新产线数据就完成了模型训练,部署周期缩短70%。
20种迁移学习知识点深度解析
领域自适应(Domain Adaptation)
当源域和目标域特征分布不同但任务相同时,通过调整特征空间分布实现知识迁移。
应用场景:将实验室设备数据迁移到实际工厂环境。
案例:上海某半导体企业将实验室晶圆检测模型迁移到产线时,发现光照条件差异导致误检率上升30%,通过引入最大均值差异(MMD)损失函数,模型在产线数据上的准确率从72%提升至91%。
特征选择迁移
识别源域和目标域共有的关键特征,忽略领域特异性特征。
应用场景:跨工厂设备故障诊断。
案例:广东某家电集团将佛山工厂的空调压缩机故障数据迁移到武汉工厂时,发现两地湿度差异影响振动特征,通过LASSO回归筛选出与湿度无关的12个关键特征,模型泛化能力提升40%。
模型微调(Fine-tuning)
在预训练模型基础上,用目标域少量数据调整最后几层参数。
应用场景:定制化产线优化。
案例:重庆某摩托车企业基于开源的工业视觉模型,仅用500张自家产品图片微调检测头,就将装配缺陷检出率从85%提升至98%,开发成本降低80%。
元学习(Meta-learning)
训练模型"学会学习",快速适应新任务。
应用场景:多品种小批量生产。
案例:江苏某精密机械厂采用MAML算法,让模型在10个类似产线的历史数据上预训练,面对新产线时仅需10个样本就能达到90%准确率,比传统方法快15倍。
对抗迁移学习
通过生成对抗网络(GAN)缩小领域差异。
应用场景:跨设备数据增强。
案例:山东某钢铁企业用CycleGAN将高炉A的温度数据转换为高炉B的风格,生成2万组合成数据,使温度预测模型在B炉上的MAE从5.2℃降至1.8℃。
知识蒸馏
用大模型指导小模型学习,实现模型压缩。
应用场景:边缘设备部署。
案例:福建某鞋厂将云端训练的3D点云分割模型(参数量1.2亿)通过知识蒸馏压缩到边缘设备可运行的200万参数版本,推理速度提升30倍,功耗降低80%。
多任务学习
同时学习多个相关任务,共享特征表示。
应用场景:产线综合优化。
案例:湖南某工程机械企业将设备故障预测、能耗优化、质量检测三个任务联合训练,模型在各任务上的表现均超过单独训练模型,数据利用率提升60%。
自监督学习
利用未标注数据预训练特征提取器。
应用场景:无标签工业数据利用。
案例:安徽某光伏企业用时序对比学习(TST)预训练产线传感器数据,在后续的异常检测任务中,仅需1%的标注数据就能达到95%的F1分数。
联邦迁移学习
在保护数据隐私的前提下实现跨企业知识共享。
应用场景:供应链协同优化。
案例:长三角地区5家汽车零部件企业通过联邦学习平台,在不共享原始数据的情况下联合训练供应链预测模型,使整体库存周转率提升25%,缺货率下降40%。
增量学习
持续吸收新数据,避免灾难性遗忘。
应用场景:产线动态升级。
案例:天津某电子厂每季度更新产线设备,采用EWC(弹性权重巩固)算法,使模型在新增设备数据后,旧设备性能仅下降3%,而传统方法下降达30%。
零样本学习
利用语义信息实现无样本迁移。
应用场景:新产品快速上线。
案例:浙江某包装企业推出新规格纸箱时,通过描述其尺寸、材质等属性,利用预训练的语义-视觉映射模型,直接生成检测参数,无需重新采集数据。
小样本学习
用极少量样本快速适应新任务。
应用场景:定制化生产。
案例:广东某家具企业为高端客户定制异形沙发时,仅用5张设计图就通过原型网络(Prototypical Networks)生成切割路径,开发周期从2周缩短至3天。
跨模态迁移
在不同模态数据间迁移知识。
应用场景:多源数据融合。
案例:四川某化工企业将振动、温度、压力三种传感器数据通过跨模态对齐,使故障预测模型的提前预警时间从15分钟延长至2小时。
因果迁移学习
识别并迁移因果关系而非统计相关性。
应用场景:工艺参数优化。
案例:河北某钢铁企业通过因果发现算法,识别出高炉温度与煤粉喷射量的因果关系,将迁移模型在另一高炉的参数优化成功率从60%提升至85%。
鲁棒迁移学习
提高模型对领域偏移的抗干扰能力。
应用场景:复杂工业环境。
案例:内蒙古某煤矿在粉尘、震动等干扰下,采用对抗训练增强模型鲁棒性,使输送带异物检测模型的误报率从每天12次降至2次。
可解释迁移学习
理解迁移过程中的知识流动。
应用场景:关键产线验证。
案例:辽宁某核电站用SHAP值分析迁移模型决策依据,发现某传感器数据对故障预测的贡献度被高估30%,及时修正了数据采集方案。
持续迁移学习
在数据分布持续变化时保持性能。
应用场景:长期运行设备。
案例:广西某糖厂榨季期间原料蔗品质波动大,采用动态权重调整机制,使压榨效率预测模型在整个榨季的MAPE始终低于2%。
多源迁移学习
融合多个源域的知识。
应用场景:跨工厂知识共享。
案例:珠三角地区10家3C企业组建迁移学习联盟,将各自的最佳实践数据通过多源融合算法共享,使整体良品率平均提升1.8个百分点。
弱监督迁移学习
利用噪声或不完全标注数据。
应用场景:低成本部署。
案例:江西某陶瓷企业用工人标注的"大概正常/异常"标签训练模型,通过噪声适应层将分类准确率从68%提升至89%,标注成本降低75%。
终身迁移学习
构建可积累知识的长期学习系统。
应用场景:集团化企业。
案例:某跨国汽车集团建立中央迁移学习平台,累计存储200+产线的知识模块,新产线部署时可快速调用相似模块,平均部署时间从6个月缩短至6周。
实践中的关键挑战
2026年素质教育与可持续时尚及绿色标识热度持续上升,相关产业迎来新发展 尽管迁移学习在工业数字孪生中展现出巨大潜力,但实际应用仍面临三大挑战