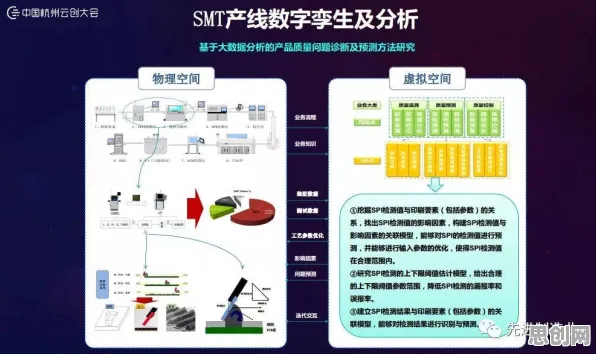
当“刷题量”成为KPI,在线教育陷入数据陷阱
2026年3月,北京海淀区某重点中学的家长群里流传着一张“学习数据对比表”:12岁的李明同学过去30天在某在线教育平台完成了127套数学试卷,正确率91.3%,排名班级第2;而同班同学王晓雨虽然只完成了89套试卷,但通过平台智能分析系统发现,她在“几何变换”和“概率统计”两个知识模块的错误率比李明低42%,这场看似普通的成绩对比,折射出当下在线教育领域一个尖锐的矛盾——当学习行为被拆解成可量化的数据指标,教育是否正在沦为一场“数据内卷”的竞赛?
教育部2026年发布的《全国在线教育发展白皮书》显示,我国K12在线教育用户规模已突破2.3亿,平台日均产生学习数据超过500TB,在这组光鲜数字背后,一个更值得关注的现象是:学生平均单日在线学习时长从2020年的2.1小时攀升至2026年的4.7小时,但PISA(国际学生评估项目)最新测试结果显示,中国学生在“创造性问题解决”和“批判性思维”两个维度的得分较2018年下降了11.2%,这种“学习时间增长”与“核心能力退步”的悖论,迫使我们重新思考:当教育被统计学方法全面渗透时,我们究竟应该统计什么?如何统计?
数据狂欢下的教育异化:三个典型案例
案例1:上海“学习数据造假”事件
聚焦绿色空气净化与绿色标识及绿色森林保护发展新趋势,应用场景不断拓展 2026年1月,上海市教委通报了一起令人震惊的案例:某知名在线教育平台为吸引用户续费,默许教师篡改学生学习数据,在抽查的2000份学习报告中,有37%的“进步曲线”存在人为修饰痕迹——系统会自动将学生连续三次错误率相同的题目标记为“逐步改进”,并通过算法生成看似合理的错误类型演变路径,更荒诞的是,该平台还推出“数据美化服务”,家长只需支付每月99元,即可获得一份“量身定制”的学习分析报告,其中包含“专注力提升28%”“知识掌握速度超过95%同龄人”等夸大性结论。
“这本质上是用统计学包装的教育焦虑贩卖。”复旦大学教育经济学教授陈立群指出,“当平台将‘学习数据’异化为商业营销工具,统计学的客观性就被彻底解构了。”该事件曝光后,上海市教委紧急叫停所有在线教育平台的数据可视化服务,并要求企业将数据采集范围严格限定在“教学必要环节”。
案例2:杭州“刷题量竞赛”引发的群体性焦虑
在杭州某重点初中,一个名为“学习数据排行榜”的民间系统在家长中悄然流行,该系统通过爬取多个在线教育平台的数据,生成包含“日均刷题量”“知识点覆盖度”“错题重做率”等12项指标的排名榜单,2026年春季学期,初三(2)班的张宇凡同学以“日均完成5.8套试卷”的成绩登顶榜首,但他的班主任发现,这个“学霸”在课堂上的表现却令人担忧:当被问到“如何用统计方法分析班级成绩分布”时,张宇凡支支吾吾答不上来,反而反复强调“我昨晚刷了3套物理卷”。
“这种数据竞赛正在摧毁教育的本质。”杭州师范大学教育技术系主任王琳表示,“我们追踪了200名参与排行榜的学生,发现其中68%出现不同程度的认知疲劳,具体表现为对开放性问题的回避和对标准答案的过度依赖。”更讽刺的是,当学校试图叫停这种非官方排名时,部分家长竟联合向教育局投诉,称“剥夺了孩子通过数据证明自己的机会”。
案例3:成都“智能错题本”的意外效果
与上述案例形成鲜明对比的是,成都市教育局2026年试点的一项改革带来了积极变化,该市要求所有在线教育平台必须开放错题数据接口,并由教育部门统一开发“智能错题分析系统”,与商业平台不同,这个系统不统计“刷题总量”或“正确率”,而是聚焦三个核心指标:错误类型分布(如概念混淆、计算失误、审题偏差)、知识模块关联性(如代数错误是否与几何知识掌握不足有关)、错误时间规律(如是否集中在晚间10点后)。
在成都七中实验学校的试点中,初三学生陈雨桐的数学成绩从班级中游跃升至前5%,她的母亲展示了一份系统生成的报告:“以前我只知道孩子数学不好,现在能清楚看到她的主要问题是‘函数图像变换’与‘几何证明’的思维转换障碍,系统还推荐了3个针对性的微课视频。”该校校长李建国透露,试点半年后,学生平均单日有效学习时间减少了1.2小时,但数学平均分提高了8.3分,“这证明精准的数据分析比盲目刷题更有效”。
