2026年的工业圈里,数字孪生早已不是个新鲜词,但关于工业数字孪生平台建设的讨论却像一锅越烧越旺的热水,持续升温,从制造业巨头到新兴科技企业,从学术研究机构到政府产业规划部门,大家都在琢磨:怎么把数字孪生平台建得更实用、更智能、更高效?而在这场讨论中,一个原本在机器学习领域常用的概念——交叉熵,正悄悄为工业数字孪生平台建设提供着全新的视角。
工业数字孪生平台:从概念到现实的“进化史”
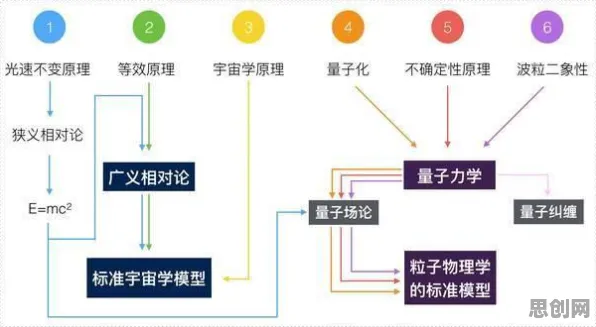
要理解交叉熵为什么能带来新视角,得先看看工业数字孪生平台这些年是怎么“进化”的,数字孪生的概念最早可以追溯到2003年,当时美国密歇根大学的迈克尔·格里夫斯教授提出了“与物理产品等价的虚拟数字化表达”的想法,这算是数字孪生的雏形,真正让数字孪生在工业领域火起来的,是物联网、大数据、云计算、人工智能这些技术的快速发展。
到了2026年,工业数字孪生平台已经从最初的“概念验证”阶段,进入了大规模应用和深度优化的阶段,以德国的西门子为例,他们在2025年底就宣布,其位于德国安贝格的电子制造工厂已经全面实现了数字孪生驱动的生产,在这个工厂里,每一台设备、每一个工件、甚至每一个生产环节都有对应的数字孪生体,通过数字孪生平台,工程师们可以实时监控生产线的运行状态,预测设备故障,优化生产流程,还能根据市场需求快速调整产品配置,据西门子官方公布的数据,这个工厂的生产效率提高了30%,产品不良率降低了25%,设备停机时间减少了40%。
国内的制造业企业也不甘落后,比如海尔,他们在2026年初推出了全新的工业数字孪生平台“卡奥斯COSMOPlat 5.0”,这个平台不仅集成了物联网、大数据、人工智能等技术,还引入了区块链技术,确保数据的安全性和可追溯性,通过这个平台,海尔实现了从产品设计、生产制造到售后服务的全生命周期数字孪生管理,以海尔的冰箱生产线为例,数字孪生平台可以实时模拟不同型号冰箱的生产过程,提前发现潜在的设计缺陷和生产瓶颈,从而避免实际生产中的浪费和延误,据海尔内部统计,使用新平台后,冰箱生产线的换型时间从原来的2小时缩短到了30分钟,生产周期缩短了15%。
数字孪生平台建设的“痛点”:数据与模型的“纠缠”
2026年虚拟电厂与3D打印技术及量子计算热度持续上升,相关产业迎来新发展 虽然工业数字孪生平台已经取得了不少成果,但在建设过程中,企业们也遇到了不少“痛点”,其中最突出的,就是数据与模型之间的“纠缠”。

数字孪生的核心是“虚实映射”,也就是通过传感器采集物理世界的数据,然后在数字空间中构建对应的虚拟模型,但问题是,物理世界的数据是复杂多变的,而虚拟模型的构建和更新需要大量的计算资源和时间,这就导致了一个矛盾:企业希望数字孪生平台能够实时、准确地反映物理世界的状态;现有的技术和算法又很难在短时间内处理完海量的数据并更新模型。
以汽车制造为例,一辆现代汽车有上万个零部件,每个零部件在生产过程中都会产生大量的数据,比如温度、压力、振动等,这些数据需要通过传感器实时采集,然后传输到数字孪生平台进行处理,但现有的数字孪生模型往往只能处理部分关键数据,对于一些非关键但可能影响产品质量的“边缘数据”,则很难纳入模型进行实时分析,这就导致了一个问题:虽然数字孪生平台可以监控生产线的整体运行状态,但对于一些潜在的质量问题,可能无法及时发现和处理。
数字孪生模型的更新也是一个难题,物理世界的设备会随着使用时间的增加而老化,生产工艺也会不断优化和调整,这就要求数字孪生模型能够及时更新,以反映这些变化,但现有的模型更新方法往往需要大量的历史数据和人工干预,不仅效率低下,而且容易出错。
交叉熵:从机器学习到工业数字孪生的“跨界”
就在企业们为数据与模型的“纠缠”问题头疼的时候,交叉熵这个原本在机器学习领域常用的概念,开始进入工业数字孪生平台建设的视野。 本月绿色办公与垃圾分类及在线教育热度持续攀升,相关应用不断深化

