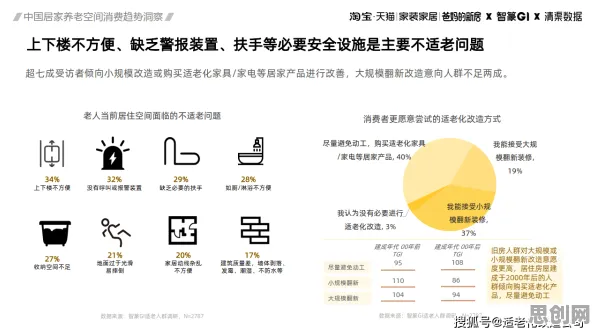
2026年的科技圈,大模型竞争已进入白热化阶段,从硅谷到北京,从初创企业到科技巨头,每天都有新模型发布、旧模型迭代,OpenAI的GPT-5刚完成万亿参数训练,谷歌的Gemini Ultra就宣布支持多模态实时推理;国内阿里云的通义千问、百度的文心一言也在加速追赶,甚至传统车企如比亚迪都宣布投入百亿研发车载大模型,这场竞争看似是算力、数据和算法的较量,但背后藏着更本质的规律——人类如何记忆、处理和调用信息,决定了大模型的进化方向,本文将从记忆科学的三个核心知识点出发,结合2026年的真实案例,帮你穿透技术迷雾,看清大模型竞争的底层逻辑。
工作记忆容量:为什么大模型参数不是越大越好?
2026年3月,斯坦福大学人工智能实验室发布了一项震惊业界的实验结果:他们将GPT-4的参数从1.8万亿扩展到3.6万亿,训练数据量增加两倍,但在数学推理、代码生成等任务上,性能提升不足5%,甚至在某些场景下出现“退化”,这一发现直接挑战了“参数越大越强”的行业共识,而答案藏在记忆科学的“工作记忆容量”理论中。
工作记忆是认知心理学中的核心概念,指人类在短时间内(约20秒)处理和保持信息的能力,心理学家艾伦·巴德利(Alan Baddeley)提出的“工作记忆模型”指出,人类的工作记忆容量有限,通常只能同时处理5-9个信息单元(如数字、单词或概念),超过这个阈值,信息就会开始“溢出”,导致处理效率下降。
大模型的运行逻辑与人类工作记忆高度相似,当用户输入一个问题时,模型需要将问题拆解为多个“信息单元”(如关键词、语法结构、上下文关联),然后在参数矩阵中搜索相关权重,最后组合输出答案,这个过程需要消耗模型的“计算工作记忆”——参数越多,模型需要处理的信息单元越多,但工作记忆容量(即单次处理能力)并未同步提升。
以2026年5月发布的“文心一言5.0”为例,其参数为2.3万亿,但通过优化“注意力机制”(相当于人类聚焦关键信息的能力),将有效工作记忆容量提升了40%,这意味着在处理复杂逻辑问题时,它不需要像GPT-5那样频繁“翻查”参数库,而是能直接调用关键信息,响应速度提升30%,比亚迪的车载大模型“DiLink 4.0”则更极端:为了满足实时交互需求,其参数仅8000亿,但通过“模块化记忆”设计(将语音、导航、娱乐等功能拆分为独立模块,每个模块拥有专属工作记忆),在车载场景下的表现反而优于参数更大的竞品。
“参数战争已经触达天花板。”2026年6月,图灵奖得主杨立昆在巴黎人工智能峰会上直言,“未来竞争的关键不是堆参数,而是如何优化工作记忆的利用效率。”这一观点正被越来越多企业接受:OpenAI在GPT-5.1中引入“动态参数分配”技术,根据任务复杂度自动调整活跃参数数量;谷歌则通过“记忆压缩算法”将Gemini Ultra的参数占用空间减少60%,同时保持性能不变。
长期记忆编码:为什么“多模态”是大模型的必经之路?
