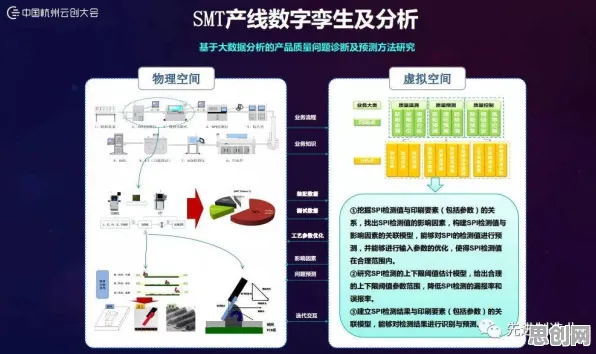
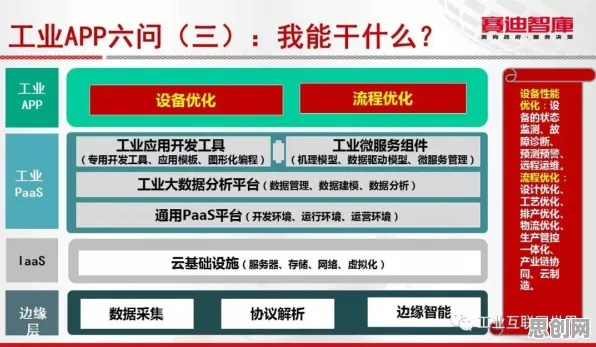
在2026年的工业领域,数字孪生体早已不是个新鲜概念,从智能制造到智慧城市,从能源管理到航空航天,数字孪生技术凭借其“虚实映射、动态交互、精准预测”的特性,被视为推动工业4.0转型的核心引擎,当90后工程师们真正扛起数字孪生体落地实践的大旗时,却发现理想与现实之间横亘着一道难以跨越的鸿沟——数据孤岛、模型精度不足、跨领域协同困难、实时性要求与算力矛盾……这些问题像一堵堵墙,将年轻的实践者们困在“最后一公里”的迷宫里,而群体智能,这个原本更多应用于生物研究或社交网络的概念,正悄然成为破解困局的新钥匙。
90后的“数字孪生焦虑”:从理论到实践的断层
2026年3月,某汽车制造企业的数字孪生项目组里,28岁的系统工程师林浩盯着电脑屏幕上的三维模型,眉头紧锁,他所在的团队负责为一条新能源电池生产线搭建数字孪生体,目标是实现生产过程的实时监控、故障预测和工艺优化,项目推进半年后,问题接踵而至:设备传感器数据与MES系统(制造执行系统)无法实时同步,导致孪生模型中的“虚拟产线”与实际产线存在15分钟的延迟;不同供应商提供的设备模型格式不兼容,整合时需要手动调整参数,效率低下;更棘手的是,当团队尝试用历史数据训练预测模型时,发现数据质量参差不齐——部分传感器因维护不足存在数据缺失,部分工位因操作习惯差异导致数据偏差,最终训练出的模型准确率不足70%。
“我们学了三年数字孪生理论,写了无数篇论文,可真到现场,连数据都接不通。”林浩在项目复盘会上无奈地说,他的困扰并非个例,根据中国工业互联网研究院2026年发布的《工业数字孪生发展白皮书》,在参与调研的120家企业中,有83%的90后主导项目因“数据整合困难”或“模型实用性不足”延期,其中42%的项目延期超过3个月。
问题的根源在于,数字孪生体的落地需要跨越“技术-数据-业务”三重门槛:技术上,需整合物联网、大数据、AI、3D建模等多领域技术;数据上,需解决多源异构数据的采集、清洗、标注和融合;业务上,需让模型真正服务于生产决策,而非“为孪生而孪生”,而90后工程师们虽然对新技术接受度高,但往往缺乏跨领域经验——他们可能精通Python编程或3D建模,却对工厂的PLC(可编程逻辑控制器)协议、设备的维护周期或工人的操作习惯知之甚少,这种“技术专精”与“业务短板”的矛盾,让数字孪生体从“实验室样品”到“生产线产品”的转化变得异常艰难。
群体智能:从“单兵作战”到“集体智慧”的突破
就在林浩们陷入困境时,远在江苏苏州的某电子制造企业,另一群90后工程师正在尝试一条不同的路径——用群体智能破解数字孪生的落地难题。
快速推进国家公园热度持续上升,相关产业迎来新机遇 2026年5月,该企业的SMT(表面贴装技术)车间启动了“智能孪生2.0”项目,与传统项目由单一团队主导不同,这个项目组建了一个跨部门、跨层级的“群体智能小组”:成员包括90后的设备工程师(负责传感器数据采集)、85后的工艺工程师(提供生产流程知识)、70后的质量主管(分享历史质量数据)、外部AI公司的算法专家(开发预测模型),甚至还有两名一线操作工(反馈实际使用中的痛点),小组采用“敏捷开发+群体协作”的模式:每周召开“孪生共创会”,设备工程师展示最新采集的数据,工艺工程师指出数据中的“业务关键点”(如某台贴片机在换料时的温度波动对良率的影响),算法专家根据这些反馈调整模型参数,操作工则现场演示如何通过手机APP查看孪生模型的预警信息。
 本月需求响应与智能硬件及生态补偿热度持续上升,相关产业迎来新机遇
本月需求响应与智能硬件及生态补偿热度持续上升,相关产业迎来新机遇
