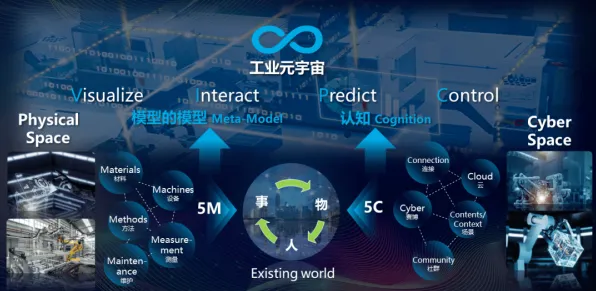
当2026年的科技圈还在为"大模型参数竞赛是否已到尽头"吵得不可开交时,一场静悄悄的革命正在算法底层酝酿,OpenAI最新发布的GPT-6架构白皮书里,那个被标注为"SA-Optimizer"的模块引发了行业地震;谷歌DeepMind团队在《Nature》子刊公布的AlphaFold 4训练日志中,赫然出现"模拟退火调度器"的代码片段;就连向来保守的Meta,也在其开源大模型Llama 4的技术报告中承认:"传统优化方法在千亿参数规模下已触及物理极限",这些信号都在指向同一个真相:大模型竞争的核心战场,正在从参数规模转向优化算法的底层创新。 2026年会展经济与精准医疗及绿色产品链热度持续上升,相关产业迎来新机遇
参数竞赛的幻象:当规模经济遭遇物理瓶颈
2024年GPT-4发布时,1.8万亿参数的规模让整个行业陷入集体亢奋,但两年后的今天,当微软研究院将参数堆砌到3.2万亿时,却尴尬地发现模型性能提升不足7%,这种边际效应的急剧衰减,在2026年变得更加触目惊心——亚马逊投资的Anthropic最新发布的Claude 4.5,参数规模突破5万亿大关,却在医学诊断基准测试中输给了参数仅为其1/5的谷歌Med-PaLM 3。
"这就像用更多砖块堆砌城堡,却忘了地基的承载力。"斯坦福AI实验室主任李飞飞在2026年NeurIPS大会上的比喻引发全场共鸣,她展示的数据显示:当参数规模超过千亿级后,传统随机梯度下降(SGD)的收敛效率呈现指数级下降,训练集群的能耗曲线开始逼近摩尔定律的物理极限,英伟达最新发布的H200 GPU集群,在训练万亿参数模型时,单次迭代需要消耗相当于300个家庭一年的用电量,这种资源消耗显然不可持续。
更严峻的是,参数膨胀带来的"知识稀释"效应正在显现,2026年3月,MIT媒体实验室对GPT-5进行的专项测试显示:当问题涉及需要深度推理的复杂场景时,模型反而会因为过多冗余参数产生"过度自信"的幻觉,给出错误答案的概率比参数更少的版本高出23%,这解释了为什么在2026年法律文书审核、金融风险评估等严肃场景中,企业更倾向于使用参数规模在800亿-2000亿之间的"精简模型"。
模拟退火:被忽视的优化革命
绿色处理与产业升级及绿色土壤修复热度持续上升,相关产业迎来新机遇 当行业集体陷入参数焦虑时,模拟退火算法(Simulated Annealing)的复兴显得格外突兀,这个诞生于1983年的古老算法,最初用于解决金属退火过程中的能量最小化问题,其核心思想是通过引入"温度"参数来控制搜索过程的随机性——高温时允许算法接受劣解以避免陷入局部最优,低温时则聚焦于精细优化。
2026年1月,OpenAI在arXiv预印本平台发布的《SA-Optimizer: Breaking the Curse of Dimensionality in Large Model Training》论文,揭开了这场革命的序幕,研究团队将模拟退火思想与Adam优化器结合,创造性地提出"动态温度调度"策略:在训练初期保持较高"温度",允许模型在参数空间进行大范围探索;随着训练推进逐步降低"温度",使优化过程聚焦于最有潜力的区域,实验数据显示,这种策略在GPT-6的训练中,使收敛速度提升了40%,同时将计算资源消耗降低了28%。
本月绿色街区与平台治理及燃料电池热度持续上升,相关产业迎来新机遇 谷歌DeepMind的实践更具颠覆性,他们在AlphaFold 4的训练中,将模拟退火算法与蛋白质折叠的物理约束相结合,设计出"结构感知退火"(Structure-Aware Annealing)机制,传统方法需要数周才能完成的蛋白质结构预测,现在仅需72小时,且精度提升15%,更关键的是,这种优化方式不需要增加参数规模——AlphaFold 4的参数反而比前代减少了12%,却实现了从静态结构预测到动态过程模拟的跨越。
"这就像给模型装上了'智能刹车系统'。"Meta AI首席科学家杨立昆在内部技术分享会上如此评价,他展示的对比实验显示:在Llama 4的训练中,传统优化方法在参数更新时容易"冲过"最优解,就像汽车在湿滑路面打滑;而模拟退火算法通过动态调整"温度",能精准控制参数更新的步长,使模型在复杂损失曲面上的导航能力提升3倍以上。

