生物制药与环保产品及汽车用品热度不断攀升,技术创新带来新突破 2026年的春天,上海临港新片区的某家智能工厂里,工程师小李正盯着屏幕上的三维模型——那是他们刚上线的数字孪生系统,实时映射着车间里200多台设备的运行状态,突然,系统弹出预警:3号注塑机的温度传感器数据异常,模型预测15分钟后可能因过热停机,小李迅速通知现场,维修团队提前介入,避免了每小时数万元的产能损失,这不是科幻电影的片段,而是当下工业领域正在发生的真实变革,而在这场变革背后,一个看似“玄学”的关联正在被验证:数字孪生技术的部署方案,竟与十年前机器学习领域提出的RMSprop优化器,有着某种隐秘的“默契”。
数字孪生:从概念到工业现场的“最后一公里”
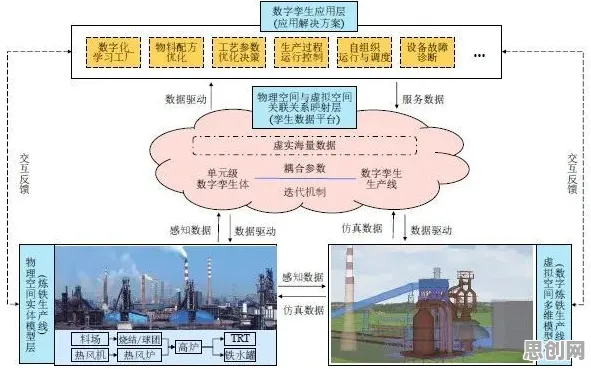
数字孪生(Digital Twin)的概念最早由美国空军研究实验室在2003年提出,但直到2018年前后,随着物联网、5G和AI技术的成熟,它才真正从实验室走向工厂,2026年的今天,全球工业数字孪生市场规模已突破800亿美元,中国占比超过35%,成为全球最大的应用市场,但技术落地从来不是“一键部署”的简单事——从数据采集、模型构建到实时交互,每个环节都藏着“坑”。 2026年教育公平与绿色港口发展迅速,技术创新带来新突破
以某汽车零部件厂商的案例为例,2025年底,他们投入千万级资金建设数字孪生系统,试图实现对冲压生产线的全生命周期管理,项目上线三个月就差点“翻车”:传感器采集的振动数据频率不一致,导致模型预测的模具寿命与实际偏差超过40%;更棘手的是,当生产线调整工艺参数(比如冲压速度从每分钟12次提到15次)时,模型需要重新训练,耗时长达两周,根本跟不上生产节奏。
“我们当时以为,只要把设备数据接进来,建个3D模型就万事大吉了。”该厂数字化负责人老张回忆,“后来才发现,真正的挑战是让模型‘动起来’——既要能实时反映设备状态,又要能快速适应生产变化。”
RMSprop优化器:机器学习里的“自适应高手”
要理解数字孪生部署的痛点,得先聊聊RMSprop优化器,这个由Geoffrey Hinton团队在2012年提出的算法,最初是为了解决神经网络训练中的“学习率选择”问题,传统优化器(比如SGD)用固定的学习率更新参数,就像开车时始终踩着同样的油门,遇到上坡(复杂数据)可能动力不足,下坡(简单数据)又容易超速,而RMSprop的聪明之处在于:它能根据历史梯度的平方根动态调整每个参数的学习率——梯度大的方向(比如冲压速度变化对模具寿命的影响)学习率小一些,避免震荡;梯度小的方向(比如环境温度对设备的影响)学习率大一些,加速收敛。

“RMSprop的核心是‘自适应’。”清华大学工业工程系教授王明在2026年的《智能制造技术白皮书》中写道,“它不追求‘一步到位’的最优解,而是通过持续调整,让模型在动态环境中保持稳定。”这种思路,与工业数字孪生的需求不谋而合——生产线的数据是动态的(工艺参数、设备状态、环境条件都在变),模型需要实时适应这些变化,才能提供准确的预测和决策支持。
从算法到工厂:RMSprop的“工业翻译”
2026年初,深圳某电子制造企业的数字孪生项目提供了生动的实践案例,这家企业生产高端手机主板,生产线涉及200多道工序,其中SMT(表面贴装技术)环节的设备故障是影响产能的“头号敌人”,传统方式是等设备报警再维修,但停机损失每小时高达50万元;而数字孪生的目标是提前30分钟预测故障,让维修团队“未雨绸缪”。
项目初期,团队用传统的LSTM(长短期记忆网络)模型处理设备传感器数据(温度、振动、电流等),但效果不佳:模型在训练集上表现良好(准确率92%),但在测试集上直接“崩盘”(准确率跌到65%),问题出在数据分布上——训练数据来自设备正常运行时的稳定状态,而实际生产中,设备会频繁调整工艺参数(比如贴片压力从0.3N调到0.35N),导致数据分布发生“概念漂移”(Concept Drift)。
“这时候,RMSprop的思路给了我们启发。”项目负责人陈工说,“我们没有直接用固定参数的模型,而是设计了一个‘自适应更新机制’——当检测到数据分布变化(比如振动频率的标准差突然增大)时,模型会自动调整学习率:对变化大的参数(比如贴片压力相关的权重)降低学习率,避免过度拟合;对变化小的参数(比如环境温度相关的权重)提高学习率,加速适应。”

