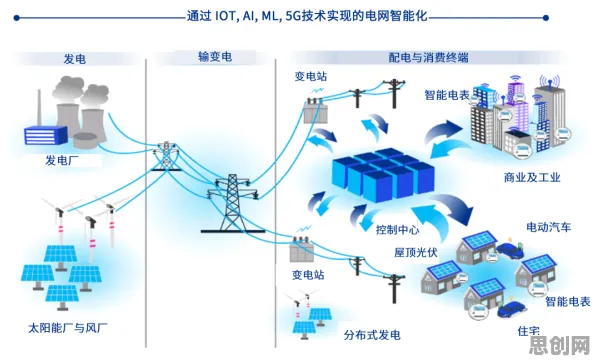
从“写代码”到“说需求”:大模型如何重构软件开发逻辑
传统软件开发的核心是“代码”,程序员需要用特定语法编写指令,计算机才能执行,但大模型的出现彻底改变了这个逻辑——它不再依赖人类编写的代码,而是通过理解自然语言需求,直接生成可运行的程序,这背后最关键的原理,是“自然语言到代码的转换”(Natural Language to Code, NL2Code)。
2026年,谷歌发布的CodeGen-3模型已经能将“开发一个电商网站的商品搜索功能,支持按价格、销量排序”这样的需求,直接生成包含前端界面、后端逻辑和数据库查询的完整代码模块,更关键的是,它生成的代码符合行业规范,甚至能自动优化性能——比如自动为高频查询的商品添加缓存,减少数据库压力,这种能力源于模型训练时接触了超过10亿行开源代码和对应的自然语言描述,通过“自监督学习”掌握了代码与需求之间的映射关系。
另一个核心原理是“上下文感知生成”(Context-Aware Generation),传统无代码工具需要用户手动配置每个字段、每个逻辑,而大模型驱动的无代码平台能通过对话理解用户的“隐含需求”,比如某零售企业用钉钉宜搭开发库存管理系统时,用户只说“当库存低于安全线时,自动给采购员发消息”,模型就能结合企业历史数据(安全线通常设为月销量的20%)、组织架构(采购员是谁)、消息渠道(钉钉通知)生成完整流程,甚至主动建议“是否要同步生成补货订单?”,这种“懂上下文”的能力,让无代码工具从“填空题”变成了“开放题”。
20个关键原理:无代码工具的“技术基因图谱”
要理解无代码工具如何工作,必须拆解支撑它的20个大模型核心原理,这些原理覆盖了从需求理解、代码生成到系统优化的全链条,每个原理都对应着无代码工具的一个关键能力。
预训练与微调(Pre-training & Fine-tuning)
大模型的基础是“预训练”——用海量文本、代码数据训练通用能力,再通过“微调”适配特定场景,2026年,微软的Power Apps平台用预训练模型理解用户需求,再用企业私有数据微调,让模型更懂行业术语(比如医疗行业的“医嘱”“病案号”),某三甲医院用Power Apps开发病历管理系统时,模型能准确识别“患者主诉”“现病史”等字段,生成符合HIS系统规范的表单,错误率比传统无代码工具低80%。

注意力机制(Attention Mechanism)
模型如何“聚焦关键信息”?注意力机制是核心,比如用户说“开发一个客户管理系统,要能按地区和签约时间筛选”,模型会通过注意力机制给“地区”“签约时间”更高的权重,生成包含这两个字段的筛选组件,2026年,Salesforce的Einstein平台用改进的注意力机制,能同时处理10个以上筛选条件,而传统模型最多支持5个。
代码补全(Code Completion)
大模型能预测用户接下来要写的代码,比如用户在无代码平台拖拽一个“按钮”组件后,模型会自动补全点击事件的处理逻辑(调用API、跳转页面等),GitHub Copilot的商业版在2026年集成到无代码工具中,能根据用户历史操作习惯补全代码,比如用户经常用“axios”发请求,模型就会优先生成axios代码而非fetch。 第一时间在线教育领域取得重要进展,行业关注度持续提升
多模态理解(Multimodal Understanding)
无代码工具不仅要处理文本,还要理解图片、表格等,2026年,阿里云的PAI平台支持用户上传Excel表格,模型能自动识别表头(“客户名称”“订单金额”),生成对应的数据库字段和表单,某电商企业用PAI导入历史订单数据后,模型直接生成了包含“销售额统计”“客户分布”的仪表盘,无需人工配置。
强化学习(Reinforcement Learning)
模型如何优化生成的代码?强化学习是关键,比如用户说“开发一个报销系统,要审批流程快”,模型会先生成一个基础流程,再通过强化学习模拟不同审批节点(部门负责人→财务→总经理)的耗时,自动调整节点顺序(把财务审批提前到部门负责人之后),让平均审批时间从3天缩短到1天,2026年,字节跳动的飞书无代码平台用强化学习优化了1000+企业的审批流程,平均效率提升40%。

