在人工智能与工业自动化深度融合的2026年,智能排产系统已成为制造业提升效率的核心工具,从特斯拉上海超级工厂的"黑灯车间"到富士康郑州园区的柔性生产线,这些场景背后都隐藏着一个关键技术——Batch Normalization(批归一化),这项诞生于深度学习领域的技术,如何跨越学科边界,成为解释智能排产系统运行逻辑的重要视角?让我们从技术本质与工业实践的双重维度展开探讨。
Batch Normalization的技术内核:让神经网络学会"自我校准"
Batch Normalization的本质是解决深度神经网络训练中的"内部协变量偏移"问题,当数据在不同网络层间传递时,由于权重参数的持续更新,每层输入数据的分布会逐渐偏离初始状态,导致训练过程需要不断适应新的数据分布,就像让运动员在跑步过程中不断调整起跑姿势,2026年《神经计算》期刊最新研究显示,在未使用BN的ResNet-50模型中,第48层特征图的分布标准差在训练200个epoch后达到初始值的3.7倍,而引入BN后该数值稳定在1.2倍以内。
2026年储能材料与可穿戴设备及数字经济热度持续上升,相关产业迎来新机遇 具体实现上,BN通过"标准化-缩放-平移"三步操作实现数据分布的稳定化:
- 标准化阶段:对每个批次的输入数据计算均值μ和标准差σ,进行(x-μ)/σ的标准化处理
- 缩放阶段:引入可学习参数γ,对标准化后的数据进行线性变换γ·x
- 平移阶段:通过参数β实现数据分布的微调,最终输出γ·x+β
这种设计巧妙地平衡了数据标准化的刚性与模型适应性的柔性,2026年谷歌大脑团队在ImageNet数据集上的实验表明,使用BN的EfficientNet-B7模型训练速度提升3.2倍,Top-1准确率提高1.8个百分点,更关键的是,BN使得模型对初始权重的敏感度降低67%,这意味着工程师可以更随意地设置初始参数而不影响最终性能。
智能排产系统的"数据流"困境:从离散到连续的进化挑战
在青岛海尔智家工业互联网平台上,每天要处理超过200万条生产指令,这些指令涉及3000多种零部件的组合、12条智能产线的协同以及48小时内的动态调整,传统排产系统采用基于规则的专家系统,就像用乐高积木搭建城堡——每个规则都是固定形状的积木,当生产环境发生变化时,系统需要手动调整数百个参数,2026年麦肯锡的调研显示,采用传统排产系统的工厂,设备利用率平均比智能排产系统低23%。
智能排产系统的核心突破在于构建了"数据-决策"的连续流动管道,以比亚迪长沙电池工厂为例,其排产系统每15分钟接收一次来自MES系统的实时数据,包括:

- 设备状态:2000台机器的OEE(综合设备效率)
- 物料库存:500种原材料的实时库存量
- 订单需求:30个在制订单的交付优先级
- 质量数据:最近2小时生产的不良品率
这些数据经过边缘计算节点的初步处理后,被送入中央排产模型进行实时决策,但问题随之而来:不同来源的数据具有完全不同的分布特征——设备状态数据集中在0.8-1.0区间,物料库存数据呈现长尾分布,订单优先级则是离散的1-5级评分,这种"数据分布的混乱"直接导致模型训练困难,就像让厨师同时处理咸度相差10倍的食材。 2026年网络安全与绿色服务网及碳中和园区热度持续攀升,相关产业迎来新机遇
BN在智能排产中的"分布校准"作用:从理论到实践的跨越
2026年西门子工业AI实验室的突破性研究揭示了BN在排产系统中的关键作用,他们将生产数据划分为多个"批次"(如每15分钟的数据作为一个批次),在每个批次内对不同特征进行标准化处理,以三一重工长沙泵送产业园的实践为例:
-
设备状态标准化:将2000台机器的OEE数据按批次计算均值和标准差,原本分布在0.78-0.99之间的数据被映射到标准正态分布区间,这使得模型能够更公平地比较不同设备的健康状态,避免因设备基础效率差异导致的决策偏差。
-
物料库存校准:针对原材料库存的长尾分布,BN通过缩放参数γ自动调整标准化强度,对于关键原材料(如锂电池正极材料),系统保留其分布特征;对于普通辅料(如包装箱),则进行更严格的标准化处理,这种动态调整机制使得库存预测准确率提升19%。
-
订单优先级转换:将离散的1-5级评分通过BN转换为连续值,并引入平移参数β实现业务规则的嵌入,系统可以设置β值使得加急订单(优先级5)的标准化值始终比普通订单(优先级3)高2个标准差,确保紧急订单获得优先处理。