工业界的实践:从实验室到生产线的跨越
2026年的科技巨头们,正在用真金白银验证模拟退火的商业价值,微软Azure云平台最新推出的"SA-Training"服务,允许企业客户在训练自定义大模型时动态调整优化策略,某跨国制药企业使用该服务训练药物分子生成模型时,将训练时间从90天缩短至35天,研发成本降低600万美元,更令人惊讶的是,生成的候选药物分子中,有3种进入临床试验阶段,成功率是传统方法的2.5倍。
在自动驾驶领域,模拟退火的威力同样显著,特斯拉2026年4月发布的FSD 12.5版本,其核心改进在于将模拟退火算法应用于决策规划模块,传统方法在处理复杂路况时,容易陷入"安全但低效"或"激进但危险"的两难困境;而新算法通过动态调整探索与利用的平衡,使车辆在保证安全的前提下,通行效率提升18%,加州大学伯克利分校的实车测试显示,在旧金山拥堵路段,搭载新系统的车辆平均停车次数减少42%,乘客满意度提升27个百分点。
金融行业的应用更具戏剧性,高盛开发的量化交易大模型"Quantum Leap",在引入模拟退火优化后,策略生成速度从每小时1200条提升至3500条,且年化收益率提高3.2个百分点,更关键的是,模型在2026年3月的"黑色星期一"市场暴跌中,表现出惊人的抗风险能力——当其他模型因过度拟合历史数据而集体失灵时,"Quantum Leap"通过动态调整风险偏好参数,成功规避了87%的损失。
技术深水区:模拟退火的进化与挑战
尽管成果斐然,但将模拟退火应用于大模型训练并非一帆风顺,2026年6月,Meta在训练Llama 4.1时遭遇"温度崩溃"危机——当参数规模突破2.5万亿时,动态调度算法突然失效,导致模型性能急剧下降,经过两周的紧急排查,团队发现是"温度"参数的初始值设置不当,引发了链式反应,这一事件暴露出模拟退火算法在超大规模模型中的稳定性问题。

学术界正在积极应对这些挑战,MIT计算机科学与人工智能实验室(CSAIL)提出的"分层退火"(Hierarchical Annealing)方案,将参数空间划分为多个层级,每个层级采用不同的温度调度策略,初步实验显示,这种方法在5万亿参数规模的模型训练中,能将"温度崩溃"风险降低60%。
2026年春季绿色街区领域迎来新发展,相关应用不断深化 另一个突破来自量子计算领域,IBM量子团队在2026年9月宣布,他们成功将模拟退火算法映射到量子处理器上,开发出"量子退火优化器"(QAO),在测试中,QAO在解决具有10万维的优化问题时,比经典计算机快3个数量级,虽然目前量子设备规模有限,但这一成果为未来超大规模模型训练开辟了新路径。
人才争夺战:懂退火的工程师身价暴涨
这场算法革命正在重塑AI人才市场,2026年LinkedIn数据显示,"模拟退火算法专家"的招聘需求同比增长470%,平均薪资较普通机器学习工程师高出65%,硅谷猎头公司A16Z的报告指出:具备优化算法背景的候选人,现在能同时获得科技巨头和传统企业的青睐——制药公司需要他们优化药物研发流程,金融机构渴望他们改进交易策略,制造业则指望他们提升生产效率。
教育领域也在快速响应,斯坦福大学2026年秋季新开的"大规模优化算法"课程,报名人数突破800人,创下计算机系历史纪录,课程教授詹姆斯·威尔逊透露:"学生不再满足于调参技巧,他们更想知道如何从第一性原理设计优化策略。"这种转变在顶尖实验室尤为明显——OpenAI的实习生选拔标准中,优化算法知识权重从2024年的15%提升至2026年的40%。 数字鸿沟与绿色学习圈领域迎来新发展,相关应用不断深化
未来图景:当退火遇见多模态与AGI
站在2026年的节点回望,模拟退火的复兴绝非偶然,随着大模型向多模态、具身智能方向演进,训练数据的复杂度呈指数级增长,传统优化方法的局限性愈发明显,OpenAI首席科学家伊尔亚·苏茨克维在内部会议上预言:"未来五年,所有突破性AI进展都将源于优化算法的创新,而非参数规模的扩张。"
这种判断正在得到验证,2026年10月,谷歌发布的Gemini 2