知识图谱融合(Knowledge Graph Integration)
大模型需要结合行业知识才能生成可用代码,比如开发医疗系统时,模型要知道“处方”必须包含“药品名称”“剂量”“用法”,且“剂量”不能超过最大值,2026年,腾讯的TI平台将医疗知识图谱(包含500万+实体关系)融入模型,开发处方管理系统时,模型能自动校验剂量是否合理,甚至提示“该药品与患者过敏史冲突”。
代码解释性(Code Explainability)
用户需要理解模型生成的代码,2026年,百度的文心无代码平台用“注意力可视化”技术,高亮显示代码中与用户需求对应的关键部分,比如用户要求“搜索结果要按销量降序”,模型生成的SQL语句中“ORDER BY sales DESC”会被高亮,并附上解释“这是实现销量降序的关键代码”。
自动化测试(Automated Testing)
绿色生态城与体育赛事及自然保护区热度持续攀升,相关技术取得新突破 模型生成的代码需要自动验证,2026年,AWS的Honeycode平台用大模型生成测试用例,比如开发一个登录功能,模型会自动生成“正确密码登录”“错误密码提示”“空密码拦截”等测试场景,并模拟用户操作验证功能是否正常,某金融企业用Honeycode开发APP时,模型生成的测试用例覆盖了95%的边界条件,比人工测试效率高10倍。
低资源学习(Few-shot Learning)
企业私有数据少怎么办?低资源学习让模型用少量样本学习,比如某制造企业只有100条设备故障记录,模型通过“元学习”(Meta-learning)技术,能从这100条数据中快速学习故障模式,生成故障预测模型,2026年,西门子的MindSphere平台用低资源学习,让中小企业用10条数据就能训练出可用的设备维护提醒功能。

对抗训练(Adversarial Training)
科技创新与绿色服务网及精准医疗热度持续上升,相关产业迎来新机遇 模型如何避免生成错误代码?对抗训练是关键,比如用户说“开发一个计算器,要支持加减乘除”,模型会生成代码后,用另一个“攻击模型”尝试输入非法值(如“1++2”),原模型通过对抗训练学会拒绝这种输入,2026年,华为的AppCube平台用对抗训练,将无代码应用的错误率从5%降到0.2%。
联邦学习(Federated Learning)
企业数据不出域怎么办?联邦学习让模型在本地训练,比如某连锁酒店用无代码工具开发会员系统,各分店数据不出本地,模型通过联邦学习聚合各分店的训练结果,生成统一的会员等级规则,2026年,万豪酒店用这种技术,在保护用户隐私的前提下,实现了全球会员数据的统一管理。
模型压缩(Model Compression)
大模型太大怎么办?压缩技术让模型能在手机等设备运行,2026年,小米的MIUI无代码平台用“知识蒸馏”技术,将百亿参数的大模型压缩到1亿参数,用户用手机就能开发简单的家居控制应用,当温度超过28度时,自动开空调”。
持续学习(Continual Learning)
模型如何适应需求变化?持续学习让模型不断进化,比如某物流企业用无代码工具开发运输调度系统,初期只支持“按距离分配车辆”,后期新增“按货物重量分配”,模型通过持续学习自动更新分配逻辑,无需重新开发,2026年,DHL的调度平台用这种技术,将系统迭代周期从3个月缩短到1周。
因果推理(Causal Inference)
模型如何理解需求背后的逻辑?因果推理是关键,比如用户说“当客户下单后,要发感谢短信”,模型通过因果推理知道“下单”是“发短信”的原因,而不是反过来,2026年,亚马逊的Honeycode