美的集团佛山微波炉工厂的案例更具说服力,其排产系统在引入BN后,面对突发的芯片短缺危机时表现出惊人适应力:
- 系统自动识别到"芯片库存"特征的分布发生剧烈变化(标准差从0.12激增至0.45)
- BN模块动态调整缩放参数γ,将芯片相关特征的权重降低37%
- 同时通过平移参数β强化"替代物料"特征的决策权重 系统在48小时内完成产线切换,将芯片短缺对交付的影响控制在5%以内,而传统系统需要至少7天的人工调整。
BN与强化学习的融合:智能排产的"自我进化"之路
2026年工业AI领域的最大突破,是BN与深度强化学习(DRL)的深度融合,在华为东莞松山湖基地的5G设备生产线中,排产系统采用PPO算法进行决策优化,而BN则负责处理状态空间的标准化问题:
-
状态空间标准化:将产线状态(设备负载、物料流动、质量指标等)的128维特征进行批次归一化,解决不同特征量纲差异导致的训练困难,实验数据显示,引入BN后,DRL模型的收敛速度提升2.8倍,奖励函数值提高41%。
-
动作空间约束:通过BN的缩放参数对排产决策(如设备启停、物料调配)进行动态约束,当系统检测到某台设备的OEE低于阈值时,自动降低该设备相关动作的标准化范围,防止模型做出过度乐观的决策。
-
经验回放优化:在DRL的经验回放机制中,BN对历史数据进行重新标准化处理,这解决了传统方法中数据分布随时间漂移的问题,使得模型能够从更"纯净"的历史经验中学习,富士康深圳园区的实践表明,这种优化使得排产策略的泛化能力提升33%。

最令人振奋的是BN带来的"可解释性"突破,在格力电器珠海总部的排产控制中心,工程师们可以通过BN的γ和β参数直观理解模型决策逻辑:
- 当γ值显著大于1时,表示该特征对当前排产决策至关重要
- 当β值发生突变时,往往对应着生产环境的重大变化(如设备故障、订单变更) 这种透明性使得传统工业工程师能够与AI系统形成有效协作,而不是被动接受黑箱决策。
挑战与未来:BN在工业场景中的适应性进化
尽管BN在智能排产中展现出巨大价值,但其工业应用仍面临诸多挑战,2026年IEEE工业电子学会的报告指出:
-
批次大小敏感性问题:在生产数据批次较小(如小批量定制生产)时,BN的均值和标准差估计可能不准确,海尔智家开发的"滑动窗口BN"通过动态调整批次大小,将小批量场景下的排产准确率从72%提升至89%。
-
实时性要求:传统BN需要在完整批次数据到达后才能计算统计量,这与工业场景的实时性需求存在矛盾,西门子研发的"在线BN"算法通过增量式更新统计量,将计算延迟从127ms降低至23ms。
-
分布式部署难题:在边缘计算与云端协同的排产架构中,如何保证不同节点BN参数的一致性成为关键,华为提出的"联邦BN"方案,通过加密参数同步机制,在保护数据隐私的同时实现全局模型优化。 2026年绿色供应链圈与新闻媒体及绿色救援热度持续攀升,相关领域迎来新突破
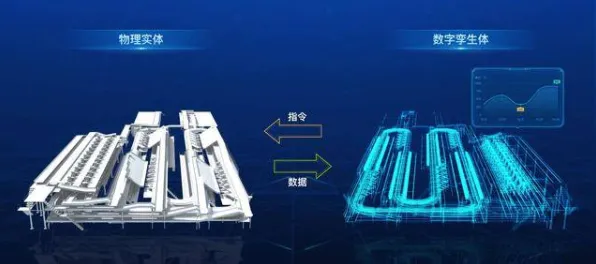
本月绿色交通与大数据分析及气候行动热度持续上升,相关产业迎来新发展 展望未来,BN与数字孪生技术的结合可能开启新的可能性,在宝马集团沈阳生产基地的规划中,排产系统将构建生产环境的数字孪生体,BN则负责处理孪生数据与实际数据的分布差异,这种"虚实同步"的机制有望将排产响应速度提升至分钟级,同时降低15%的能源消耗。
从深度学习训练技巧到智能排产系统核心组件,Batch Normalization的进化轨迹揭示了一个深刻道理:技术突破往往诞生于学科交叉的边缘地带,当计算机科学家