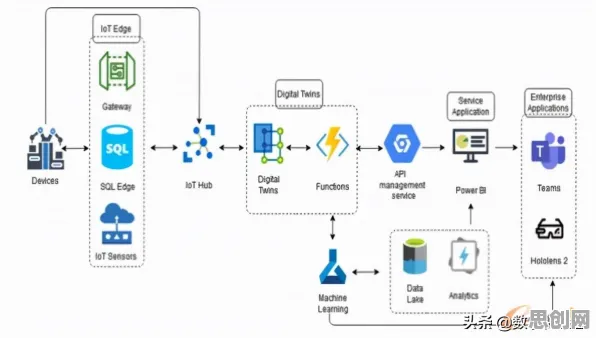
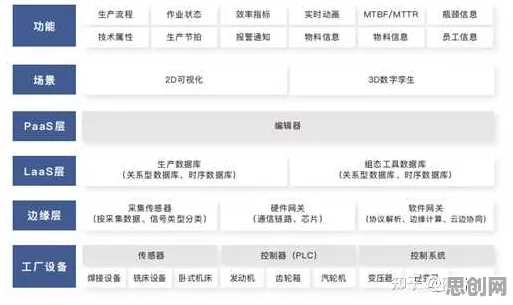
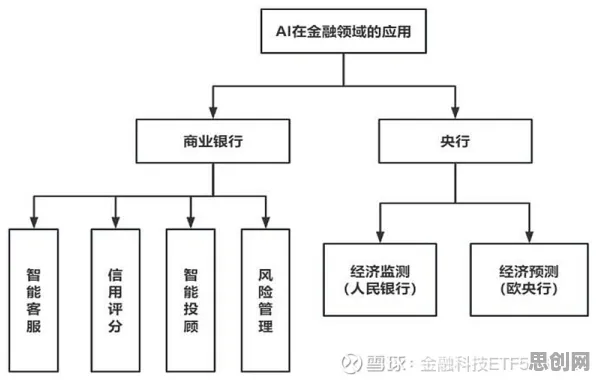
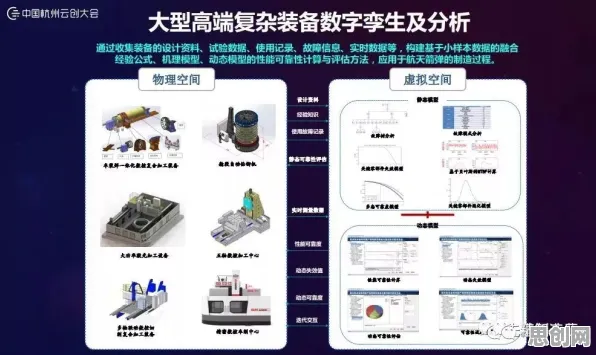
在2026年的工业领域,数字孪生技术早已不是新鲜词汇,但当人们深入探究其部署实践背后的逻辑时,会发现一个被忽视却至关重要的角色——扩散模型,这一原本在图像生成等领域大放异彩的模型,正悄然重塑工业数字孪生的底层架构,其影响之深远,足以颠覆我们对传统工业技术升级路径的认知。
从“模拟”到“生成”:数字孪生的范式跃迁
传统数字孪生的核心在于“模拟”,即通过传感器采集物理实体的数据,构建一个与之对应的虚拟模型,实现物理世界与数字世界的映射,这种模式在设备监控、故障预测等场景中发挥了重要作用,但也存在明显局限——虚拟模型的构建高度依赖历史数据和预设规则,面对复杂多变的工业环境,往往显得力不从心。
2026年,某汽车制造企业的案例生动展现了这一困境,该企业为提升生产线效率,部署了基于传统数字孪生的智能调度系统,系统通过采集设备运行数据,模拟生产流程,试图优化物料配送和工序安排,在实际运行中,系统却频繁“失灵”:当生产线因突发故障临时调整节奏时,虚拟模型无法及时生成新的调度方案,导致物料堆积或设备闲置,生产效率不升反降。
“我们投入了大量资源构建模型,但它的适应性太差,就像一个只会按剧本演戏的演员,遇到意外情况就束手无策。”该企业生产负责人无奈地表示,这一案例折射出传统数字孪生的致命弱点——缺乏“生成”能力,无法根据实时变化动态调整模型。
扩散模型的引入,为数字孪生带来了范式跃迁的可能,扩散模型通过逐步“去噪”的过程,从随机噪声中生成数据,其本质是一种“从无到有”的生成机制,在工业场景中,这意味着数字孪生不再局限于模拟已知状态,而是能够根据实时数据和环境变化,动态生成新的模型状态,实现真正的“自适应”。
扩散模型如何重塑工业数字孪生?
以2026年某钢铁企业的实践为例,该企业面临一个棘手问题:高炉炼铁过程中,炉内温度、压力等参数的微小波动都可能影响铁水质量,但传统数字孪生模型无法实时捕捉这些动态变化,导致质量控制滞后。
企业与科研团队合作,将扩散模型引入数字孪生系统,系统不再仅仅依赖传感器采集的实时数据,而是通过扩散模型的生成能力,结合历史数据和物理规律,动态预测炉内状态的变化趋势,当传感器检测到温度轻微上升时,模型不是简单报警,而是生成多种可能的后续场景:如果温度持续上升,铁水中的硅含量可能超标;如果及时调整风量,温度可能回落至正常范围。

