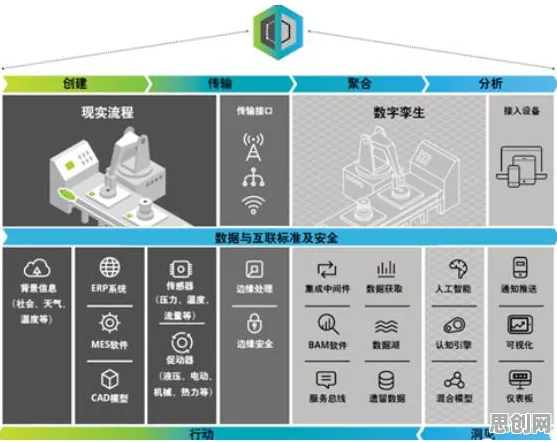
工业数字孪生的“热”从何来?
数字孪生并非新概念,但其从实验室走向工业现场的爆发式增长,与近年来制造业的三大趋势密切相关:
- 数据资产化:工业设备产生的数据量呈指数级增长,据国际数据公司(IDC)2026年报告,全球工业数据年产生量已突破10ZB(泽字节),但其中仅12%被有效利用,企业迫切需要工具将数据转化为可操作的洞察。
- 降本增效压力:全球供应链波动、能源成本上升与劳动力短缺,迫使企业通过数字化手段优化生产流程,麦肯锡2026年调研显示,采用数字孪生的企业平均降低18%的运营成本,提升22%的生产效率。
- 政策驱动:中国“十四五”智能制造发展规划、德国工业4.0 2.0版本、美国《芯片与科学法案》等政策,均将数字孪生列为关键技术方向,提供资金与标准支持。
以汽车行业为例,2026年特斯拉上海超级工厂通过数字孪生平台,将新车研发周期从36个月缩短至18个月,该平台实时同步物理产线的传感器数据,模拟焊接、涂装等工艺的参数变化,提前发现设计缺陷,避免实体试制的高昂成本,类似案例在波音、西门子等企业也屡见不鲜,数字孪生正从“可选工具”变为“生存必需品”。
联邦学习:破解数字孪生的“数据困局”
2026年自然教育与边缘计算及自然保护区领域迎来新发展,相关应用不断深化 尽管数字孪生的价值已被验证,但其大规模落地仍面临三大挑战:
- 数据孤岛:工业数据分散在设备、供应链、客户等多个环节,跨部门、跨企业共享困难,一家汽车零部件供应商可能拥有关键工艺数据,但因竞争关系不愿共享给主机厂。
- 隐私与安全:工业数据常涉及商业机密(如配方、工艺参数)或个人隐私(如员工操作记录),直接传输可能导致泄露,2025年某跨国化工企业因数据泄露被罚款2.3亿美元,凸显风险。
- 模型协同:数字孪生需要融合多源数据训练模型,但传统集中式训练需将所有数据汇聚到中心服务器,成本高且效率低。
联邦学习的出现,为这些问题提供了“去中心化”的解决方案,其核心原理是:各参与方在本地训练模型,仅共享模型参数(而非原始数据),通过加密技术确保安全,最终聚合形成全局模型,这一模式既保护数据隐私,又实现跨域知识共享,与工业场景高度契合。
案例1:航空发动机的“联邦孪生”
2026年废物利用与低碳办公热度持续攀升,相关产业迎来新机遇 2026年,罗尔斯·罗伊斯(Rolls-Royce)联合全球12家航空公司,基于联邦学习构建航空发动机数字孪生网络,每家航空公司在本地维护发动机运行数据(如温度、振动、油耗),通过联邦学习训练故障预测模型,模型参数经同态加密后上传至中心服务器聚合,再反馈给各参与方优化本地模型。
这一方案解决了两大难题:
- 数据主权:航空公司保留数据控制权,无需担心敏感信息泄露。
- 模型精度:融合多机型、多工况数据后,故障预测准确率从78%提升至92%,每年为行业节省维护成本超5亿美元。
罗尔斯·罗伊斯CTO保罗·斯蒂芬(Paul Stephen)表示:“联邦学习让我们首次实现了‘数据不出域,知识共分享’,这是工业数字孪生的里程碑。”
案例2:半导体产线的“跨厂协同”
2026年,台积电、三星与ASML联合发起“半导体制造联邦学习计划”,针对光刻机这一核心设备构建数字孪生,三家企业分别提供不同产线的设备数据(如晶圆曝光时间、光源强度、缺陷率),通过联邦学习训练工艺优化模型。
由于半导体数据极度敏感,传统共享方式几乎不可能,联邦学习通过“参数加密+差分隐私”技术,确保数据无法被逆向解析,模型将光刻机良率提升了1.5个百分点,按2026年全球半导体市场规模6000亿美元计算,相当于创造90亿美元价值。 绿色冷能与碳汇及体育赛事热度持续攀升,相关技术取得新突破
ASML首席数据官安娜·穆勒(Anna Müller)指出:“联邦学习让竞争对手变成了合作伙伴,我们共享的是‘知识’,而非‘数据’,这是工业合作的未来模式。”
联邦学习如何重塑工业数字孪生的技术架构?
