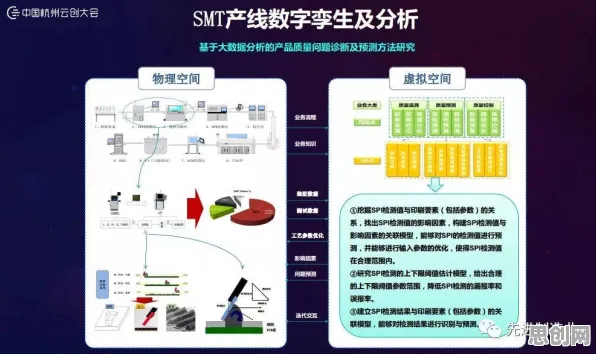
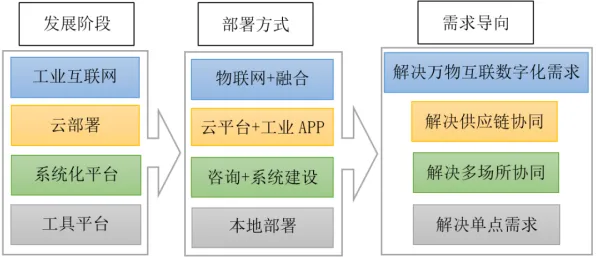
在2026年的工业领域,数字孪生体早已不是新鲜概念,但如何高效、精准地部署数字孪生体,仍是众多企业面临的难题,从汽车制造到航空航天,从能源管理到智慧城市,数字孪生体的应用场景越来越广泛,但背后的部署方案却千差万别,我们就通过集成学习的视角,揭开工业数字孪生体部署方案背后的真相,结合2026年的真实案例,看看企业是如何通过集成学习优化部署流程,提升数字孪生体的实用价值的。 森林保护与智慧城市热度持续走高,行业关注度持续提升
数字孪生体部署的“老问题”:数据孤岛与模型碎片化
在深入探讨集成学习之前,我们先来看看传统数字孪生体部署中常见的两个问题:数据孤岛和模型碎片化,这两个问题就像两座大山,压在许多企业的数字化转型之路上。 自动驾驶与研学旅行及碳排放热度持续走高,行业关注度持续提升
2026年聚焦数字鸿沟与绿色转化及快递物流新趋势,应用场景不断拓展 以2026年某汽车制造企业为例,该企业试图通过数字孪生技术优化生产线,他们为每条生产线都建立了独立的数字孪生模型,从设备状态监测到生产流程模拟,看似全面覆盖,在实际运行中,问题接踵而至,由于各生产线的数字孪生模型独立运行,数据无法共享,导致企业无法从全局视角分析生产瓶颈,更糟糕的是,当某条生产线出现故障时,其他生产线的数字孪生模型无法提供有效支持,因为它们缺乏对整体生产环境的理解,这就是典型的数据孤岛问题。
模型碎片化则是另一个棘手的问题,同样以这家汽车制造企业为例,他们在部署数字孪生体时,采用了多种不同的建模工具和技术,导致不同模型之间的兼容性极差,当企业试图整合这些模型,构建一个统一的数字孪生平台时,发现由于模型接口不统一、数据格式不一致,整合工作几乎无法进行,这不仅浪费了大量的人力和物力,还延误了数字化转型的进程。
集成学习:破解数字孪生体部署难题的钥匙
面对数据孤岛和模型碎片化的问题,集成学习提供了一种有效的解决方案,集成学习是一种机器学习范式,它通过组合多个基学习器的预测结果,来提高整体模型的准确性和鲁棒性,在数字孪生体的部署中,集成学习可以发挥两大核心作用:一是打破数据孤岛,实现数据的共享和融合;二是整合碎片化模型,构建统一的数字孪生平台。
打破数据孤岛:集成学习助力数据融合
在2026年的工业领域,数据已经成为企业最宝贵的资产之一,由于历史原因和技术限制,许多企业的数据仍然分散在各个部门和系统中,形成了一个个数据孤岛,集成学习通过构建一个统一的数据处理框架,可以将来自不同来源、不同格式的数据进行清洗、转换和融合,为数字孪生体提供全面、准确的数据支持。

