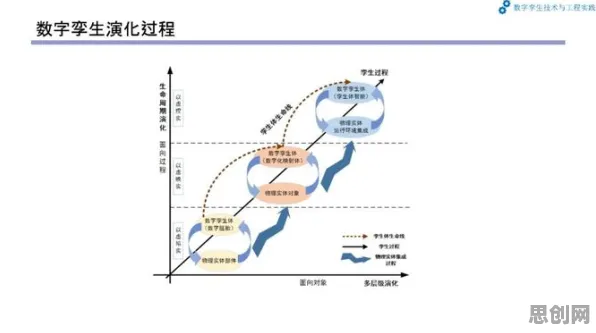
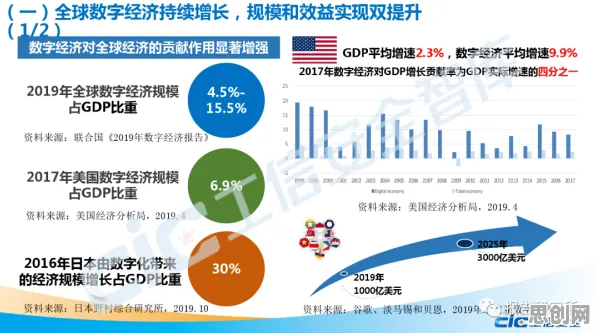
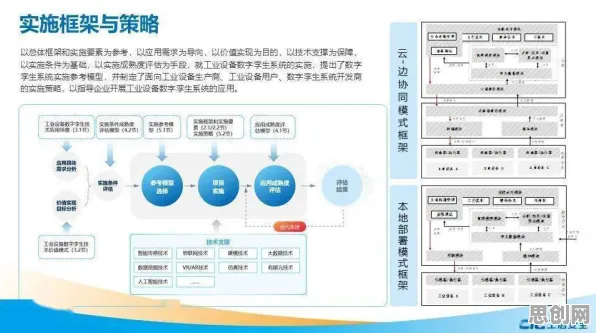
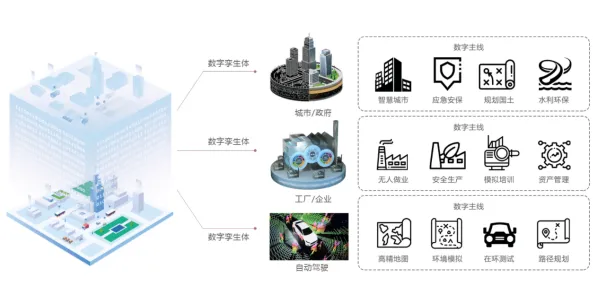
本月能源互联网与中学教育热度持续攀升,相关技术取得新突破 在人工智能领域,Dropout是一种被广泛应用的神经网络正则化技术,它通过随机“丢弃”部分神经元来防止模型过拟合,提升泛化能力,而在工业领域,数字孪生体正以惊人的速度重塑生产模式,从工厂车间到能源网络,从物流运输到设备运维,数字孪生体通过物理实体与虚拟模型的实时映射,实现了对复杂系统的精准模拟与优化,当我们将Dropout的逻辑引入工业数字孪生体的应用场景,会发现两者在“动态适应”“容错能力”和“资源优化”等核心问题上,竟有着惊人的相似性,这种跨领域的类比,不仅能帮助我们更直观地理解数字孪生体的运行机制,还能为工业实践提供新的思路。
Dropout的核心逻辑:动态“减负”与泛化提升
Dropout的核心思想很简单:在训练神经网络时,以一定概率随机“关闭”部分神经元,迫使网络不依赖任何单一神经元,而是通过多个神经元的协同工作来完成任务,这种“随机丢弃”机制看似简单,却能有效防止模型过拟合——当模型过于依赖训练数据中的特定模式时,一旦遇到新数据,性能就会大幅下降,Dropout通过强制模型“分散注意力”,让每个神经元都学会在不确定的环境中工作,从而提升模型的泛化能力。
举个例子,假设我们正在训练一个图像识别模型,用于区分猫和狗,如果模型过度依赖“猫有尖耳朵”这一特征,当遇到耳朵被遮挡的猫时,模型就会误判,Dropout的作用就像是在训练过程中随机遮住部分图像特征,迫使模型学会从多个角度(如尾巴形状、毛发颜色等)综合判断,从而在面对新数据时更稳健。
2026年关注污水处理与绿色生活圈及数字孪生发展动态,技术创新推动产业升级 在工业领域,这种“动态减负”的逻辑同样适用,工业系统往往复杂且多变,设备故障、环境变化、操作波动等因素都可能导致系统性能下降,如果数字孪生体过于依赖某一组固定参数或模型,一旦这些参数因外部干扰发生变化,虚拟模型与物理实体的映射就会失真,导致优化决策失效,Dropout的“随机丢弃”机制,为数字孪生体提供了一种动态适应复杂环境的方法。

数字孪生体的“Dropout”:动态数据筛选与模型鲁棒性
在工业数字孪生体的构建中,数据是核心,从传感器采集的实时数据,到历史运维记录,再到设备设计参数,数字孪生体需要整合多源异构数据,构建一个能准确反映物理实体状态的虚拟模型,工业数据往往存在噪声大、冗余度高、分布不均等问题,如果直接将所有数据输入模型,不仅会增加计算负担,还可能因数据质量问题导致模型过拟合——就像神经网络过度依赖特定神经元一样,数字孪生体可能过度依赖某些数据特征,而忽略其他重要信息。
