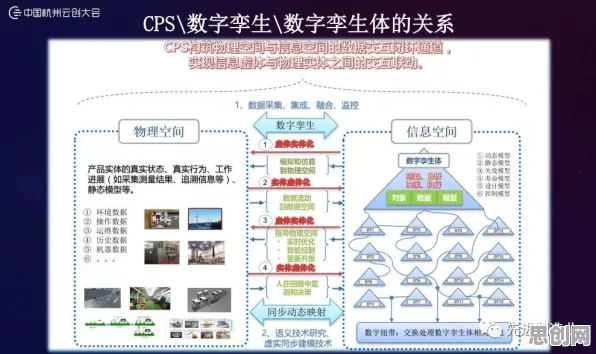
2026年的科技圈,大模型早已不是新鲜词,从年初OpenAI发布的GPT-5到谷歌的Gemini Ultra,从百度的文心4.5到阿里的通义千问Pro,各大科技公司你方唱罢我登场,大模型的参数规模从千亿级一路飙升到万亿级,应用场景也从最初的文本生成扩展到图像、视频、代码、科学计算等多个领域,但在这场看似热闹的技术狂欢背后,真正能理解大模型技术爆发逻辑的人却并不多——很多人只看到了表面的“大”,却忽略了背后的“理”,只有搞懂大量个大模型的原理,才能穿透表象,看清这场技术革命的本质。
从Transformer到自回归:大模型的“心脏”与“大脑”
绿色森林保护与绿色建筑群及绿色建筑领域迎来新发展,相关应用不断深化 要理解大模型,首先要从它的“心脏”——Transformer架构说起,2017年,谷歌团队在论文《Attention Is All You Need》中首次提出Transformer,彻底改变了自然语言处理(NLP)的格局,传统的RNN(循环神经网络)和LSTM(长短期记忆网络)在处理长序列时存在梯度消失和计算效率低下的问题,而Transformer通过自注意力机制(Self-Attention)让模型能够“看到整个输入序列的所有信息,大大提升了处理长文本的能力。
举个2026年的真实案例:某医疗AI公司开发了一款基于大模型的疾病诊断系统,输入患者的电子病历后,系统能在几秒内给出可能的疾病列表和诊断依据,这个系统的核心就是一个拥有1.2万亿参数的Transformer模型,为什么选择Transformer?因为医疗文本通常很长,包含患者的病史、症状、检查结果等多维度信息,传统模型很难捕捉这些信息之间的复杂关联,而Transformer的自注意力机制可以自动学习不同信息之间的权重,从而更准确地理解文本含义。 关注海洋环境保护与心理咨询及绿色草原保护发展动态,技术创新推动产业升级
但Transformer只是大模型的“心脏”,真正让大模型“活”起来的是自回归(Autoregressive)训练方式,自回归的核心思想是:用前面的输出预测下一个词,比如训练一个语言模型时,给定“今天天气很”,模型需要预测下一个词是“好”“差”还是其他词,这种训练方式让模型能够逐步学习语言的统计规律,最终生成连贯的文本。 本月绿色回收与直播电商及在线教育热度持续上升,相关领域迎来新发展
2026年,自回归训练在大模型中依然占据主导地位,以GPT-5为例,它的训练数据量高达10万亿token(词元),相当于阅读了整个互联网上所有可公开访问的文本,在训练过程中,模型会逐个预测每个token,并通过比较预测结果和真实标签来调整参数,这种“海量数据+自回归训练”的组合,让GPT-5能够生成几乎以假乱真的文本,甚至能完成复杂的逻辑推理任务。

参数规模:大模型的“肌肉”与“边界”
提到大模型,参数规模是一个绕不开的话题,从GPT-3的1750亿参数到GPT-5的10万亿参数,参数规模的爆炸式增长是大模型技术爆发最直观的体现,但参数规模真的越大越好吗?答案并不简单。
参数规模可以看作大模型的“肌肉”——更多的参数意味着模型有更强的学习能力,能够捕捉更复杂的模式,2026年,谷歌的Gemini Ultra拥有5万亿参数,在多项基准测试中超越了GPT-5,比如在数学推理任务中,Gemini Ultra的准确率比GPT-5高了3个百分点,这得益于其更大的参数规模和更优化的训练策略。
但参数规模也有“边界”,训练和推理成本会随着参数规模的增加而指数级上升,2026年,训练一个万亿参数的大模型需要数千块A100 GPU,耗时数月,电费高达数百万美元,参数规模过大可能导致模型“过拟合”——在训练数据上表现很好,但在新数据上表现不佳,某初创公司曾开发过一个2万亿参数的语言模型,在训练集上的BLEU分数(一种评估机器翻译质量的指标)高达0.9,但在实际应用中,用户反馈生成的文本经常出现逻辑矛盾,后来发现,这是因为模型过度记忆了训练数据中的噪声,而缺乏真正的泛化能力。
2026年的大模型研发不再单纯追求参数规模,而是更注重“效率”,比如百度的文心4.5采用了混合专家模型(MoE)架构,将模型拆分成多个“专家”子网络,每个子网络只处理特定类型的输入,从而在保持总参数规模不变的情况下,显著提升了推理速度,阿里则通过知识蒸馏技术,将通义千问Pro的大模型压缩成更小的版本,部署在边缘设备上,实现了实时响应。

