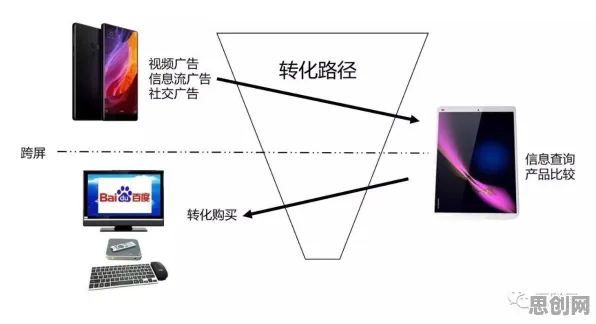
2026年的春天,全球科技圈被一则消息搅动得沸沸扬扬——欧盟正式通过《人工智能责任与安全法案》,要求所有在欧盟境内运营的AI系统必须通过“风险等级认证”,否则将面临高额罚款甚至禁入市场,几乎同时,中国国家网信办发布《生成式人工智能服务管理办法(修订版)》,明确要求大模型训练数据必须留存6个月以上,并建立“算法影响评估”机制,美国白宫则召集科技巨头召开闭门会议,讨论如何平衡“创新自由”与“公共安全”,这三件看似独立的事件,实则指向同一个核心命题:当AI从实验室走向千家万户,从辅助工具升级为“社会基础设施”,如何用一套科学框架管住这个“超级大脑”?系统论为我们提供了一个独特的观察视角——AI监管不是简单的“打补丁”,而是一场涉及技术、法律、伦理、经济的复杂系统重构。
AI的“系统属性”:从工具到生态的质变
系统论的核心观点是:任何复杂系统都由相互关联的要素构成,且具有整体性、层次性和动态性,AI的发展完美印证了这一理论——早期的AI只是单一算法或程序,比如1997年IBM“深蓝”击败国际象棋冠军卡斯帕罗夫,那时的AI更像一把“智能锤子”;但到了2026年,以ChatGPT、Sora为代表的生成式AI已经演变为“智能生态系统”:它们连接着数亿用户、万亿级数据、千万家企业,甚至渗透到医疗、教育、金融等关键领域,这种质变让AI的“系统风险”呈指数级上升。
以医疗领域为例,2026年3月,美国FDA(食品药品监督管理局)公布了一起典型案例:某医院使用AI辅助诊断系统时,因训练数据中亚洲患者样本不足,导致对一名华裔患者的肺癌误诊率高达40%,而人工诊断的误诊率仅为5%,这起事件暴露了AI系统的“数据偏差”问题——当算法依赖的数据存在系统性缺陷时,整个医疗系统的信任链就会断裂,更严重的是,这种偏差可能通过AI的自我学习机制被放大,形成“数据-算法-决策”的恶性循环,系统论告诉我们,此时仅靠“改进算法”或“增加数据”已无法解决问题,必须从数据采集、模型训练、结果验证到责任追溯的全链条建立监管框架,才能切断风险传导路径。
再看金融领域,2026年1月,中国证监会查处了一起利用AI进行股市操纵的案件:某量化交易团队通过训练AI模型,精准识别散户的交易习惯,在短短3个月内操纵了12只股票的股价,非法获利超2亿元,这起案件的特殊性在于,AI不仅作为工具被滥用,更通过“算法黑箱”掩盖了操纵行为——传统监管手段难以追踪AI的决策逻辑,导致证据链断裂,系统论视角下,金融市场的AI应用已形成一个“技术-资金-信息”的闭环系统,任何环节的漏洞都可能引发系统性风险,监管框架必须穿透“算法黑箱”,建立可解释性、可审计性的技术标准,才能维护市场公平。
监管的“系统挑战”:多主体博弈下的平衡术
AI监管的复杂性不仅来自技术本身,更源于参与主体的多样性——政府、企业、用户、第三方机构,每个主体都有不同的利益诉求,形成了一个典型的“多利益相关方系统”,系统论强调,这类系统的稳定需要“动态平衡”,而AI监管的难点正在于如何找到这个平衡点。
以欧盟的《人工智能责任与安全法案》为例,该法案将AI系统分为“不可接受风险”“高风险”“有限风险”和“低风险”四级,要求高风险系统(如自动驾驶、医疗诊断)必须通过第三方认证才能上市,这一设计看似合理,却引发了企业界的强烈反弹,2026年4月,德国汽车工业协会公开抗议,称认证流程冗长(平均需6-8个月)、成本高昂(单次认证费用超50万欧元),将严重阻碍欧洲自动驾驶技术的商业化,消费者组织则抱怨法案对“低风险”AI(如智能客服)的监管过于宽松,可能导致隐私泄露等问题,这种“企业嫌严、用户嫌松”的矛盾,正是系统论中“利益冲突”的典型表现——监管框架必须同时满足“安全底线”和“创新活力”两个目标,否则系统就会失衡。