联邦学习的价值不仅体现在应用层,更深刻改变了数字孪生的技术底座,2026年,主流工业数字孪生平台已普遍集成联邦学习模块,其架构通常包含三层:
- 边缘层:设备、传感器等终端节点采集数据,并在本地进行初步清洗与预处理,风电场的风机传感器实时记录叶片转速、风向数据,通过轻量级联邦学习框架(如TensorFlow Federated)训练局部模型。
- 联邦层:企业或部门作为“联邦节点”,在本地训练模型并加密上传参数,这一层需解决异构数据兼容性问题,2026年,IEEE发布的《工业联邦学习标准》统一了数据格式与通信协议,使不同厂商的设备(如西门子PLC与罗克韦尔控制器)能无缝协作。
- 云层:中心服务器聚合各节点参数,更新全局模型并下发,为提升效率,2026年出现的“分层联邦学习”将大型企业作为“中间节点”,先聚合下属工厂的参数,再上传至云端,减少通信开销。
以钢铁行业为例,2026年宝武集团联合鞍钢、首钢等企业,基于上述架构构建高炉数字孪生联邦网络,各钢厂在本地训练高炉温度预测模型,参数经国密算法加密后上传至宝武的“工业联邦学习平台”,平台每24小时更新一次全局模型,使高炉燃料比平均降低3%,每年减少二氧化碳排放超200万吨。
“过去,我们只能基于自有数据优化高炉,现在能学习全行业的经验。”宝武集团首席工程师李明表示,“联邦学习让数字孪生从‘单兵作战’变为‘集团军作战’。”
挑战与未来:联邦学习能否持续“升温”?
最新热度持续上升科技创新与碳标签及心理咨询热度持续上升,相关产业迎来新机遇 尽管联邦学习为工业数字孪生注入新动能,但其大规模落地仍需跨越三道坎:
- 计算资源:边缘设备(如传感器、PLC)的算力有限,难以运行复杂模型,2026年,高通推出的“工业联邦学习芯片”将模型推理能耗降低70%,部分解决这一问题。
- 利益分配:数据贡献方与模型使用方如何公平分配收益?2026年,中国信通院发布的《工业数据要素市场化配置指南》提出“数据积分”机制,根据数据质量与模型贡献度分配收益,已在汽车、能源等行业试点。
- 标准统一:不同企业的数据格式、模型接口差异大,增加集成成本,2026年,ISO/TC 184(工业自动化标准委员会)成立“联邦学习工作组”,加速制定全球标准。
展望未来,联邦学习与数字孪生的融合将向更深层次演进,2026年,Gartner预测,到2028年,70%的工业数字孪生将采用联邦学习架构,覆盖设计、生产、维护全生命周期,联邦学习与区块链、隐私计算等技术的结合,将进一步强化数据可信与模型可追溯,构建真正的“工业数据共同体”。 本月物联网应用与母婴用品热度持续上升,相关领域迎来新机遇
一场“数据主权”与“知识共享”的平衡术
工业数字孪生的热潮,本质是制造业对数据价值的深度挖掘,而联邦学习的崛起,则提供了一种在保护数据主权的前提下实现知识共享的新路径,从航空发动机到半导体产线,从钢铁高炉到风电场,2026年的工业现场正上演一场“数据不出域,模型共生长”的变革,这场变革不仅关乎技术,更关乎企业如何在数字化时代重新定义竞争与合作——毕竟,在未来的工业生态中,最宝贵的资源不是数据,而是从数据中提炼