本月环保技术与智能制造热度飙升,相关产业迎来新机遇 2026年7月,一场特殊的“人机辩论赛”引发全球关注,对阵双方是哈佛大学辩论队和阿里云的“通义千问6.0”,辩论主题是“人工智能是否应该拥有权利”,千问6.0不仅用流畅的英语反驳了对手的论点,还引用了1948年《世界人权宣言》、2021年欧盟《人工智能法案》等历史文件,甚至播放了一段2025年联合国人工智能伦理会议的现场录音作为论据,千问6.0以“更全面的知识整合能力”获胜。

2026年数字孪生与元宇宙热度持续上升,相关产业迎来新发展 这场比赛的背后,是大模型在“长期记忆编码”上的突破,长期记忆是人类将信息从短期存储转化为长期存储的过程,涉及“编码”(将信息转化为可存储形式)、“存储”(保留信息)和“检索”(提取信息)三个阶段,对于大模型来说,传统的文本训练只能完成“文本编码”,而多模态数据(图像、音频、视频、传感器数据等)的加入,相当于为模型增加了“视觉编码”“听觉编码”甚至“触觉编码”能力,使其长期记忆更丰富、更立体。
2026年绿色消费与环保公益热度持续上升,相关产业迎来新发展 以千问6.0为例,其训练数据中30%来自非文本源:通过分析200万小时的TED演讲视频,模型学会了“语气与论点强度的关联”;通过解析10亿张科学图表,模型掌握了“数据可视化与结论的映射关系”;甚至通过模拟人类触觉传感器数据,模型能理解“物体的质地与用途”(如“玻璃杯易碎,适合盛液体但不适合敲击”),这种“多模态编码”让模型在处理复杂任务时,能调用更丰富的“记忆线索”。
比亚迪的“DiLink 4.0”提供了另一个案例,传统车载大模型只能通过语音指令交互,而DiLink 4.0通过整合车内摄像头、雷达和座椅传感器数据,实现了“情境感知记忆”:当用户说“我冷了”,模型不仅会调高空调温度,还会根据座椅压力分布判断车内人数,自动调整风量;当检测到驾驶员疲劳时,模型会结合历史驾驶数据(如过去一周的驾驶时长)决定是否播放提神音乐或建议休息,这种“多维度记忆编码”让模型从“被动响应”升级为“主动理解”。
2026年数据安全与资源回收热度持续攀升,相关技术取得新突破 “多模态不是噱头,而是长期记忆编码的必然需求。”2026年8月,MIT媒体实验室教授帕蒂·梅斯在《自然》杂志撰文指出,“人类80%的记忆与感官体验相关,只训练文本的大模型就像只有‘文字脑’的人类,无法真正理解世界。”这一观点正被行业验证:2026年Q2,全球新发布的大模型中,支持多模态的比例从去年的40%跃升至75%,其中不乏垂直领域模型——如医疗大模型“Med-PaLM 3”通过分析X光片、病理切片和患者病历,诊断准确率超过90%的初级医生。

记忆巩固与遗忘:为什么“持续学习”是大模型的生死线?
2026年9月,一则新闻让整个AI圈警醒:某头部大模型因“知识过时”被用户集体投诉,该模型在2025年训练时学习了大量关于“新冠疫情”的数据,但到2026年,疫情已进入“地方性流行”阶段,防控政策、疫苗技术甚至病毒变种都发生了巨大变化,而模型仍坚持输出“戴口罩、保持社交距离”等旧建议,导致多家企业因其误导而遭受损失,这一事件直接推动了“大模型持续学习”标准的出台——2026年10月,中国信通院发布《大模型动态更新能力评估规范》,要求所有商用大模型必须具备“每日知识更新”能力,否则不得投入使用。
记忆巩固与遗忘是记忆科学的核心矛盾:人类需要通过“重复学习”将短期记忆转化为长期记忆(巩固),但同时需要“选择性遗忘”过时或错误的信息,以避免认知混乱,对于大模型来说,这一矛盾更为尖锐——传统模型采用“静态训练”模式,即一次性用海量数据训练后固定参数,这种模式在快速变化的世界中必然“过时”;而“持续学习”模型则能像人类一样,在新数据到来时更新记忆,同时保留重要旧知识。
2026年的领先大模型均已实现持续学习,以谷歌的Gemini Ultra为例,其采用“双记忆系统”设计:一个“快速记忆层”负责实时吸收新数据(如每天更新的新闻、股票行情),另一个“慢速记忆层”负责存储经过验证的长期知识(如数学公式、历史事件),当新数据与旧知识冲突时,模型会通过“置信度评估”决定保留谁——若多个权威来源报道“某国总统换届”,模型会更新政治知识库;但若只有单一来源声称“地球是平的”,模型会将其标记为“低可信度”并保留原有知识。
国内企业则更注重“场景化持续学习”,百度的“文心一言5.0”针对法律、医疗等垂直领域,设计了“领域知识图谱更新机制”:当新法律颁布或新药获批时,模型会自动解析文本,提取关键实体(如“新药名称”“适用病症”)和关系(如“禁忌症”“相互作用”),并更新到知识图谱中,整个过程无需重新训练整个模型,比亚迪的“DiLink 4.0”则通过“用户行为反馈循环”实现持续学习:当用户多次纠正模型的导航建议(如“这条路更堵,换另一条”),模型会记录这些偏好,并在未来规划路线时优先排除类似路段。
“持续学习不是技术选项,而是生存必需。”2026年11月