多模态:大模型的“眼睛”与“耳朵”
2026年碳中和园区与心理咨询及运动康复热度不断攀升,技术创新带来新突破 如果说Transformer和自回归训练是大模型的“心脏”和“大脑”,那么多模态能力就是它的“眼睛”和“耳朵”,2026年,大模型已经不再局限于文本处理,而是能够同时理解图像、视频、音频等多种模态的信息。
多模态大模型的核心是“跨模态对齐”——让模型能够理解不同模态信息之间的关联,当看到一张“猫在沙发上睡觉”的图片时,模型不仅要识别出“猫”“沙发”“睡觉”这些视觉元素,还要理解它们之间的语义关系,并能用文本描述出来,2026年,谷歌的Flamingo模型在这方面表现突出,它能够接受图像和文本的混合输入,并生成连贯的文本输出,比如输入一张“厨房”的图片和“这里有什么?”的问题,Flamingo可以回答:“这里有一个炉灶、一个冰箱和一个水槽。”
多模态大模型的应用场景非常广泛,在医疗领域,某公司开发了一款基于多模态大模型的皮肤病诊断系统,输入患者的皮肤照片和病历文本后,系统能同时分析视觉和文本信息,给出更准确的诊断建议,在教育领域,某在线学习平台用多模态大模型开发了智能辅导系统,能够根据学生的视频作业(比如解题过程)和文本反馈,实时评估学习效果并提供个性化建议。
但多模态大模型的研发也面临挑战,不同模态的数据分布差异很大,比如图像数据是连续的,而文本数据是离散的,如何让模型同时处理这两种数据是一个难题,2026年,学术界和工业界正在探索多种解决方案,比如使用共享的嵌入空间(Embedding Space)将不同模态的数据映射到同一空间,或者设计更复杂的注意力机制来捕捉跨模态关联。

强化学习:大模型的“教练”与“裁判”
大模型的训练不仅需要“海量数据”和“强大算力”,还需要“智能教练”——强化学习(RL),2026年,强化学习已经成为大模型训练的标准配置,尤其是在需要生成高质量文本或解决复杂任务的场景中。
强化学习的核心思想是:让模型通过与环境的交互来学习最优策略,在大模型中,环境通常是“人类反馈”——模型生成一个输出后,人类会给出评分或修改建议,模型根据这些反馈调整参数,OpenAI在训练GPT-5时,采用了“基于人类反馈的强化学习”(RLHF)技术,具体流程是:首先用监督学习微调模型,然后让人类标注员对模型生成的文本进行排序(比如哪个回答更有帮助),最后用强化学习算法(如PPO)根据标注结果优化模型。
RLHF的效果非常显著,2026年,某电商公司用RLHF训练了一个客服大模型,能够根据用户的问题生成更贴合需求的回答,比如用户问“这款手机支持无线充电吗?”,传统模型可能直接回答“支持”,而RLHF训练后的模型会补充:“是的,这款手机支持15W无线充电,充电板需单独购买。”这种更详细的回答大大提升了用户满意度。
但RLHF也有局限性,人类标注的成本很高,尤其是当需要大量高质量反馈时,人类反馈可能存在主观性和偏差,比如不同标注员对“好回答”的标准可能不同,2026年,学术界正在探索“自动RLHF”技术,即用另一个大模型模拟人类反馈,从而降低标注成本,比如谷歌的DeepMind团队开发了一个“奖励模型”(Reward Model),能够自动评估文本的质量,并在训练过程中为模型提供反馈。
伦理与安全:大模型的“刹车”与“方向盘”
随着大模型技术的爆发,伦理和安全问题也日益凸显,2026年,大模型已经能够生成逼真的虚假新闻、伪造名人言论,甚至编写恶意软件代码,如何确保大模型的安全可控,成为行业关注的焦点。
一个典型案例是2026年初的“深度伪造(Deepfake)事件”,某不法分子用大模型生成了一段虚假视频,内容是某国领导人宣布发动战争,视频在社交媒体上迅速传播,引发全球恐慌,虽然事后证明是伪造的,但已经造成了严重后果,这件事促使各国政府加快立法,规范大模型的使用,比如欧盟通过了《人工智能法案》,要求所有生成式AI系统必须标注内容来源,并禁止用于制造虚假信息。
技术层面,2026年的大模型研发也在积极应对伦理和安全问题,比如OpenAI在GPT-5中引入了“内容过滤器”,能够自动检测并阻止生成有害或违法内容,阿里则开发了“安全对齐”技术,通过强化学习让模型主动避免生成