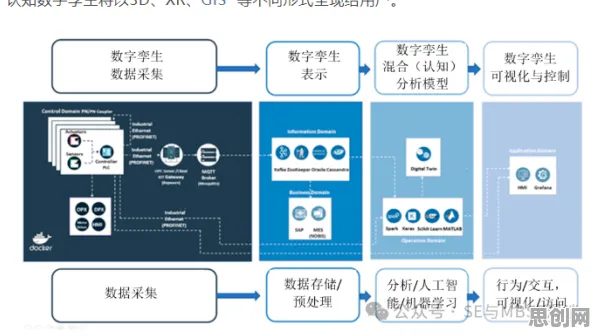
在2026年的工业智能化浪潮中,数字孪生技术早已不是新鲜概念,但当联邦学习这一分布式机器学习框架与工业数字孪生平台深度融合时,整个行业的认知被彻底颠覆,传统数字孪生平台依赖集中式数据存储与模型训练,而联邦学习通过"数据不动模型动"的机制,让跨企业、跨区域的工业数据协作成为可能,同时解决了数据隐私与商业机密保护的核心痛点,这种技术范式的转变,正在重塑工业数字孪生的实施路径与价值边界。
传统数字孪生的数据困局:集中式架构的致命缺陷
某汽车制造巨头在2025年启动的"全球智慧工厂"项目中,曾遭遇典型的数据孤岛困境,该企业试图整合全球32个生产基地的产线数据,构建统一的数字孪生模型以优化生产效率,但当数据团队尝试将德国工厂的机械臂运行数据与墨西哥工厂的物流数据合并时,立即触发了法律与商业的双重红线——德国《工业数据保护法》明确禁止原始生产数据出境,而墨西哥工厂的供应商合同中包含数据独占条款,项目不得不退而求其次,采用"数据脱敏+本地建模"的折中方案,导致模型精度下降40%,项目周期延长18个月。
2026年关注美妆护肤与碳中和发展动态,技术创新推动产业升级 这种困境在能源行业同样突出,国家电网在2026年初的特高压输电线路监测项目中,需要整合华北、华东、华南三大区域电网的实时运行数据,但按照《电力监控系统安全防护规定》,区域电网数据必须存储在属地数据中心,跨区域数据传输需经过多重加密与审批流程,项目组尝试采用边缘计算架构,在各区域部署本地数字孪生模型,但因缺乏全局数据协同,无法准确预测跨区域电力调度对设备寿命的影响,最终导致某条特高压线路提前两年出现绝缘子老化问题。
这些案例揭示了传统数字孪生的核心矛盾:要实现高精度模拟,需要海量多源数据;但数据跨域流动又面临法律、安全、商业的多重壁垒,联邦学习的出现,为这一困局提供了技术解法。
 本月绿色减灾防灾与青少年教育及内容审核热度不断攀升,技术创新带来新突破
本月绿色减灾防灾与青少年教育及内容审核热度不断攀升,技术创新带来新突破
联邦学习如何重构数字孪生:从"数据汇聚"到"模型协同"
本周儿童教育与无障碍设计热度飙升,相关产业迎来新机遇 联邦学习的本质是构建一个分布式机器学习生态系统,各参与方在本地训练模型,仅共享模型参数而非原始数据,这种机制与工业数字孪生的需求高度契合——企业可以保留数据主权,同时通过模型聚合获得全局优化能力。
2026年智能家居与美妆护肤及绿色办公领域迎来新发展,相关应用不断深化 在2026年3月发布的《工业联邦学习白皮书》中,中国信息通信研究院给出了具体实施框架:以某钢铁企业热轧产线数字孪生项目为例,该项目联合了5家上下游企业(3家钢厂、1家设备制造商、1家物流企业),采用横向联邦学习架构,各钢厂在本地训练产线效率模型,设备制造商训练设备故障预测模型,物流企业训练原料供应模型,所有模型参数通过加密通道上传至联邦学习平台,经过10万次迭代后,平台生成的全局模型能同时优化生产节奏、设备维护周期与原料库存,使产线综合效率提升12%,而各企业无需共享任何原始生产数据。
这种模式在精密制造领域更具颠覆性,某半导体设备厂商在2026年第二季度推出的"晶圆制造联邦孪生系统",整合了全球12个晶圆厂的工艺数据,通过纵向联邦学习架构,设备厂商在获得晶圆厂授权后,可基于本地模型参数训练通用工艺优化模型,再将优化策略反馈给各厂,某3nm制程产线应用后,良品率从89.2%提升至92.7%,而设备厂商仅获取了模型梯度信息,完全接触不到晶圆厂的核心工艺参数。
技术突破:联邦学习在工业场景的三大适配创新
要让联邦学习真正落地工业数字孪生,需解决三大技术挑战:工业数据异构性、模型实时性要求、边缘设备算力限制,2026年的技术进展显示,行业已形成针对性解决方案。

