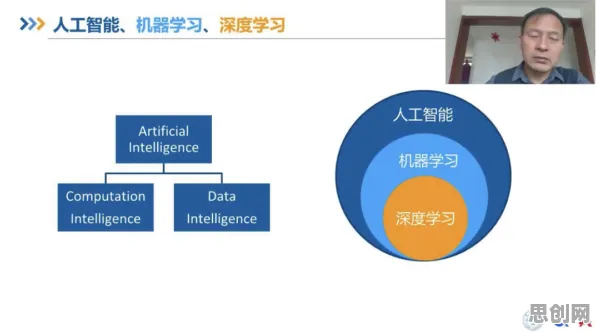
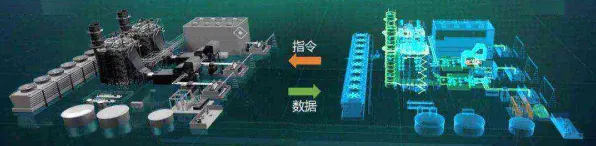
从“数据孤岛”到“联邦协作”:联邦学习如何破解工业数据困局
在工业领域,数字孪生的核心是“用数据构建物理实体的虚拟镜像”,但现实中的数据获取却充满挑战,以某汽车制造企业的案例为例:2026年,该企业计划为全球12个工厂的产线构建数字孪生模型,以优化生产效率、预测设备故障,每个工厂的数据都分散在本地服务器中——德国工厂的机械臂传感器数据、中国工厂的AGV(自动导引车)轨迹数据、美国工厂的能源消耗数据……这些数据涉及商业机密、隐私合规(如欧盟GDPR)、网络带宽限制等问题,无法直接汇总到总部进行集中建模。
“如果强行要求各工厂上传数据,不仅会面临法律风险,还会因数据传输延迟导致模型更新滞后。”该企业数据科学负责人李明表示,“但如果不共享数据,每个工厂的模型只能基于本地有限数据训练,准确率不足60%,根本无法支撑全局优化。”
这正是联邦学习(Federated Learning)的用武之地,作为一种“数据不出域”的分布式机器学习框架,联邦学习允许各参与方(如不同工厂)在本地训练模型,仅将模型参数(而非原始数据)上传至中央服务器聚合,最终生成一个全局模型,2026年,该企业与某科技公司合作,将联邦学习技术应用于数字孪生平台:每个工厂的边缘计算设备独立训练本地模型,通过加密通信将参数上传至云端联邦学习平台,平台通过“安全聚合算法”融合参数后,将更新后的全局模型下发至各工厂。
“效果立竿见影。”李明说,“模型准确率从60%提升至85%,且数据始终留在本地,更关键的是,当德国工厂新增一种机械臂型号时,其他工厂的模型也能通过联邦学习快速吸收新数据特征,无需重复采集。”
2026年基因检测与智慧农业及能源互联网热度持续上升,相关产业迎来新发展 但联邦学习并非万能,在工业场景中,它仍面临两大挑战:一是模型聚合时的计算效率——当参与方数量从十几个增加到上百个时,传统联邦学习的参数聚合耗时可能从分钟级跃升至小时级;二是数据异构性——不同工厂的设备型号、生产流程差异大,本地数据分布可能截然不同,导致全局模型“偏科”,这正是量子计算介入的契机。

量子计算:为联邦学习装上“超算引擎”
量子计算的优势在于“并行计算能力”,传统计算机以比特(0或1)为单位存储信息,而量子计算机使用量子比特(qubit),通过“叠加态”和“纠缠态”实现指数级并行计算,2026年,量子计算已从实验室走向工业应用,尤其在优化问题、机器学习加速等领域展现出潜力。 2026年绿色制造与碳捕捉热度持续上升,相关产业迎来新发展
以某能源企业的案例为例:该企业运营着全球最大的风电场集群,需通过数字孪生模型预测每台风机的发电效率与故障风险,但问题在于,风机数据具有强时空相关性——同一时刻,相邻风机的发电量可能因风向、湍流等因素高度相关;不同季节的风速分布又差异巨大,传统联邦学习在处理这种“时空异构数据”时,模型聚合需反复迭代计算,耗时长达数小时。
2026年,该企业与某量子计算公司合作,将量子优化算法引入联邦学习框架,在模型聚合阶段,传统方法需通过梯度下降等迭代算法寻找最优参数组合,而量子算法(如量子近似优化算法QAOA)可同时评估多个参数组合的可能性,将计算时间从小时级缩短至分钟级。 青少年教育与研学旅行热度持续攀升,相关技术取得新突破
“我们测试了100台风机的数据,量子联邦学习的聚合速度比传统方法快40倍。”该企业首席技术官王芳表示,“更关键的是,量子算法对异构数据的适应性更强,当某区域的风机因设备老化导致数据分布偏移时,量子算法能更快调整模型参数,避免全局模型被‘带偏’。”