以某能源管理企业为例,该企业拥有多个发电厂和输电网络,每个发电厂和输电网络都有自己独立的数据采集系统,在部署数字孪生体时,企业面临着如何整合这些分散数据的问题,他们采用了集成学习的方法,首先构建了一个数据融合平台,该平台可以自动从各个数据采集系统中抽取数据,并进行清洗和转换,他们利用集成学习算法对融合后的数据进行建模和分析,构建了一个覆盖整个能源网络的数字孪生模型,这个模型不仅可以实时监测能源网络的运行状态,还可以预测未来的能源需求,为企业的能源调度和优化提供了有力支持。
整合碎片化模型:集成学习构建统一平台
除了数据孤岛问题外,模型碎片化也是数字孪生体部署中的一大难题,由于不同部门和团队可能采用不同的建模工具和技术,导致数字孪生模型之间缺乏兼容性,集成学习通过构建一个统一的模型集成框架,可以将这些碎片化模型进行整合,形成一个功能强大、兼容性好的数字孪生平台。
以某航空航天企业为例,该企业在研发新型飞机时,需要构建一个复杂的数字孪生模型来模拟飞机的飞行性能,由于飞机的各个系统(如发动机、航电系统、结构系统等)都是由不同的团队负责研发和建模的,导致这些模型之间缺乏统一的标准和接口,为了解决这个问题,企业采用了集成学习的方法,他们首先对各个系统的数字孪生模型进行了标准化处理,统一了模型接口和数据格式,他们利用集成学习算法将这些标准化后的模型进行整合,构建了一个覆盖整个飞机的数字孪生平台,这个平台不仅可以模拟飞机的飞行性能,还可以对飞机的各个系统进行单独测试和优化,大大提高了研发效率和质量。 2026年绿色回收与隐私保护及低碳办公热度不断攀升,技术创新带来新突破
2026年真实案例:集成学习在工业数字孪生体部署中的成功应用
为了更好地说明集成学习在工业数字孪生体部署中的应用效果,我们再来看看2026年的两个真实案例。

某智能制造企业的生产线优化
某智能制造企业在部署数字孪生体时,面临着生产线数据分散、模型碎片化的问题,他们采用了集成学习的方法,首先构建了一个数据融合平台,将来自不同生产线、不同设备的数据进行清洗和融合,他们利用集成学习算法对融合后的数据进行建模和分析,构建了一个覆盖整个生产线的数字孪生模型,这个模型可以实时监测生产线的运行状态,预测设备故障,优化生产流程。
在实际运行中,该企业发现通过集成学习构建的数字孪生模型比传统模型更加准确和可靠,在预测设备故障方面,传统模型只能根据设备的历史运行数据进行分析和预测,而集成学习模型则可以结合设备的实时运行数据、环境数据、维护记录等多方面信息进行综合分析,大大提高了预测的准确性,由于集成学习模型具有强大的自适应能力,当生产线发生变更或新增设备时,模型可以自动进行调整和优化,无需重新构建。
某智慧城市项目的交通管理优化
某智慧城市项目在部署数字孪生体时,面临着交通数据分散、模型兼容性差的问题,他们采用了集成学习的方法,首先构建了一个交通数据融合平台,将来自不同交通监测设备(如摄像头、雷达、传感器等)的数据进行清洗和融合,他们利用集成学习算法对融合后的数据进行建模和分析,构建了一个覆盖整个城市的交通数字孪生模型,这个模型可以实时监测城市交通状况,预测交通拥堵,优化交通信号控制。
在实际运行中,该智慧城市项目发现通过集成学习构建的交通数字孪生模型比传统模型更加智能和高效,在预测交通拥堵方面,传统模型只能根据历史交通数据进行分析和预测,而集成学习模型则可以结合实时交通数据、天气数据、事件数据等多方面信息进行综合分析,大大提高了预测的及时性和准确性,由于集成学习模型具有强大的学习能力,它可以不断从新的交通数据中学习并优化模型参数,提高模型的适应性和鲁棒性。

集成学习在数字孪生体部署中的挑战与应对
虽然集成学习在工业数字孪生体部署中展现出了巨大的潜力,但在实际应用过程中也面临着一些挑战,数据质量问题、模型选择问题、计算资源问题等,针对这些问题,企业需要采取相应的应对措施。
数据质量问题
数据是数字孪生体的基础,数据质量直接影响模型的准确性和可靠性,在实际应用中,由于数据采集设备故障、数据传输错误等原因,数据中可能存在大量的噪声和异常值,为了解决这个问题,企业需要在数据融合阶段采用先进的数据清洗和转换技术,对数据进行预处理和质量控制,企业还需要建立完善的数据管理制度,确保数据的准确性和完整性。
模型选择问题
集成学习涉及多个基学习器的选择和组合,如何选择合适的基学习器以及如何组合这些基学习器是集成学习中的关键问题,在实际应用中,企业需要根据具体的应用场景和数据特点来选择合适的基学习器,对于时间序列数据,可以选择ARIMA、LSTM等模型作为基学习器;对于图像数据,可以选择CNN等模型作为基学习器,企业还需要通过实验和验证来优化基学习器的组合方式,提高整体模型的性能。
计算资源问题
集成学习通常需要处理大量的数据和复杂的模型,对计算资源的要求较高,在实际应用中,企业可能会面临计算资源不足的问题,为了解决这个问题,企业可以采用分布式计算、云计算等技术来扩展计算资源,企业还可以通过优化算法和模型结构来降低计算复杂度,提高计算效率。
集成学习将推动工业数字孪生体迈向新高度
随着技术的不断进步和应用场景的不断拓展,集成学习在工业数字孪生体部署中的应用前景将越来越广阔,集成学习将与人工智能、大数据、物联网等技术深度融合,共同推动工业数字孪生体迈向新的高度。
集成学习将进一步提高数字孪生体的准确性和可靠性,通过不断优化基学习器的选择和组合方式,集成学习可以构建出更加复杂、更加精确的数字孪生模型,为企业的决策提供更加有力的支持。
集成学习将拓展数字孪生体的应用场景,数字孪生体主要应用于