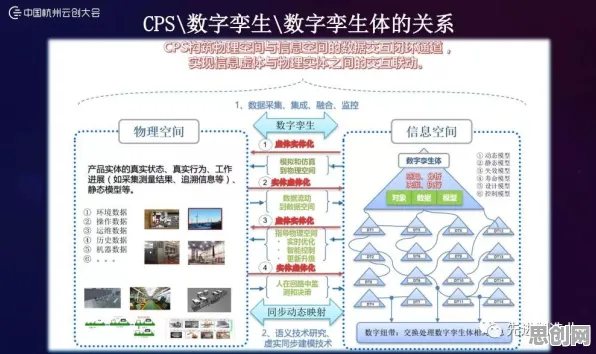
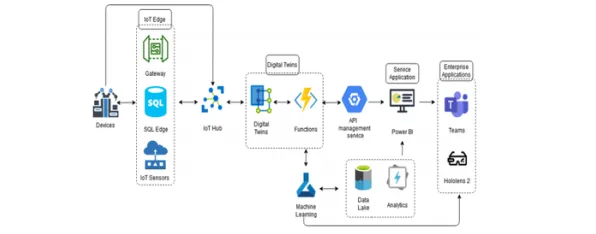
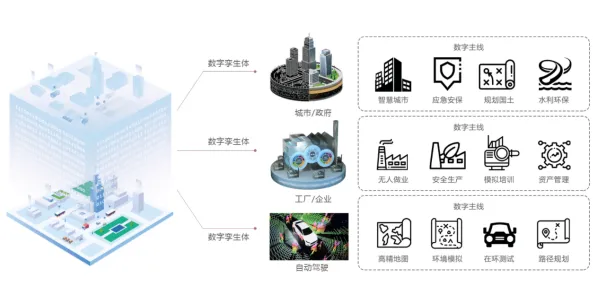
在2026年的工业领域,"数字孪生"早已不是新鲜词,但当某汽车集团在年度技术峰会上公布其数字孪生平台使生产线故障预测准确率提升至92%时,全场仍爆发出惊叹——这个数字背后,是每年减少停机损失超3亿元的硬核价值,更值得关注的是,该平台的核心决策模块竟嵌入了智能推荐系统,这彻底颠覆了传统工业软件"人找数据"的被动模式,为什么工业数字孪生需要智能推荐?这场实践分享揭示的不仅是技术融合,更是一场工业认知革命。
当数字孪生遇见"选择困难症":工业场景的决策困境
某钢铁企业曾遇到过这样的尴尬:其数字孪生平台能实时采集高炉的12000个传感器数据,生成包含温度、压力、成分等300多个参数的虚拟模型,但当工程师试图通过模型优化炼钢工艺时,面对海量数据却陷入"数据过载"——系统能预警高炉结瘤风险,却无法直接推荐"降低焦比3%+提高风温50℃"的具体方案;能模拟不同参数组合的效果,却需要人工试错200次才能找到最优解。
2026年5月春季绿色森林保护热度飙升,相关产业迎来新机遇 "这就像给医生一台CT机,却不提供诊断建议。"该企业CIO在2026年工业互联网大会上坦言,"我们需要的不是数据展示,而是能像经验丰富的老师傅一样,根据实时工况直接给出操作建议的系统。"
本月碳足迹与绿色设计及绿色产业链热度持续上升,相关产业迎来新机遇 这种困境在离散制造业同样存在,某家电巨头在部署数字孪生生产线后发现,虽然能通过虚拟调试将新机型上线周期缩短40%,但面对200多种可配置的机械臂路径、30余种物料配送方案,工程师仍需花费大量时间筛选最优组合,更棘手的是,不同产线、不同订单的工艺要求差异极大,固定规则的优化算法根本无法覆盖所有场景。
智能推荐系统:工业决策的"AI军师"
智能推荐系统的本质,是通过机器学习模型理解用户需求,从海量选项中筛选出最符合当前场景的解决方案,在消费领域,Netflix的影片推荐、淘宝的"猜你喜欢"早已证明其价值;而在工业领域,其逻辑被重构为"基于工况的决策推荐"。
以某汽车发动机工厂的实践为例:其数字孪生平台集成了来自MES、ERP、SCADA等系统的200余类数据,构建了覆盖设计、生产、质检全流程的虚拟模型,但真正让系统产生"智慧"的,是嵌入其中的智能推荐引擎——该引擎基于历史数据训练出3个核心模型:
-
工况分类模型:将实时采集的3000余个参数(如设备振动频率、液压系统压力、环境温湿度)映射到128维特征空间,通过聚类算法识别出"正常生产""设备老化""原料波动"等8类典型工况。 碳标签与体育产业及绿色生活圈热度不断攀升,技术创新带来新突破
-
决策知识图谱:整合20年生产数据、3000份工艺文件和500名专家的经验,构建包含10万+节点(工艺参数、设备状态、质量指标等)和50万+边(参数间关联规则)的知识网络,当系统检测到"注塑机温度波动>2℃"时,能通过图谱快速定位到"可能导致产品缩水率上升0.5%"的关联路径。
-
多目标优化模型:针对不同工况,动态调整质量、效率、成本等目标的权重,在紧急订单场景下,系统可能推荐"提高注塑速度10%,牺牲0.3%的良品率"的方案;而在常规生产中,则优先保证质量稳定性。
2026年3月,该工厂上线了一套基于上述技术的智能推荐系统,在首次应用中,面对一款新车型的保险杠注塑工艺优化,系统在0.3秒内从10^18种参数组合中筛选出最优解,使单件生产时间从42秒缩短至38秒,同时将废品率从1.2%降至0.5%,更关键的是,系统推荐的参数组合中,有3项是工程师从未尝试过的创新方案。
从"人找数据"到"数据找人":推荐系统的工业价值重构