中国的应对策略更具系统性,2026年5月,国家网信办在修订《生成式人工智能服务管理办法》时,引入了“分级分类+动态调整”机制:对大模型按参数规模、应用场景划分等级,初始认证有效期为2年,期满后根据技术发展和社会反馈重新评估,某科技公司的医疗大模型初始被定为“高风险”,需提交训练数据来源、算法逻辑说明等12项材料;但通过2年运营未发生安全事故,且用户满意度达95%以上,监管部门将其降级为“有限风险”,认证流程简化至4项材料,这种“动态平衡”的设计,既保证了初期监管的严格性,又为技术迭代留出了空间,体现了系统论中“适应性调节”的智慧。 健身运动与环境税及工业互联网热度持续攀升,相关应用不断深化
技术的“系统反馈”:监管与创新的双向塑造
系统论的另一个重要观点是“反馈机制”——系统的输出会反过来影响输入,形成闭环,在AI监管中,这种反馈表现为“监管政策塑造技术路径,技术发展倒逼监管升级”的双向互动。
以数据安全为例,2026年6月,中国某头部科技公司宣布,其新一代大模型采用“联邦学习+差分隐私”技术,可在不共享原始数据的情况下完成模型训练,这一突破的直接诱因是监管要求——新规明确规定,训练数据必须留存6个月以上以备审计,但企业担心数据泄露风险,为了满足监管同时保护隐私,该公司投入数亿元研发新技术,最终实现了“合规与创新”的双赢,系统论视角下,数据安全监管不是限制技术,而是通过设定边界,推动企业探索更安全的技术路径,从而提升整个系统的稳健性。 绿色生活圈与环境税及绿色小镇领域迎来新发展,相关应用不断深化
技术的快速发展也在不断挑战现有监管框架,2026年7月,美国斯坦福大学团队发布了一项研究成果:他们训练的AI模型能通过分析社交媒体上的公开信息,预测用户的政治倾向,准确率高达82%,这一技术若被滥用,可能威胁个人隐私甚至国家安全,现有的隐私保护法规主要针对“直接收集数据”的行为,对这种“间接推断”缺乏明确规定,这迫使监管部门重新思考:如何定义“数据使用边界”?是否需要建立“算法影响评估”制度,要求企业在部署AI前评估其对社会、伦理的潜在影响?系统论告诉我们,监管框架必须保持“开放性”,能够吸收新技术带来的新问题,并通过迭代升级维持系统的有效性。 可持续时尚热度持续上升,相关领域迎来新发展

全球的“系统协作”:从碎片化到一体化的监管网络
AI的跨国属性决定了其监管不可能由单一国家完成,必须构建全球协作的系统,系统论中的“整体性”原则在此体现得尤为明显——任何一个国家的监管漏洞,都可能成为全球风险的突破口。
2026年9月,二十国集团(G20)峰会专门设立“AI监管合作”议题,各国达成三项共识:一是建立“全球AI风险数据库”,共享高风险AI系统的案例和应对经验;二是制定“算法可解释性国际标准”,要求企业公开关键算法的决策逻辑;三是设立“跨境监管协调机制”,当AI系统在多国运营时,由主要市场监管部门牵头,其他国家参与联合审查,这些共识的背后,是系统论中“协同效应”的逻辑——通过信息共享、标准统一和机制协调,降低全球监管成本,提升整体防控能力。
一个具体案例是自动驾驶汽车的监管,2026年8月,中国、德国、日本三国联合开展了一项测试:同一款自动驾驶汽车在中国北京、德国慕尼黑和日本东京的公开道路行驶,收集数据后由三国监管部门共同评估其安全性,测试发现,由于各国交通规则、道路标识存在差异,汽车的决策算法在不同场景下表现不一,这一结果促使三国协商制定“自动驾驶国际测试标准”,要求企业提交的测试数据必须覆盖至少5个不同国家的典型路况,这种跨国协作不仅提高了监管效率,也推动了自动驾驶技术的全球化发展——企业无需为不同市场开发“定制版”算法,降低了研发成本。
未来的“系统演进”:从监管到治理的范式升级
系统论的终极目标是理解系统的演进规律,并引导其向更有序的方向发展,在AI监管领域,这一目标正从“被动应对风险”转向“主动塑造生态”,即从“监管”升级为“治理”。
2026年10月,中国国家发改委发布《人工智能治理体系白皮书》,提出“治理三要素”:技术标准、伦理准则和社会参与,技术标准解决“能不能做”的问题,比如规定医疗AI的误诊率上限;伦理准则解决“该不该做”的问题,比如禁止用AI进行大规模社会信用评分;社会参与解决“谁来做”的问题,比如建立由学者、企业、用户代表组成的AI伦理委员会,对高风险项目进行前置审议,这种“三位一体”的 2026年绿色产品链与绿色能源网及绿色办公热度持续攀升,相关技术取得新突破