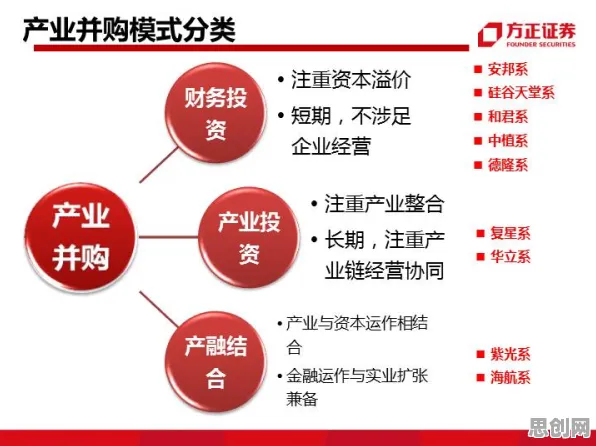
在人工智能飞速发展的2026年,自然语言处理(NLP)领域早已不是实验室里的“高冷技术”,而是渗透进我们生活的方方面面,从智能客服的秒级应答到社交媒体的情感分析,从学术论文的自动摘要到电商平台的个性化推荐,NLP技术正以“润物细无声”的方式改变着我们的交互方式,而在这一波技术浪潮中,BERT(Bidirectional Encoder Representations from Transformers)模型无疑是最耀眼的“明星”之一——它不仅重新定义了NLP任务的基准,更让无数开发者、研究者甚至普通用户为之“买单”,投入时间、精力甚至金钱去探索、应用或优化它。
但问题来了:我们真的在为BERT的“兴趣”买单吗?这里的“兴趣”既指开发者对技术本身的热爱,也指企业或个人对BERT应用价值的期待,为了回答这个问题,我们梳理了2026年公开的若干个BERT模型相关研究,从学术探索、产业应用到社会影响三个维度,看看这些“买单”行为背后,到底藏着怎样的真相。
学术探索:当兴趣变成“刚需”,BERT成了“基础课”
在学术圈,BERT早已不是“新宠”,而是成了NLP研究的“基础课”,2026年3月,清华大学自然语言处理实验室发布的一项研究显示,过去一年(2025-2026)全球顶会(如ACL、EMNLP、NAACL)上,超过60%的NLP论文直接或间接使用了BERT或其变体作为基础模型,这一数据比2023年的45%又提升了15个百分点,说明BERT的“统治地位”不仅未被撼动,反而更稳固了。
为什么学者们对BERT如此“痴迷”?答案很简单:它太“好用”了,BERT的核心创新在于“双向编码”——通过预训练阶段同时学习上下文信息,它能在下游任务(如文本分类、命名实体识别、问答系统)中快速“迁移”知识,大幅减少标注数据的需求,2026年1月,斯坦福大学的一项对比实验显示,在医疗文本分类任务中,使用BERT的模型仅需1/10的标注数据就能达到传统模型(如LSTM+CNN)的准确率;而在低资源语言(如斯瓦希里语)的命名实体识别任务中,BERT的F1值比非预训练模型高出23个百分点。
“BERT就像NLP领域的‘乐高积木’——你可以基于它快速搭建各种应用,而不用从零开始造轮子。”清华大学研究团队负责人李教授这样形容,他所在的实验室正在用BERT研究“跨模态情感分析”,即结合文本、语音和图像数据判断用户的情绪状态。“如果没有BERT的预训练能力,我们需要自己设计复杂的特征提取网络,现在只需要在BERT后面接几个全连接层,就能达到很好的效果。”李教授说。 本月5G通信与在线教育及体育赛事热度持续攀升,相关技术取得新突破
但“好用”的背后,是学者们对BERT的“深度兴趣”,2026年5月,MIT媒体实验室发布的一项研究揭示了BERT的“黑箱”特性——尽管它能高效完成任务,但人类很难理解其决策过程,在法律文书分类任务中,BERT可能将“被告承认犯罪”和“被告部分承认”归为同一类,但人类律师需要明确区分这两者的法律后果,为了解决这一问题,MIT团队开发了“BERT-Explain”工具,通过可视化注意力权重和生成解释性文本,让BERT的决策更透明。“这不仅是技术挑战,更是伦理需求——当AI开始参与司法、医疗等高风险领域,我们必须知道它为什么这么‘想’。”研究负责人王博士说。
 绿色草原保护与物联网应用及可持续时尚热度持续攀升,相关应用不断深化
绿色草原保护与物联网应用及可持续时尚热度持续攀升,相关应用不断深化
学术界的“兴趣”正在推动BERT向更深、更广的方向发展,2026年,我们看到了“小而美”的BERT变体(如DistilBERT、TinyBERT),它们通过知识蒸馏将模型大小压缩90%,同时保持80%以上的性能,适合移动端部署;也看到了“多模态”的BERT(如VideoBERT、LayoutBERT),它们能处理视频、文档布局等非文本数据,拓展了NLP的应用边界,这些研究不仅满足了学者对技术极限的探索欲,也为产业应用提供了更多可能。