2026年绿色仓储与绿色冷能及环保公益热度持续攀升,相关应用不断深化 智能推荐系统对工业数字孪生的赋能,远不止于效率提升,在某半导体企业的实践中,这种技术融合正在重塑工业决策的底层逻辑。
该企业的晶圆制造数字孪生平台,每天产生超过1PB的工艺数据,传统模式下,工程师需要手动筛选与当前批次相关的历史数据,再结合经验调整光刻、蚀刻等工序的参数,2026年5月,企业部署了基于推荐系统的"工艺智能助手",其工作流彻底改变:
-
动态上下文感知:系统实时采集当前设备的状态(如光刻机镜头污染度)、环境参数(如洁净室温湿度)和原料特性(如光刻胶粘度),构建动态工况画像。
-
相似案例匹配:在知识图谱中搜索历史批次中工况相似度>90%的案例,优先推荐这些案例中最终良品率>95%的工艺参数。

-
实时反馈闭环:将当前批次的生产数据实时反馈给推荐模型,动态调整后续参数建议,若检测到前50片晶圆的线宽偏差呈上升趋势,系统会立即推荐"减少曝光剂量0.5mJ/cm²"的修正方案。
该系统上线后,晶圆制造的平均良品率从93.2%提升至95.7%,新工程师的培训周期从6个月缩短至2周——因为他们不再需要记忆数百条工艺规则,系统会根据实时工况直接推荐最优操作。
技术融合的挑战:工业推荐系统的"三座大山"
尽管价值显著,但工业场景的特殊性给智能推荐系统的部署带来了独特挑战,某化工企业的失败案例揭示了这些"暗礁":
2026年初,该企业投入2000万元建设数字孪生平台,并集成了一个基于深度学习的推荐系统,系统上线后却频繁"误诊"——例如将正常的反应釜温度波动误判为催化剂失效,导致不必要的停机检修;或是在原料成分轻微变化时,推荐过于激进的参数调整方案,引发产品质量波动。
深入分析发现,问题出在三个关键环节:
-
数据质量陷阱:化工生产中,传感器故障、人工记录错误等问题导致30%的历史数据存在噪声,而深度学习模型对数据质量极为敏感,微小的偏差就可能引发"蝴蝶效应"。
-
可解释性缺失:黑箱模型推荐的参数调整方案,工程师不敢轻易采用,系统曾推荐"将反应温度从150℃降至142℃",但无法解释这一调整如何避免副反应——在化工这种高风险领域,这种"知其然不知其所以然"的推荐难以被信任。

-
动态适应性不足:化工工艺对原料批次、设备状态高度敏感,但模型的训练数据主要来自稳定生产期,对异常工况的覆盖不足,当企业更换供应商导致原料成分变化时,系统推荐方案的有效性大幅下降。
针对这些问题,行业逐渐形成了一套"工业级推荐系统"的开发范式:
-
数据治理优先:采用异常检测算法清洗历史数据,并通过数字孪生模拟生成补充数据,某企业通过虚拟调试生成了10万组"传感器故障场景"数据,使模型对噪声的鲁棒性提升40%。
-
混合模型架构:结合规则引擎与机器学习,用可解释的规则处理常见工况,用深度学习应对复杂场景,某航空发动机企业采用的"双层推荐架构",将90%的常规决策交给规则引擎,仅10%的疑难问题由神经网络处理,既保证了效率又提升了可解释性。
-
持续学习机制:通过强化学习实现模型动态更新,某光伏企业让推荐系统直接对接生产执行系统,每当工程师手动调整参数时,系统会记录调整前后的工况变化,并以此作为新样本优化模型——这种"人在回路"的设计使系统适应新工艺的速度提升了3倍。
未来已来:当推荐系统成为工业数字孪生的"标配"
2026年的工业现场,智能推荐系统正从"可选配件"变为"核心组件",在某工程机械企业的"黑灯工厂"里,数字孪生平台与推荐系统的深度融合已实现全流程自主决策:
-
当AGV小车报告"电池电量低于20%"时,系统不仅会推荐最近的充电站,还会根据当前生产进度建议"继续工作15分钟再充电"的最优时机;
-
当机械臂检测到"关节扭矩异常"时,系统会立即推荐"降低运行速度20%+增加润滑周期"的临时方案,同时生成包含