统计学在教育中的正确打开方式:三个关键维度
维度1:从“结果数据”到“过程数据”的转向
传统在线教育平台的数据采集主要关注“完成了多少题”“得了多少分”等结果性指标,而2026年教育界达成的共识是:真正有价值的教育数据应该记录学习过程,以科大讯飞2026年推出的“智慧课堂系统”为例,该系统通过眼动追踪、答题节奏分析、草稿纸识别等技术,采集了12项过程性数据:包括“每道题的思考时间”“修改答案的次数”“辅助线绘制路径”等。 2026年绿色低碳与野生动物保护领域取得重要进展,行业关注度持续提升
在北京人大附中的实践显示,这些过程数据能揭示许多传统成绩单无法反映的信息,系统发现某学生在“立体几何”题目上平均思考时间长达4.2分钟,但修改答案的次数极少,进一步分析发现,他的空间想象能力其实很强,只是不擅长用二维图纸表达三维思维,针对这一特点,教师为他设计了“用黏土建模辅助解题”的个性化方案,三个月后,该学生的几何成绩提升了21分。
维度2:建立“教育数据伦理”框架
面对数据滥用的风险,2026年教育部发布了《在线教育数据管理规范(试行)》,首次明确了教育数据的采集边界、使用规范和保护机制,其中最引人注目的条款包括:
- 禁止采集与教学无关的学生生物特征数据(如面部表情、心率等)
- 要求平台对学习数据进行“脱敏处理”,禁止向第三方透露学生个体信息
- 规定“学习分析报告”必须包含“数据局限性说明”,避免过度解读
“数据不是教育问题的解药,反而可能成为毒药。”规范起草专家组成员、北京师范大学教授张志勇强调,“比如某个学生‘注意力持续时间短’的数据,如果被简单解读为‘多动症’,就可能造成误判,教育数据必须放在具体的情境中分析,并尊重教育规律。”
维度3:构建“人机协同”的分析模式
2026年植物保护与绿色消费圈及精准医疗热度持续攀升,相关技术取得新突破 在2026年的教育实践中,一个明显趋势是:统计学方法不再替代教师判断,而是成为辅助工具,上海闵行区开发的“教师数据驾驶舱”系统提供了典型范例:该系统将学生的学习数据转化为可视化仪表盘,但最终决策权始终掌握在教师手中。
当系统提示某学生“最近三次数学测验中‘概率统计’模块错误率上升”时,它会同时提供三种可能原因(概念理解不足、计算失误、审题偏差)及对应的教学资源包,但选择哪种干预方式由教师根据对学生的日常观察决定,闵行区教育学院院长陆杰表示:“我们培训教师不是教他们看数据,而是教他们如何结合数据与教育经验做出更科学的判断,毕竟,教育是人与人之间的互动,不是机器与数字的游戏。”
对教育改革的深层启示:数据时代的“教育回归”
启示1:重新定义“学习成效”的评价标准
当统计学方法深入教育领域,我们有机会打破“唯分数论”的单一评价体系,2026年,浙江省率先试点“教育数据账户”制度,为每个学生建立包含认知能力、情感态度、实践创新等多维度的数据档案,在杭州学军中学的实践中,这份档案不仅记录了学生的考试成绩,还跟踪了他们在“社区服务时长”“科研项目参与度”“跨学科问题解决能力”等方面的表现。
“我们正在开发一套‘动态能力图谱’。”该校校长邱月灵介绍,“比如一个学生可能数学成绩一般,但他在编程项目中展现出的逻辑思维能力很强,这种‘非标准优势’过去容易被忽视,现在通过数据挖掘就能被发现。”这种评价体系的转变,正在倒逼教学内容和方式的改革——学校开始增设“数据思维”“批判性写作”等跨学科课程,减少重复性刷题训练。 健康中国与绿色消费热度持续上升,相关领域迎来新发展
启示2:推动教育资源的精准配置
热度持续蔓延绿色服务网与兴趣班及中学教育热度持续上升,相关产业迎来新机遇 统计学方法的另一个重要应用是优化教育资源配置,2026年,教育部“国家教育大数据平台”正式上线,该平台整合了全国31个省市的在线教育数据,能实时分析不同地区、不同学段的教育需求,通过分析西部某县中学生