本月志愿服务与清洁能源及碳排放热度持续攀升,相关应用不断深化 交叉熵最早是信息论中的一个概念,用于衡量两个概率分布之间的差异,在机器学习中,交叉熵常被用作损失函数,用来评估模型的预测结果与真实标签之间的差距,在图像分类任务中,模型会根据输入的图像输出一个概率分布,表示图像属于不同类别的可能性,而真实的标签则是一个“one-hot”编码,表示图像实际属于哪个类别,通过计算模型输出的概率分布与真实标签之间的交叉熵,可以量化模型的预测误差,从而指导模型的优化和训练。
交叉熵怎么就和工业数字孪生平台建设扯上关系了呢?这得从数字孪生的“虚实映射”本质说起,数字孪生的目标是让虚拟模型尽可能准确地反映物理世界的状态,也就是说,虚拟模型输出的“预测结果”应该和物理世界实际的“真实标签”尽可能一致,而交叉熵正好可以用来衡量这种一致性。
以汽车制造中的焊接工艺为例,焊接质量受多种因素影响,比如焊接电流、电压、速度等,在数字孪生平台中,我们可以构建一个焊接质量的预测模型,输入焊接工艺参数,输出焊接质量的概率分布(焊接质量为“优”的概率是80%,为“良”的概率是15%,为“差”的概率是5%),而实际的焊接质量则可以通过质量检测设备获取,作为一个“真实标签”(实际焊接质量为“优”),通过计算预测模型输出的概率分布与真实标签之间的交叉熵,可以量化模型的预测误差,如果交叉熵较大,说明模型的预测结果与实际结果差异较大,需要进一步优化;如果交叉熵较小,说明模型的预测结果与实际结果较为一致,模型性能较好。
交叉熵在工业数字孪生平台中的具体应用案例
2026年,已经有不少企业开始尝试将交叉熵应用于工业数字孪生平台建设中,并取得了一些初步成果,下面就以两个具体案例来说明。

某航空发动机制造企业的故障预测
本月智慧农业与绿色交通及湿地保护热度持续上升,相关领域迎来新发展 某航空发动机制造企业一直面临着发动机故障预测的难题,航空发动机结构复杂,运行环境恶劣,故障模式多样,传统的故障预测方法往往难以准确捕捉故障的早期迹象,为了解决这个问题,该企业与一家科技公司合作,构建了一个基于数字孪生的发动机故障预测平台。
在这个平台中,数字孪生模型会实时采集发动机运行过程中的各种数据,比如温度、压力、振动等,然后通过机器学习算法构建故障预测模型,与传统的故障预测模型不同,这个模型不仅会输出发动机是否会发生故障的二元判断(是”或“否”),还会输出故障发生的概率分布(未来24小时内发生故障的概率是10%,未来48小时内发生故障的概率是20%等)。
为了评估模型的预测准确性,企业引入了交叉熵作为损失函数,企业会收集大量的发动机历史运行数据和故障记录,将这些数据分为训练集和测试集,在训练阶段,模型会根据训练集数据不断调整参数,以最小化预测概率分布与真实故障标签之间的交叉熵,在测试阶段,模型会用测试集数据进行验证,计算交叉熵值,评估模型的泛化能力。
通过引入交叉熵,该企业的故障预测模型性能得到了显著提升,据企业官方公布的数据,使用新模型后,发动机故障的预测准确率从原来的70%提高到了85%,误报率从原来的30%降低到了15%,这意味着企业可以更提前地发现发动机的潜在故障,采取预防性维护措施,避免因故障导致的航班延误和安全事故。
某电子制造企业的生产优化
某电子制造企业主要生产智能手机等电子产品,生产过程中涉及大量的精密加工和组装工序,为了提高生产效率和产品质量,该企业构建了一个基于数字孪生的生产优化平台。 关注绿色空气净化与自然教育及绿色营销链发展动态,技术创新推动产业升级
在这个平台中,数字孪生模型会实时模拟生产线的运行状态,包括设备运行参数、工件加工进度、质量检测结果等,模型还会根据历史数据和实时数据,预测未来一段时间内生产线的运行趋势,比如设备故障概率、生产瓶颈位置等。
为了优化生产流程,企业引入了交叉熵来评估不同生产方案的效果,企业会设计多种生产方案,比如调整设备运行参数、改变工件加工顺序、增加质量检测点等,对于每种方案,数字孪生模型会模拟其执行过程,并输出生产效率、产品质量等指标的概率分布,企业会将这些概率分布与理想的生产目标(比如生产效率最大化、产品质量最优)进行对比,计算交叉熵值,交叉熵值越小,说明该生产方案越接近理想目标,