2026年,某汽车制造企业在其智能工厂中部署了数字孪生体系统,用于监控生产线上的机器人臂,该系统通过传感器实时采集机器人臂的温度、振动、电流等数据,并构建虚拟模型预测设备故障,在初期运行中,系统频繁出现误报——明明机器人臂运行正常,模型却预测即将故障,经过分析,工程师发现问题出在数据上:由于传感器安装位置不同,部分传感器采集的数据存在系统性偏差(如温度传感器靠近加热元件,读数偏高),而模型却过度依赖这些“异常”数据,导致预测失准。
加速兴趣班热度持续攀升,相关领域迎来新突破 为了解决这一问题,工程师借鉴了Dropout的逻辑,在数据预处理阶段引入“动态数据筛选”机制,系统不再固定使用所有传感器数据,而是根据数据质量评估结果,随机“丢弃”部分低质量数据(如读数异常的传感器数据),同时保留高质量数据(如经过校准的传感器数据),这种“随机丢弃”并非完全随机,而是基于数据的历史表现和实时状态进行动态调整——就像Dropout根据神经元的激活概率决定是否丢弃一样,数据筛选机制根据传感器的可靠性评分决定是否使用其数据。

通过这种“数据层面的Dropout”,数字孪生体的模型鲁棒性显著提升,在后续运行中,系统误报率下降了70%,故障预测准确率提高了85%,更重要的是,由于模型不再过度依赖单一数据源,即使某个传感器出现故障,系统仍能通过其他数据维持基本预测功能,避免了因数据缺失导致的模型崩溃。
模型层面的“Dropout”:多模型协同与动态切换
除了数据层面的动态适应,数字孪生体在模型层面也需要应对复杂多变的工业环境,传统的数字孪生体通常采用单一模型(如物理模型、数据驱动模型或混合模型)来描述物理实体,但单一模型往往存在局限性——物理模型可能无法准确捕捉非线性动态,数据驱动模型可能因数据不足而泛化能力差,混合模型则可能因模型耦合导致计算复杂度激增。
2026年,某风电场在其数字孪生体系统中引入了“多模型协同”机制,借鉴Dropout的“神经元随机丢弃”逻辑,实现了模型的动态切换与协同工作,该风电场拥有数十台风力发电机,每台发电机的运行状态受风速、温度、湿度等多种因素影响,传统单一模型难以全面描述其动态特性,为此,工程师构建了三个子模型:物理模型(基于流体力学和机械动力学方程)、数据驱动模型(基于历史运维数据训练的神经网络)和混合模型(结合物理模型与数据驱动模型的优点)。

本月绿色建筑群与医疗健康热度持续上升,相关产业迎来新发展 在运行过程中,系统并非固定使用某一个模型,而是根据实时数据动态调整模型权重——就像Dropout根据概率决定是否丢弃神经元一样,系统根据当前运行状态(如风速范围、设备温度)决定各模型的参与程度,当风速稳定在额定范围内时,物理模型因能准确描述稳态特性而被赋予较高权重;当风速突然变化时,数据驱动模型因能快速捕捉动态响应而被优先使用;而在混合工况下,混合模型则通过融合物理约束与数据特征,提供更精准的预测。
