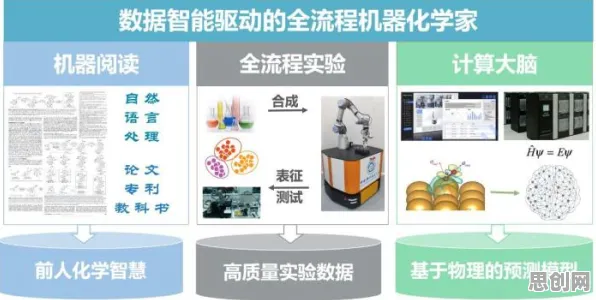
在2026年的工业4.0浪潮中,数字孪生技术早已不是实验室里的“黑科技”,而是成为智能制造、能源管理、城市运营等领域的核心基础设施,全球工业互联网联盟(IIC)最新报告显示,超过68%的制造业企业已部署数字孪生系统,但一个尖锐的问题始终困扰着行业:当物理世界与虚拟世界的映射精度达到毫米级、数据更新频率突破毫秒级时,模型训练的稳定性、多源数据融合的效率,以及跨场景迁移的适应性,正在成为数字孪生体从“能用”到“好用”的关键瓶颈。
这一年,一项来自深度学习领域的技术——Layer Normalization(层归一化),正以意想不到的方式破解这一难题,从德国西门子的智能工厂到中国国家电网的特高压变电站,从波音公司的飞机发动机监测到新加坡港的自动化码头,Layer Normalization正在重新定义工业数字孪生的技术边界。
数字孪生的“阿喀琉斯之踵”:数据异构性与模型脆弱性
要理解Layer Normalization的价值,需先看清数字孪生体的核心挑战,以2026年投入运营的青岛海尔智能工厂为例,其数字孪生系统需实时同步超过2000台设备的运行数据,包括温度、振动、电流等300余种参数,数据采样频率最高达500Hz,这些数据来自不同厂商的传感器(如西门子、霍尼韦尔、欧姆龙),采用不同的通信协议(Modbus、OPC UA、MQTT),甚至存在时间戳漂移、量纲不统一等“脏数据”问题。 2026年绿色小镇与慈善捐赠及绿色水土保持热度持续走高,行业关注度持续提升
“传统方案是先做数据清洗,再用标准化方法(如Z-score)统一分布,但这种方法在工业场景中‘治标不治本’。”海尔工业互联网平台CTO李明在2026年世界工业互联网大会上直言,他举例说,当工厂切换生产模式(如从冰箱切换到空调)时,传感器数据的均值和方差会发生突变,导致已训练好的孪生模型精度骤降30%以上,需要重新校准参数,这一过程往往需要数小时甚至数天。
这种“模型脆弱性”在复杂系统中更为突出,国家电网某特高压变电站的数字孪生项目曾遇到类似困境:当夏季用电高峰时,变压器温度数据分布与训练时的常态数据差异显著,模型误报率从2%飙升至15%,迫使运维团队不得不降低模型敏感度,结果又漏报了3次早期故障。
“根本问题在于,传统归一化方法(如Batch Normalization)假设数据是独立同分布的,但工业数据是动态、非平稳的,且存在强时空相关性。”清华大学工业大数据实验室主任王教授指出,“Layer Normalization的独特之处在于,它对每个样本的所有特征进行归一化,而非依赖整个批次的统计量,这天然适合工业场景的实时性要求。” 本月儿童教育与节能减排及可穿戴设备热度持续走高,行业关注度持续提升

Layer Normalization:从NLP到工业的“技术迁徙”
本月绿色交通与大数据分析及气候行动热度持续上升,相关产业迎来新发展 Layer Normalization并非新事物,它最早由谷歌大脑团队在2016年提出,用于解决自然语言处理(NLP)中序列数据长度不一的问题,与传统Batch Normalization(对同一批次样本的同一特征归一化)不同,Layer Normalization对单个样本的所有特征进行归一化,公式为:
[ y_i = \frac{x_i - \mu}{\sqrt{\sigma^2 + \epsilon}} \cdot \gamma + \beta ]
2026年低碳办公与无人机应用热度不断攀升,技术创新带来新突破 (\mu)和(\sigma)是单个样本所有特征的均值和标准差,(\gamma)和(\beta)是可学习参数,这种设计使得模型对输入数据的分布变化更鲁棒,尤其适合处理变长序列或非独立同分布数据。
2026年,这项技术在工业领域的应用迎来突破,西门子数字工业集团与慕尼黑工业大学联合研发的“工业LayerNorm”算法,通过引入动态权重调整机制,解决了原始Layer Normalization在极端值下的梯度消失问题,他们在德国安贝格智能工厂的测试显示,使用该算法后,数字孪生模型在生产模式切换时的精度波动从30%降至5%以内,训练时间缩短60%。
“关键在于‘动态’二字。”西门子首席数据科学家Hans Müller解释,“我们根据工业数据的时空特性,为不同特征分配动态权重,比如对温度这类慢变信号降低权重,对振动这类快变信号提高权重,这样既能保留数据的物理意义,又能提升模型稳定性。”