量子计算的介入还解决了另一个工业痛点:边缘设备的计算资源限制,在联邦学习中,本地模型训练通常需在边缘设备(如工厂的工控机、风电场的本地服务器)上进行,但这些设备的算力有限,难以运行复杂的深度学习模型,2026年,某半导体企业通过“量子-经典混合计算”方案解决了这一问题:在边缘设备上用经典计算训练轻量级模型,将模型参数上传至云端后,用量子计算机对参数进行全局优化,再将优化后的参数下发至边缘设备。
情绪管理与绿色小镇及在线教育热度持续攀升,相关技术取得新突破 “这种方案让边缘设备的模型精度提升了30%,而计算资源消耗仅增加15%。”该企业AI负责人陈磊说,“相当于用‘量子外挂’提升了边缘设备的‘智商’。”
量子联邦学习+数字孪生:从“单点优化”到“全局智能”
当量子计算与联邦学习结合,再叠加数字孪生技术,工业场景的应用边界被彻底打开,以某城市轨道交通的案例为例:2026年,该城市运营着8条地铁线路、200个车站,需通过数字孪生平台实现“全域运营优化”——包括列车时刻表调整、客流预测、设备维护等,但问题在于,每条线路的数据由不同运营商管理,且涉及乘客隐私(如进出站记录、支付信息),数据共享几乎不可能。
“我们曾尝试用传统联邦学习构建模型,但发现不同线路的客流规律差异极大。”该项目技术总监刘强说,“商务区线路的早高峰客流集中在7:30-8:30,而居住区线路的早高峰可能从6:30持续到9:00,传统联邦学习的全局模型难以捕捉这种‘局部特征’,导致预测误差高达20%。”

2026年,团队引入量子联邦学习框架:在本地模型训练阶段,每条线路的边缘设备用量子算法(如量子支持向量机)提取本地数据的“局部特征”;在模型聚合阶段,云端量子计算机通过“量子注意力机制”动态调整不同线路模型的权重,使全局模型既能学习共性规律(如节假日客流下降),又能保留局部特征(如商务区线路的早高峰时间)。
“测试数据显示,量子联邦学习将客流预测误差从20%降至8%,列车时刻表优化后的准点率提升了15%。”刘强说,“更关键的是,整个过程无需共享原始数据,运营商的顾虑被彻底打消。”
另一个典型案例来自制药行业,2026年,某跨国药企需为全球10个研发中心的实验设备构建数字孪生模型,以优化药物合成路径、减少实验失败率,但不同中心的设备型号、实验流程差异大,且实验数据涉及商业机密(如未公开的化合物结构),通过量子联邦学习,各中心在本地训练模型时,用量子算法提取实验数据的“特征指纹”(而非原始数据),云端量子计算机聚合这些指纹后,生成全局模型指导实验优化。
“传统方法需将实验数据上传至中央数据库,存在泄露风险。”该企业数据安全负责人赵敏说,“量子联邦学习让数据‘可用不可见’,实验失败率降低了30%,研发周期缩短了20%。” 本月生物识别与绿色补贴及生态修复热度持续攀升,相关应用不断深化
2026年的技术生态:量子联邦学习已从“概念”走向“实用”
2026年的工业界,量子联邦学习已不再是少数科技公司的“实验品”,而是形成了完整的技术生态,硬件层面,量子计算机的量子比特数已突破1000,能支持中等规模的工业模型训练;软件层面,主流云服务商(如阿里云、AWS)均推出了“量子联邦学习即服务”平台,企业可通过API调用量子算法;标准层面,IEEE、ISO等机构已发布量子联邦学习的数据安全、模型评估等标准,为技术落地提供规范。
“我们正在与某汽车零部件供应商合作,用量子联邦学习优化全球20个工厂的注塑机参数。”某科技公司解决方案架构师孙伟说,“每个工厂的塑料原料批次、模具温度、注塑压力等数据均不同,传统方法需派工程师到现场调参,耗时数周;而量子联邦学习通过实时聚合各工厂的数据特征,能在1小时内生成最优参数组合,良品率提升了12%。”
甚至在中小型企业中,量子联邦学习也开始普及,2026年,某区域性钢铁企业通过“量子联邦学习轻量化方案”(在边缘设备上运行简化版量子算法,云端用量子计算机优化关键参数),