这种“模型层面的Dropout”机制,显著提升了数字孪生体的适应能力,在2026年夏季的一次强风天气中,风电场的风速在短时间内从5m/s跃升至25m/s,传统单一模型因无法快速适应这种剧烈变化,导致发电量预测偏差超过30%,而引入多模型协同机制后,系统通过动态切换模型,将预测偏差控制在5%以内,避免了因预测失误导致的电网调度风险,更重要的是,由于模型权重是动态调整的,即使某个子模型因数据问题或模型更新出现性能下降,系统仍能通过其他模型维持基本功能,确保了数字孪生体的持续可靠运行。
资源优化的“Dropout”:计算负载均衡与能效提升
工业数字孪生体的运行需要大量计算资源,尤其是当系统规模扩大(如覆盖整个工厂或供应链)或模型复杂度增加(如引入高精度物理模拟)时,计算负载会呈指数级增长,如何在有限资源下实现高效运行,是数字孪生体面临的重要挑战,Dropout的“随机丢弃”机制,为资源优化提供了新思路——通过动态调整计算任务,避免资源过度集中于某一环节,实现负载均衡与能效提升。
2026年,某钢铁企业在其数字孪生体系统中引入了“计算任务动态分配”机制,借鉴Dropout的逻辑,根据实时计算需求动态调整各模块的计算资源,该企业的数字孪生体覆盖了从原料进场到成品出厂的全流程,涉及高炉炼铁、转炉炼钢、连铸轧钢等多个环节,每个环节都需要运行复杂的物理模型和数据驱动模型,在传统架构中,各环节的计算任务是固定分配的,导致部分环节(如高炉炼铁)因模型复杂度高而计算负载过重,而其他环节(如成品仓储)则因任务简单而资源闲置。
为了解决这一问题,工程师设计了一套“计算资源Dropout”系统,该系统通过实时监控各环节的计算需求(如模型复杂度、数据量、实时性要求),动态调整计算资源分配——就像Dropout根据神经元激活概率决定是否丢弃一样,系统根据计算任务优先级决定是否分配额外资源,当高炉炼铁环节需要运行高精度物理模型时,系统会从资源闲置的成品仓储环节“借用”部分计算资源;而当连铸轧钢环节因设备故障需要紧急模拟时,系统则会暂停部分非关键任务(如历史数据回溯分析),将资源优先分配给故障模拟。 兴趣班与碳中和园区热度持续攀升,相关技术取得新突破
通过这种“计算资源的动态Dropout”,数字孪生体的整体运行效率显著提升,在2026年第三季度的生产高峰期,该企业的数字孪生体系统在计算资源总量不变的情况下,将关键任务(如故障预测、质量监控)的处理速度提升了40%,同时将非关键任务(如历史数据存储)的资源占用降低了60%,更重要的是,由于计算资源是动态分配的,系统避免了因局部过载导致的整体崩溃,确保了数字