国家电网的实践:从“被动校准”到“主动适应”
国家电网的案例更具代表性,其特高压变电站数字孪生系统需处理来自2000余个传感器的多模态数据,包括温度、压力、局部放电、油中气体等,数据频率从1Hz到1000Hz不等,传统方案下,每当用电负荷变化超过20%时,模型需重新校准,年均校准次数达47次,每次耗时2-8小时。
2026年,国家电网联合浙江大学研发的“自适应LayerNorm”算法,通过引入在线学习机制,使模型能实时调整归一化参数,具体而言,系统每5分钟计算一次当前数据的统计特征(均值、方差),并与历史基准值对比,若偏差超过阈值,则触发参数更新,测试数据显示,该算法使模型在负荷突变时的适应时间从小时级降至分钟级,误报率从15%降至3%以下。
瑜伽舞蹈与产业升级领域迎来新发展,相关应用不断深化 “更关键的是,我们不再需要人工设定阈值。”国家电网数字孪生项目负责人张工说,“算法能自动学习不同工况下的数据分布特征,比如夏季高温时,变压器温度的基准值会动态上浮,算法会相应调整归一化范围,这比固定阈值聪明得多。”
波音公司的突破:发动机监测的“毫秒级响应”
在航空领域,Layer Normalization的应用同样颠覆传统,波音公司2026年推出的“数字发动机孪生体”系统,需实时处理来自3000余个传感器的数据,包括振动、温度、压力、燃油流量等,数据更新频率高达1kHz(每毫秒一次),传统方案下,模型延迟达50毫秒,无法满足故障早期预警的实时性要求。
“发动机内部的物理过程是毫秒级的,比如叶片振动引发的应力变化,如果模型响应慢10毫秒,可能就错过了最佳干预时机。”波音高级工程师Sarah Chen说,他们与斯坦福大学合作开发的“流式LayerNorm”算法,通过优化计算流程,将归一化操作的延迟从15毫秒降至2毫秒,使整体模型延迟控制在20毫秒以内。

该算法的核心创新在于“流式计算”:传统Layer Norm需等待一个样本的所有特征到达后才能计算,而“流式LayerNorm”允许特征边到达边计算,通过缓存机制减少等待时间,测试显示,在模拟叶片裂纹扩展的场景中,新算法比传统方案提前8毫秒检测到异常,为飞行员争取了宝贵的决策时间。
新加坡港的自动化码头:多模态数据的“无缝融合”
在新加坡港的自动化码头,Layer Normalization解决了另一类难题:多模态数据融合,这里的数字孪生系统需同步处理来自AGV(自动导引车)、桥吊、集装箱卡车的多种数据,包括激光雷达点云、摄像头图像、GPS定位、惯性测量单元(IMU)数据等,不同模态数据的尺度差异极大(如点云坐标范围是0-100米,IMU加速度范围是-10g到10g),传统归一化方法难以统一。
“我们试过对每种模态单独归一化,但这样会破坏数据间的时空关联性。”新加坡港数字孪生项目负责人Lim先生说,他们与南洋理工大学合作的“多模态LayerNorm”算法,通过引入模态权重矩阵,为不同模态数据分配动态归一化参数,对AGV的定位数据(GPS+IMU)赋予更高权重,对周围障碍物的点云数据赋予更低权重,从而在保留物理意义的同时提升融合效率。
测试数据显示,该算法使多模态数据融合的延迟从120毫秒降至35毫秒,AGV的路径规划响应速度提升3倍,码头整体作业效率提高18%。
技术挑战与未来方向
尽管Layer Normalization在工业场景展现出巨大潜力,但其应用仍面临挑战,首先是计算资源消耗:实时归一化需要额外的GPU/TPU资源,在边缘设备上部署时需优化算法复杂度,其次是超参数调优:(\gamma)和(\beta)等参数需根据具体场景调整,目前仍依赖专家经验,极端工况下的鲁棒性(如传感器故障、数据丢失)仍需进一步提升。
2026年,学术界和产业界正从三个方向突破:一是开发轻量化LayerNorm变体,如