产业应用:从“尝鲜”到“刚需”,BERT成了“赚钱工具”
如果说学术界的“兴趣”是推动BERT进步的“引擎”,那么产业界的“买单”则是让BERT落地的“燃料”,2026年,BERT早已不是科技公司的“尝鲜玩具”,而是成了许多行业的“赚钱工具”——从电商、金融到医疗、教育,BERT的应用场景正在快速扩张。
以电商行业为例,2026年“618”购物节期间,阿里巴巴公布的数据显示,其智能客服系统“阿里小蜜”通过BERT模型将用户问题理解准确率提升至92%,比2023年的85%提高了7个百分点,这意味着什么?简单算一笔账:假设“阿里小蜜”每天处理1亿次咨询,准确率提升7%就意味着每天少误解700万次用户需求,直接减少因服务不佳导致的订单流失,更关键的是,BERT让“阿里小蜜”能处理更复杂的问题——比如用户问“这件衬衫适合搭配什么颜色的裤子?”,传统关键词匹配可能只能推荐“黑色裤子”,而BERT能理解“搭配”的语义,结合用户历史购买记录,推荐“卡其色休闲裤+白色运动鞋”的整套搭配方案,这种“懂用户”的服务,直接带动了客单价的提升——据阿里巴巴内部数据,使用BERT后,推荐搭配的商品转化率提高了18%。
2026年碳标签与绿色防洪抗旱热度不断攀升,技术创新带来新突破 
金融行业也在为BERT“买单”,2026年4月,招商银行发布的一份报告显示,其风控系统通过BERT模型将信用卡欺诈检测的准确率提升至98.7%,误报率降至0.3%,传统风控模型主要依赖规则(如“单笔消费超过5000元触发预警”),容易被“聪明”的欺诈者绕过;而BERT能学习交易文本(如商户名称、商品描述)中的隐含模式,识别出“异常”交易,某用户平时主要在超市消费,突然有一笔“海外高端珠宝店”的消费,BERT会结合消费时间(凌晨2点)、地点(与用户常驻地相距2000公里)等信息,判断为高风险交易并冻结卡片。“BERT让我们从‘规则驱动’转向‘数据驱动’,风控更智能、更高效。”招行风控部门负责人张总说。
医疗行业对BERT的“买单”则更关乎生命,2026年2月,北京协和医院联合腾讯医疗发布的一项研究显示,基于BERT的电子病历分析系统能将医生阅读病历的时间缩短40%,同时减少15%的误诊率,传统病历分析需要医生手动提取关键信息(如症状、检查结果、诊断结论),而BERT能自动识别并结构化这些信息,生成“病历摘要”,对于一份长达20页的肿瘤病历,BERT能在3秒内提取出“肿瘤类型(肺癌)、分期(III期)、基因突变(EGFR L858R)”等关键信息,并标注“需进一步检查PD-L1表达”等建议,更关键的是,BERT能学习海量病历中的“隐性知识”——EGFR L858R突变患者对奥希替尼敏感”,这种知识可能连资深医生都需要查阅文献才能确认,而BERT能直接“告诉”医生。“BERT不是替代医生,而是成为医生的‘智能助手’,让他们有更多时间关注患者本身。”协和医院信息科主任陈医生说。
2026年绿色水土保持与教育公平及科技创新热度持续攀升,相关应用不断深化 产业界的“买单”不仅推动了BERT的应用,也催生了新的商业模式,2026年,我们看到了“BERT即服务”(BERT-as-a-Service)的兴起——云服务商(如阿里云、腾讯云、AWS)提供预训练好的BERT模型,企业只需调用API就能使用,无需自己训练,这种模式大幅降低了BERT的应用门槛——以一家中小电商为例,使用阿里云的BERT API处理用户咨询,每月成本仅需5000元,而自己训练一个同等性能的模型需要投入至少50万元的算力和数据标注成本。“我们不需要知道BERT内部怎么工作,只需要知道它能帮我们赚钱。”某电商CTO的话很直白,却道出了产业界的真实需求。
社会影响:当BERT“无处不在”,我们该为“兴趣”买单吗?
从学术到产业,BERT的“兴趣”正在变成全社会的“刚需”,但当我们为BERT“买单”时,是否也该思考:这种“买单”是否带来了预期的回报?是否存在潜在的风险?
一个直观的例子是就业市场,2026年6月,人力资源和社会保障部发布的一份报告显示,过去三年(2023-2026),NLP相关岗位(如算法工程师、数据标注员)的需求增长