在2026年的工业领域,一场由数据驱动的变革正以前所未有的速度重塑传统生产模式,当某汽车制造企业通过分析生产线上的传感器数据,将设备故障预测准确率提升至98%时;当某风电巨头利用历史运维数据优化风机叶片设计,使发电效率提高15%时——这些真实发生的案例背后,都指向一个核心命题:工业大数据分析正在从"辅助工具"升级为"生产要素",而迁移学习作为破解工业数据困境的关键技术,其底层逻辑的清晰化,正在为这场变革注入新的动能。
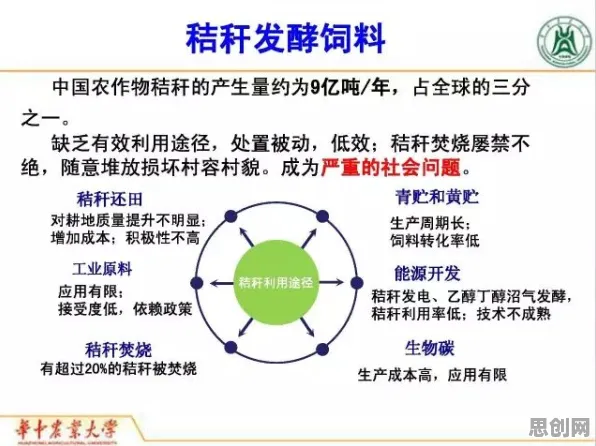
工业大数据的"三座大山":为什么传统分析方法失效了?
在深圳某电子制造企业的智能工厂里,12条SMT贴片生产线每天产生超过2TB的数据,这些数据包含温度、湿度、压力、振动等400多个维度的参数,理论上足以支撑对生产质量的精准控制,但现实却令人困惑:当工程师试图用传统机器学习方法建立质量预测模型时,模型在训练集上的准确率高达95%,一到新产线却骤降至60%以下。
2026年聚焦绿色工作圈与大数据分析及电竞赛事新趋势,应用场景不断拓展 这种"数据富矿但价值贫瘠"的悖论,源于工业大数据的三大特性:
-
数据孤岛效应:某钢铁集团下属的15家工厂,每家都独立建设了数据平台,但因设备型号、工艺参数、数据格式差异,集团层面无法实现数据互通,2026年工信部发布的《工业数据流通白皮书》显示,超过70%的工业企业存在跨部门、跨工厂数据共享障碍。
-
标签稀缺困境:在半导体制造领域,缺陷检测需要人工标注每片晶圆的图像,一名熟练工程师每天最多标注200张,而一条产线每天产生10万张图像,某芯片厂商尝试用众包方式解决,但标注质量参差不齐,导致模型误检率高达30%。
-
动态环境挑战:某化工企业发现,同一套反应釜在不同季节的温控曲线需要调整——夏季需要提前2小时降温,冬季则要延迟1小时,这种由环境变化引发的"概念漂移",使得模型需要每月重新训练,维护成本激增。
这些特性导致传统机器学习陷入"数据越多越难用"的怪圈,某汽车零部件厂商的案例极具代表性:他们花费500万元采集了3年生产数据,但因设备升级导致数据分布变化,最终建立的预测模型在上线3个月后就完全失效。
迁移学习:破解工业数据困局的"万能钥匙"
迁移学习的核心思想,是让模型在相关但不同的任务间"举一反三",就像人类学会骑自行车后,能更快掌握摩托车驾驶——模型通过在源领域(数据充足的任务)学习通用特征,再迁移到目标领域(数据稀缺的任务),实现"小样本学习"。
在工业场景中,这种技术正在创造惊人价值:
案例1:风电设备的跨机型故障预测
金风科技在2026年面临一个棘手问题:他们有2000台在运风机,但其中80%是旧型号,20%是新型号,旧型号积累了10年运维数据,新型号只有2年数据,传统方法需要为每个型号单独建模,但新型号数据量不足导致模型不可靠。
迁移学习解决方案:
- 特征迁移:将旧型号风机的振动、温度等传感器数据,通过深度神经网络提取通用特征(如"齿轮箱异常振动模式")
- 微调适配:在新型号数据上对通用特征进行微调,仅需少量标注数据即可建立准确模型
效果:新型号风机故障预测准确率从62%提升至89%,模型开发周期从6个月缩短至2周。
案例2:半导体制造的跨工厂缺陷检测
中芯国际在2026年推进"灯塔工厂"建设时遇到挑战:他们有5家12英寸晶圆厂,每家工厂的光刻机型号、工艺参数不同,导致缺陷图像存在显著差异,传统方法需要为每家工厂单独训练检测模型,但标注成本高昂。
迁移学习解决方案:
- 领域自适应:采用对抗生成网络(GAN)构建域适配器,将不同工厂的图像映射到统一特征空间
- 渐进式学习:先在数据充足的A工厂训练基础模型,再通过少量B工厂数据快速适配
效果:模型跨工厂迁移后,缺陷检测F1值仅下降3%,而标注成本降低80%。

案例3:汽车焊接的跨产线质量优化
比亚迪在2026年推广智能焊接系统时发现:不同产线的机器人品牌、焊接工艺存在差异,导致质量预测模型无法通用,某产线积累的10万条焊接数据,在其他产线几乎无法复用。
迁移学习解决方案:
- 元学习框架:构建可快速适应新任务的元模型,通过少量样本学习产线间的差异模式
- 知识蒸馏:将大产线模型的知识压缩到小模型,降低新产线部署成本
效果:新产线模型部署时间从2周缩短至3天,焊接良品率提升1.2个百分点。 氢能技术与社会责任领域取得重要进展,行业关注度持续提升
底层逻辑揭秘:迁移学习如何解决工业核心痛点?
