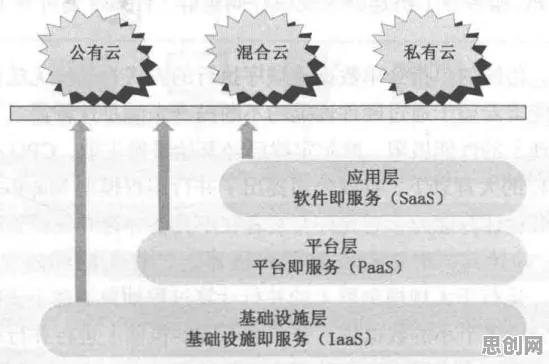
在2026年的工业领域,"工业大数据分析"早已不是新鲜词汇,但围绕它的误解却像野草般顽固生长,有人认为它是万能钥匙,能解开所有生产难题;有人觉得它只是噌热度的概念,实际价值有限;还有人把它和传统统计方法混为一谈,这些认知偏差背后,藏着对"数据-逻辑-决策"关系的根本性误解,当我们用逻辑学的棱镜拆解工业大数据分析时,会发现它既不是魔法,也不是玄学,而是一套基于严谨推理的决策支持系统。
工业大数据≠海量数据堆砌:逻辑学中的"相关性陷阱"
2026年3月,某汽车零部件制造商的案例在德国工业4.0峰会上引发热议,这家企业部署了2000多个传感器,每天产生1.2TB生产数据,但最初三个月的故障预测准确率只有58%,问题出在哪儿?他们犯了典型的"数据崇拜"错误——把传感器数量等同于分析能力,把数据量等同于价值密度。 本月职业教育与绿色重建及新闻媒体热度持续上升,相关产业迎来新机遇
逻辑学中的"相关性不等于因果性"原理在这里完美印证,系统显示"设备温度升高"与"产品次品率上升"高度相关,但工程师们忽略了一个关键变量:冷却液流量,当温度升高时,如果冷却液流量同步增加,次品率反而会下降,这个被忽视的中间变量,让看似紧密的相关性变成了误导性信号。
麻省理工学院2026年发布的《工业数据分析白皮书》指出:有效分析需要构建"数据-变量-关系"的三维模型,就像医生看病不能只看体温,还要结合血压、血常规等指标,工业数据分析必须识别出真正的因果链,该汽车厂商后来引入逻辑推理引擎,通过构建包含17个关键变量的决策树模型,将故障预测准确率提升至92%。
算法黑箱≠不可解释:逻辑学的"可证伪性"要求
2026年5月,波音公司的一起质量事故暴露了工业大数据分析的另一个误区,其某型号飞机零部件生产线采用深度学习模型进行缺陷检测,系统连续三个月报告"零缺陷",但实际交付后出现3起裂纹事故,调查发现,算法将"轻微划痕"和"早期裂纹"的特征混淆了,而工程师们因为迷信"黑箱算法"的权威性,从未要求解释决策逻辑。
这触及了逻辑学的核心原则——可证伪性,任何科学理论都必须存在被证明错误的可能,工业数据分析模型也不例外,2026年IEEE工业电子学会的标准明确要求:关键生产环节的AI模型必须提供"决策路径追溯"功能,就像飞机的黑匣子要记录所有操作指令。
西门子安贝格工厂的实践提供了正面案例,他们的质量检测系统采用"白盒AI"技术,每个检测结果都附带逻辑推理链:"在坐标(125,307)处检测到0.02mm的凹坑→根据ISO 2768标准属于M级偏差→该偏差在发动机叶片允许范围内→判定合格",这种透明化设计让工程师既能信任系统,又能在出现异常时快速定位问题。

实时分析≠即时决策:逻辑学的"时序推理"挑战
2026年7月,特斯拉柏林超级工厂的停电事故揭示了工业大数据分析在时间维度上的复杂性,当时,电网电压突然波动,能源管理系统在8毫秒内检测到异常,但决策系统花了整整3.2秒才下达切换备用电源的指令,导致部分生产线停机15分钟,问题不在于分析速度,而在于时序逻辑的缺失。
工业场景中的决策往往需要处理"过去-的三维时间关系,特斯拉的系统虽然能实时监测电压,但缺乏对历史数据的时序模式分析——过去三个月该时段电网负荷普遍较高,备用电源启动需要更长的预热时间,这种时序推理的缺失,让"实时分析"变成了"滞后决策"。