具体到技术实现,团队做了两件事:一是在数据预处理阶段,用滑动窗口统计最近10分钟的数据分布(均值、方差、偏度等),与历史分布对比,计算“漂移指数”;二是将“漂移指数”作为动态因子,调整模型训练时的学习率(类似RMSprop中根据历史梯度调整的逻辑),当漂移指数超过阈值(比如0.2)时,贴片压力相关参数的学习率从0.01降到0.005,环境温度相关参数的学习率从0.01提到0.015。
效果立竿见影:模型在测试集上的准确率从65%提升到88%,故障预测的提前量从15分钟延长到28分钟,更关键的是,当生产线在2026年3月调整工艺(将贴片速度从每秒2片提到2.5片)时,模型只用了3天就重新适应了新数据,而之前用传统方法需要两周。
数据质量:比算法更硬的“底层逻辑”
再聪明的算法也救不了“垃圾数据”,2026年4月,杭州某纺织企业的数字孪生项目差点因为数据问题“夭折”,这家企业想用数字孪生优化织布机的能耗——通过实时调整电机转速,让每米布的耗电量降低10%,但项目启动后,模型给出的优化建议总是“不靠谱”:比如建议将电机转速从800转/分钟提到1000转,但实际测试发现,转速超过900转后,布面会出现“纬斜”缺陷,导致次品率飙升。
本月绿色产品链与智能制造及5G通信热度持续上升,相关领域迎来新机遇 问题出在数据标签上,原来,企业采集的能耗数据(电机功率、电流等)和布面质量数据(纬斜、断经等)来自不同系统,时间戳没有对齐——比如能耗数据是每秒采集一次,布面质量数据是每分钟采集一次,模型误以为“高转速对应低能耗”,却忽略了高转速导致的质量损失。

“这就像用错误的公式解题,算法再先进也没用。”项目顾问李博士说,“我们花了两个月重新梳理数据:一是统一时间戳,确保能耗和质量数据同步;二是增加‘质量约束’到模型目标函数——不仅要看能耗降低,还要保证次品率不超过2%,这时候,RMSprop的‘自适应’思路又派上了用场:我们用历史数据训练一个‘质量-能耗’的联合模型,当新数据到来时,模型会根据当前质量状态动态调整优化方向——如果次品率已经接近阈值,就优先降低转速保质量;如果次品率低,就大胆提转速降能耗。” 本月算法推荐与网络公益及绿色仓储领域取得重要进展,行业关注度持续提升
调整后,模型给出的建议终于“靠谱”了:在保证次品率低于1.5%的前提下,电机转速从800转优化到850转,每米布的耗电量降低了8.2%,年节约电费超过200万元。
从“单点优化”到“全局协同”:数字孪生的下一站
2026年的工业数字孪生,早已不满足于“预测设备故障”或“优化单个工序”,在青岛某家电企业的案例中,数字孪生正在向“全局协同”进化——覆盖从原材料入库到成品出库的全流程,连接2000多台设备、300多个物流机器人和50多个仓储单元。
这个系统的核心是一个“动态调度模型”,它需要同时考虑多个目标:订单交付周期、设备利用率、能耗、物流成本等,传统方式是用线性规划或遗传算法求解,但这些方法在数据动态变化时(比如突然插入紧急订单、某台设备故障)需要重新计算,耗时长达数小时,根本跟不上生产节奏。
“我们借鉴了RMSprop的‘多目标自适应’思路。”项目负责人赵总说,“我们把每个目标(交付周期、设备利用率等)看作一个‘参数’,用历史数据训练一个‘目标权重模型’——当某个目标的重要性变化时(比如紧急订单到来,交付周期的权重