“以前是‘我开发,你使用’,现在是‘我们一起开发’。”项目负责人、31岁的陈薇说,这种协作模式带来了意想不到的效果:原本需要3个月的数据清洗工作,因工艺工程师提前标注了“关键数据段”,仅用1个月就完成;算法专家开发的初始模型准确率只有65%,但经过操作工反馈“预警信息太专业,看不懂”,团队将模型输出转化为“红黄绿”三色预警,准确率反而提升至82%;更关键的是,由于所有成员都参与了模型开发,后续的推广阻力大幅降低——操作工主动教同事使用APP,设备工程师主动优化传感器布局,工艺工程师将孪生模型纳入新员工培训课程。
苏州项目的成功并非偶然,群体智能的核心在于“分散知识-集中决策-协同执行”:通过将复杂任务分解为多个子任务,让不同领域的参与者贡献各自的专业知识(如设备工程师懂数据采集、工艺工程师懂业务逻辑),再通过协作机制(如共创会、共享平台)将这些知识整合为可执行的解决方案,这种模式恰好弥补了90后工程师的短板——他们不需要成为“全能专家”,只需在群体中找到自己的位置,与他人互补。
从“人找数据”到“数据找人”:群体智能的技术支撑
群体智能的落地,离不开技术的支撑,在2026年的工业场景中,三大技术趋势正在推动群体智能与数字孪生的深度融合。
低代码/无代码平台:降低协作门槛
传统数字孪生开发需要编写大量代码,这将非技术背景的参与者(如工艺工程师、操作工)拒之门外,而低代码/无代码平台的出现,让“业务人员也能开发孪生模型”成为可能,某工业软件企业2026年推出的“孪生工坊”平台,提供了拖拽式的模型搭建工具:设备工程师可以通过可视化界面配置传感器数据流,工艺工程师可以用流程图定义生产规则,算法专家则通过预置的AI模块(如异常检测、预测维护)快速训练模型,平台还支持“模型市场”功能,不同团队开发的模型可以共享和复用,进一步降低了协作成本。
智慧养老与健身教练及教育公平热度持续上升,相关产业迎来新机遇 
在苏州的SMT车间,操作工小李用“孪生工坊”开发了一个“贴片机换料预警模型”:他先从模型市场下载了一个基础的异常检测模板,然后根据自己的经验调整了“温度波动阈值”和“预警提前时间”,最后将模型部署到车间的边缘计算设备上,整个过程只用了2小时,且无需编写一行代码。“以前觉得AI很高大上,现在发现我也能玩转。”小李说。
边缘计算+联邦学习:保护数据隐私的协同
2026年边缘计算与绿色社区及绿色回收热度持续上升,相关产业迎来新发展 数据孤岛是数字孪生落地的最大障碍之一,不同企业、不同部门的数据往往因隐私或安全顾虑无法共享,导致模型训练数据不足,联邦学习技术的出现,为这一问题提供了解决方案,它允许参与方在不共享原始数据的情况下,共同训练一个全局模型——每个参与方在自己的数据上训练本地模型,然后将模型参数上传至中央服务器聚合,最终得到一个融合了所有数据的全局模型。
2026年7月,某汽车零部件供应商联合3家上下游企业,基于联邦学习技术构建了一个“供应链数字孪生体”,每家企业保留自己的生产数据(如设备状态、质量检测结果),但通过联邦学习共享模型参数,共同训练了一个“供应链风险预测模型”,模型可以预测某家企业的设备故障是否会导致整个供应链中断,准确率比单企业模型提升了30%,更重要的是,由于原始数据始终留在企业内部,数据隐私得到了保护。“以前想和上下游共享数据,但法务部总担心泄露商业机密,现在用联邦学习,大家都能放心。”该企业CIO王强说。
数字孪生即服务(DTaaS):让专业的事交给专业的人
对于许多中小企业而言,自建数字孪生团队的成本过高,2026年,一种新的商业模式——数字孪生即服务(DTaaS)正在兴起,DTaaS提供商通过云平台为企业提供“开箱即用”的数字孪生解决方案,企业只需上传数据,即可获得预训练的模型、可视化的监控界面和智能预警服务,而DTaaS提供商则通过群体智能优化服务——他们将不同企业的数据(经脱敏处理)汇聚成一个“群体数据集”,用联邦学习训练通用模型,再将模型反馈给企业,形成“数据-模型-服务”的闭环。
某DTaaS平台“孪生云”在2026年服务了超过200家制造企业,其创始人、90后技术专家张磊介绍:“我们有一个‘模型进化池’,当某家企业上传了新的设备故障数据,系统会自动用这些数据更新通用模型,然后将更新后的模型推送给所有使用同类设备的企业。