迁移学习在工业场景的成功,源于其对三大技术难题的突破:
数据分布不一致的破解之道
工业数据常呈现"同工厂不同时段"或"同产品不同产线"的分布差异,迁移学习通过域适应技术,在特征层面消除这种差异,例如在风电案例中,模型学习的是"齿轮箱异常振动"这一物理本质,而非特定型号的振动频率范围。
2026年MIT团队提出的"动态域适应"算法,能实时监测数据分布变化并自动调整模型参数,在某化工企业的反应釜温控应用中,该算法使模型在季节变化时的性能波动从15%降至3%以内。
小样本学习的实现机制
工业场景中,新设备、新工艺的数据往往稀缺,迁移学习通过预训练+微调范式,让模型先在相关任务上学习通用知识,再针对新任务少量调整,这种"站在巨人肩膀上"的方式,使模型在仅有10%标注数据时就能达到传统方法80%的性能。
华为云在2026年推出的工业预训练模型库,包含3000个预训练特征提取器,覆盖机械加工、电子制造等12个行业,企业可直接调用这些特征,仅需少量自有数据即可构建专用模型。

跨模态学习的突破
工业数据常包含振动、温度、图像、文本等多模态信息,迁移学习通过跨模态对齐技术,挖掘不同模态间的关联,例如在设备故障诊断中,模型能同时学习振动信号的时频特征和运维日志的文本语义,提升诊断准确率。
健康中国与物联网应用热度持续上升,相关产业迎来新机遇 西门子在2026年发布的MindSphere平台,集成了跨模态迁移学习模块,在某钢铁企业的应用中,该模块通过融合高炉温度数据和操作工经验文本,将铁水质量预测误差从±5℃降至±1.5℃。
2026年的新趋势:迁移学习与工业元宇宙的融合
随着工业元宇宙的兴起,迁移学习正在拓展新的应用边界,在数字孪生场景中,物理设备的数据可迁移到虚拟空间进行仿真测试;在AR运维场景中,历史维修数据可迁移到实时指导系统,实现"经验即服务"。
某航空发动机厂商的实践极具前瞻性:他们构建了发动机的数字孪生体,通过迁移学习将物理世界的运维数据与虚拟世界的仿真数据融合,当真实发动机出现异常振动时,系统能在数字孪生中快速模拟多种维修方案,并将最优方案推荐给现场工程师,这种"虚实迁移"使维修决策时间从4小时缩短至20分钟。
挑战与未来:迁移学习的工业落地之路
尽管迁移学习在工业领域展现出巨大潜力,但其落地仍面临三大挑战:
-
数据隐私保护:跨企业数据迁移需解决商业机密泄露风险,2026年新实施的《工业数据安全管理办法》要求,迁移学习模型必须通过差分隐私或联邦学习技术实现"数据可用不可见"。
-
绿色标识与绿色低碳及3D打印技术热度持续攀升,相关技术取得新突破 模型可解释性:工业场景对模型决策透明度要求极高,某核电站曾因迁移学习模型给出模糊故障原因,导致停机检查损失超千万元,当前研究正聚焦于将物理规则融入模型架构,提升可解释性。
-
人才缺口:既懂工业又懂迁移学习的复合型人才稀缺,2026年人社部新增的"工业数据分析师"职业标准中,明确将迁移学习作为核心技能要求。
生态旅游与智慧医疗及智能微网热度持续攀升,相关领域迎来新突破 面对这些挑战,工业界正在探索新的解决方案,某制造企业与高校联合开发的"迁移学习即服务"平台,通过模块化工具链降低使用门槛;某行业协会发起的"工业迁移学习挑战