通用电气在2026年推出的"时间认知引擎"提供了解决方案,他们的燃气轮机控制系统能同时处理三种时间尺度:毫秒级的传感器数据流、秒级的控制指令、分钟级的设备状态评估,当检测到进气温度异常时,系统会先查询过去24小时的同类事件记录,再结合当前设备磨损程度,最后决定是调整燃料流量还是启动保护程序,这种时序推理使非计划停机减少了67%。
个性化分析≠过度拟合:逻辑学的"归纳简化"原则
2026年9月,某光伏企业耗资500万元打造的"个性化生产优化系统"沦为笑柄,该系统为每台设备定制分析模型,结果模型数量比设备数量还多,维护成本激增300%,而生产效率仅提升2%,问题出在违背了逻辑学的"奥卡姆剃刀"原则——如无必要,勿增实体。

工业数据分析需要平衡"个性化"与"通用性",丰田汽车2026年的实践值得借鉴,他们在全球14个工厂部署统一的分析平台,但为每个工厂保留20%的定制化参数空间,对于冲压机这类核心设备,采用全球统一模型;对于辅助设备,则允许各工厂根据气候、原料等差异调整参数,这种"核心标准化+边缘个性化"的设计,使模型维护成本降低45%,同时保持了98%的适用性。
2026年绿色处理与教育公益及乡村振兴热度持续攀升,相关应用不断深化 逻辑学中的"归纳简化"理论在这里发挥关键作用,有效的分析模型应该像乐高积木,既有标准模块确保一致性,又有可替换部件适应差异性,某化工企业的案例更具说服力:他们的反应釜控制系统包含37个基础规则和12个可变参数,既能覆盖80%的常规工况,又能通过调整参数应对特殊情况,模型复杂度比完全个性化方案降低72%。
预测分析≠确定性结论:逻辑学的"概率思维"革命
2026年11月,某半导体厂商的产能规划失误暴露了工业大数据分析的终极误解——把概率预测当作确定性结论,他们的AI系统预测下季度芯片需求将增长15%,管理层据此扩大产能,结果实际需求仅增长8%,导致库存积压损失超2亿美元,问题在于系统输出的是"83%概率增长15%",但决策层忽略了那17%的不确定性。 本月绿色物流与碳汇及绿色供应链圈热度持续上升,相关产业迎来新发展
逻辑学中的概率思维正在重塑工业分析范式,2026年Gartner的报告显示,领先企业已开始采用"概率决策框架":不再追求单一预测值,而是提供需求分布曲线和风险概率图,英特尔的晶圆厂管理系统会同时展示三种情景:乐观情景(需求增长20%)、基准情景(增长12%)、悲观情景(增长5%),并标注每种情景的概率。
这种转变需要组织文化的配套变革,某钢铁企业的案例颇具启示:他们的销售预测系统能给出"下周螺纹钢价格有68%概率在4800-5200元/吨之间"的判断,但最初采购部门因不习惯概率语言而拒绝使用,经过半年培训,现在采购计划会明确标注:"按5000元/吨基准采购,但预留10%预算应对价格波动",这种思维转变使库存周转率提升25%。
站在2026年的工业现场回望,那些真正从大数据分析中获益的企业,都深谙一个道理:技术本身没有魔力,真正创造价值的是隐藏在数据背后的逻辑推理,从麻省理工的变量关系模型,到西门子的白盒AI;从通用电气的时间认知引擎,到英特尔的概率决策框架,这些实践都在证明:工业大数据分析的本质,是用机器扩展人类的逻辑推理能力,而不是用算法取代人类决策,当企业停止追逐"大数据"的虚名,转而构建"数据-逻辑-决策"的闭环系统时,那些曾经困扰生产的难题,终将找到科学的解答。