“扩散模型就像一个‘智能参谋’,它不仅告诉我们现在发生了什么,还预测未来可能发生什么,并给出多种应对方案。”该企业技术总监这样评价,在实际运行中,这一系统使铁水质量波动降低了30%,吨钢能耗减少了5%,效果显著。
2026年物联网应用与社区公益及语言培训发展迅速,技术创新带来新突破 扩散模型的另一大优势在于其“数据效率”,传统数字孪生需要大量标注数据训练模型,而工业场景中,高质量标注数据往往稀缺且昂贵,扩散模型通过自监督学习,能够从海量未标注数据中提取特征,生成有价值的模型参数。
2026年,某风电企业部署的数字孪生系统就受益于这一特性,该企业拥有数百台风力发电机,但每台机的运行数据标注成本高昂,通过引入扩散模型,系统仅需少量标注数据即可训练出高精度模型,能够实时预测风机叶片的疲劳损伤,提前安排维护,避免了多起潜在故障,年维护成本降低了2000万元。
扩散模型与工业知识的深度融合
扩散模型在工业数字孪生中的成功,并非简单的“技术移植”,而是与工业知识的深度融合,2026年,这一趋势愈发明显——企业不再满足于将扩散模型作为“黑箱”工具,而是试图打开“黑箱”,将工业领域的专业知识和经验嵌入模型训练过程。
某化工企业的实践提供了典型案例,该企业生产过程中涉及多种复杂化学反应,传统数字孪生模型难以准确模拟反应动力学,企业与高校合作,将化学反应的热力学、动力学方程作为先验知识,融入扩散模型的训练框架,模型在生成反应状态时,不仅参考传感器数据,还遵循物理化学规律,预测精度大幅提升。

“我们不是让模型‘自由发挥’,而是给它‘划定边界’,确保生成的模型状态符合工业实际。”项目负责人解释道,这一实践使产品合格率从92%提升至97%,同时减少了15%的原料浪费。
扩散模型与工业知识的融合,还体现在“可解释性”上,传统深度学习模型常被诟病为“黑箱”,难以向工业操作人员解释决策依据,扩散模型通过生成中间过程数据,能够展示模型如何从噪声逐步“演化”出最终状态,为操作人员提供直观的理解路径。
2026年,某半导体制造企业将扩散模型应用于晶圆缺陷检测,模型不仅能够准确识别缺陷类型,还能生成缺陷形成的“演化路径”,帮助工程师追溯生产环节中的问题源头。“以前我们只能看到缺陷的结果,现在能看到它的‘成长史’,这对改进工艺帮助极大。”该企业工艺工程师表示。 热度持续走高青少年科学素养热度持续上升,相关产业迎来新机遇
挑战与未来:扩散模型的工业之路并非坦途
尽管扩散模型在工业数字孪生中展现出巨大潜力,但其部署实践仍面临诸多挑战,首先是计算资源需求,扩散模型的训练和推理需要大量算力,尤其在处理高维工业数据时,成本高昂,2026年,某汽车零部件企业曾尝试部署扩散模型驱动的数字孪生系统,但因服务器成本超出预算,最终不得不缩减模型规模,影响了效果。
数据质量问题,工业数据往往存在噪声、缺失值等问题,扩散模型虽对数据标注要求较低,但对数据质量仍有一定依赖,某食品企业部署系统时,因传感器故障导致部分数据失真,模型生成的状态与实际偏差较大,险些引发生产事故。

工业场景的复杂性也考验着扩散模型的适应性,不同行业、不同企业的生产流程差异巨大,扩散模型需要针对具体场景进行定制化开发,这对企业的技术能力提出了更高要求。
面对这些挑战,2026年的工业界正在探索解决方案,一些企业通过边缘计算将部分模型推理任务下沉到设备端,降低中心服务器负担;另一些企业则开发数据清洗工具,提升数据质量;还有企业与科研机构合作,构建通用型扩散模型框架,减少定制化开发成本。
扩散模型:工业数字化的“新引擎”?
从模拟到生成,从“黑箱”到可解释,扩散模型正在重塑工业数字孪生的底层逻辑,2026年的实践表明,这一技术不仅提升了数字孪生的适应性和精度,还为工业知识的沉淀和传承提供了新途径。
在某航空发动机企业的案例中,扩散模型被用于构建发动机寿命预测系统,系统不仅能够预测剩余寿命,还能生成发动机性能退化的“数字档案”,记录每个部件的历史状态变化,这些数据成为企业宝贵的知识资产,为新一代发动机研发提供了重要参考。
“扩散模型让数字孪生从‘工具’升级为‘知识库’,它不仅服务于当前生产,还为未来创新积累数据。”该企业首席技术官如此评价,这一观点正被越来越多企业认同——扩散模型不仅是技术升级,更是工业数字化思维的转变。 本月能源转型与电子商务热度持续上升,相关产业迎来新机遇
展望未来,扩散模型与工业数字孪生的融合将更加深入,随着5G、物联网等技术的发展,工业数据的采集和传输将更加高效,为扩散模型提供更丰富的“原料”;量子计算等新兴技术的突破,可能解决扩散模型的算力瓶颈,推动其向更复杂场景拓展。
2026年的工业界,一场由扩散模型驱动的数字孪生革命正在悄然发生,它颠覆了我们对传统工业技术的认知,也为我们揭示了未来工业数字化的新可能——一个更智能、更自适应、更知识驱动的工业世界,或许正从扩散模型的“噪声”中逐步生成。