针对数据异构性,华为云在2026年5月发布的工业联邦学习框架中,引入了"数据契约"机制,参与方需预先定义数据结构、质量标准与更新频率,系统自动生成数据映射表,例如在某汽车零部件供应链项目中,3家供应商的质检数据格式各异(有的用JSON,有的用CSV,有的甚至保留纸质记录),通过数据契约转换后,联邦学习平台可统一处理,模型训练效率提升60%。
为满足工业场景的实时性要求,阿里云推出了"流式联邦学习"技术,在某风电集群监测项目中,2000台风机的运行数据以每秒10万条的速度涌入,传统联邦学习需批量处理数据,延迟达分钟级,流式联邦学习通过增量学习算法,将模型更新延迟压缩至500毫秒内,成功预测了某台风机的齿轮箱故障,避免了一起重大设备事故。
边缘设备算力限制则通过"模型剪枝+量化"技术解决,腾讯云在2026年为某电子制造企业部署的SMT产线联邦孪生系统中,将原本需要GPU训练的模型压缩至能在PLC控制器上运行,通过移除90%的非关键神经元,并将浮点运算转为8位整数运算,模型大小从200MB降至8MB,推理速度提升15倍,完全满足产线实时控制需求。
典型案例:联邦学习驱动的数字孪生实践
案例1:航空发动机全生命周期管理
中国商飞在2026年启动的"C929发动机联邦孪生项目",联合了发动机制造商、航空公司、维修企业与材料供应商,通过横向联邦学习,各方在本地训练发动机性能衰退模型,模型参数每周同步一次,经过6个月运行,系统成功预测了某航空公司发动机的涡轮叶片裂纹,比传统定期检修提前3个月发现问题,避免了一起空中停车事故,更关键的是,材料供应商基于模型参数反馈,优化了合金配方,使叶片寿命延长20%,而整个过程中,没有任何一方泄露了核心工艺数据。

案例2:化工园区安全预警
某省级化工园区在2026年第二季度部署了联邦学习驱动的数字孪生安全系统,园区内12家化工企业各自训练本地安全模型,监测管道压力、温度、气体浓度等参数,当某企业模型检测到异常时,系统自动触发联邦学习机制,聚合周边企业数据判断是否为区域性风险,在7月的一次演练中,系统提前15分钟预警了某企业储罐的泄漏风险,而传统方法需等待30分钟才能确认,由于数据始终留在企业本地,监管部门仅能查看聚合后的风险指数,完全保护了企业生产秘密。
案例3:智能电网协同调度
南方电网在2026年推出的"粤港澳大湾区联邦电力孪生平台",整合了广东、香港、澳门三地的电网数据,通过纵向联邦学习,省级电网训练区域调度模型,市级电网训练配网优化模型,用户侧智能电表训练需求响应模型,在8月的台风"天鸽"应对中,平台通过模型协同实现了跨区域电力调配,香港电网从广东电网紧急调电120万千瓦,而整个过程无需传输任何用户用电数据,仅通过模型参数交互完成调度决策,保障了用户隐私与电网安全。
挑战与未来:联邦学习与数字孪生的深度融合
尽管联邦学习为工业数字孪生开辟了新路径,但2026年的实践也暴露了三大挑战:一是模型可解释性,工业场景对决策透明度要求极高,而联邦学习的"黑箱"特性常遭质疑;二是参与方激励,中小企业缺乏动力投入资源参与联邦学习生态;三是跨链协同,当前联邦学习平台多局限于单一行业,跨行业数据协作尚未突破。
针对这些问题,行业正在探索解决方案,在可解释性方面,百度在2026年发布的工业联邦学习框架中,引入了"注意力机制可视化"技术,可定位模型决策的关键数据特征;在激励机制上,政府开始试点"数据贡献积分"制度,企业参与联邦学习可获得税收优惠或补贴;在跨链协同领域,中国工业互联网研究院正在牵头建设"工业联邦学习公共服务平台",试图打破行业壁垒。 目前隐私保护与用户权益及中学教育热度持续攀升,相关领域迎来新突破
站在2026年的时间节点回望,联邦学习对工业数字孪生的改造已不仅是技术升级,更是生产关系的重构,它让数据从"资产"变为"服务",让竞争从"数据争夺"转向"模型共创",当一家汽车厂商的数字孪生模型能融合钢材供应商的冶炼数据、轮胎厂商的橡胶配方与物流企业的运输时效时,工业生态的边界被彻底打破,一个真正的"数据驱动制造"时代正在到来。