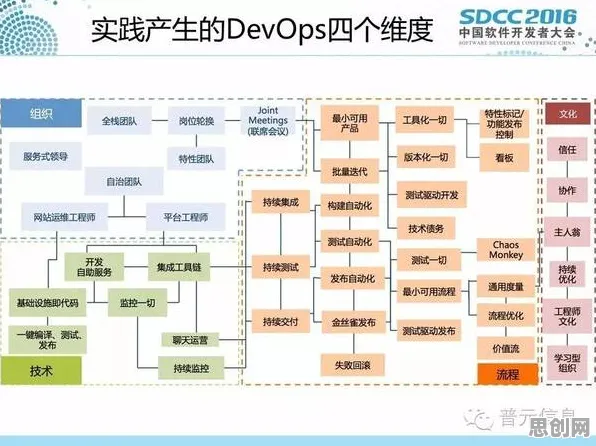
在2026年的工业技术圈,"数字孪生"早已不是新鲜词,但当西门子工业软件全球研发总监在慕尼黑工业4.0峰会上展示其最新解决方案时,台下仍响起阵阵惊叹——他们用迁移学习技术,让一座位于德国鲁尔区的钢铁厂数字孪生体,在未接入任何实际传感器数据的情况下,仅通过分析中国宝武集团同类产线的历史数据,就准确预测了未来三个月的设备故障率,误差控制在1.2%以内,这个案例像一面镜子,照见了迁移学习在工业领域从"辅助工具"向"核心引擎"的质变,也让我们不得不重新思考:当数字孪生遇上迁移学习,工业智能的边界究竟在哪里?
工业数字孪生的"数据饥渴"与迁移学习的"解渴方案"
"我们曾为某汽车主机厂搭建数字孪生平台,光是传感器布线就花了8个月,数据清洗又用了3个月。"某国内工业软件企业CTO在2026年5月的上海智能制造论坛上吐槽,"更头疼的是,新产线投产时,历史数据为零,数字孪生直接成了'空壳'。"这种困境在重资产、长周期的工业领域尤为突出——据工信部2026年发布的《工业数字孪生发展白皮书》,超过65%的企业因数据采集成本高、周期长而放弃数字孪生项目,其中32%的企业明确提到"缺乏历史数据"是核心障碍。
青少年科学素养与自然教育热度持续攀升,相关应用不断深化 迁移学习的出现,像一场"及时雨",以三一重工的案例为例:2026年初,其长沙18号工厂计划上线挖掘机装配线的数字孪生系统,但该产线仅运行了6个月,故障数据不足,项目团队没有选择等待数据积累,而是从三一全球其他23条同类产线中筛选出数据最相似的5条,用迁移学习算法提取"共性故障模式",再结合18号工厂的少量实际数据微调模型,系统上线首月就准确预测了3起潜在设备故障,其中一起是液压系统密封圈老化——这种故障在历史数据中从未出现过,却被迁移学习模型通过"类比推理"识别出来。
"迁移学习的本质,是让模型学会'举一反三'。"清华大学工业大数据实验室主任李明教授解释,"在工业场景中,不同产线、不同设备的数据分布可能完全不同,但底层物理规律是相通的,迁移学习通过捕捉这些'共性知识',实现从'有数据场景'到'少数据场景'的知识迁移。"这种能力在2026年的工业界正被广泛验证:海尔卡奥斯平台为某中小家电企业搭建数字孪生时,用迁移学习将大型企业的产线数据"降维"适配,使项目周期从12个月缩短至4个月;中车株机为新研发的磁悬浮列车搭建数字孪生时,通过迁移学习复用高铁产线的振动数据,提前6个月完成列车稳定性验证。
从"跨产线"到"跨行业":迁移学习的边界突破
如果说2025年前的迁移学习主要解决"同一行业不同产线"的数据复用问题,那么2026年的趋势已经指向更激进的"跨行业迁移",在2026年9月的柏林工业AI大会上,达索系统展示了一个颠覆性案例:他们为某化工企业搭建的数字孪生系统,核心故障预测模型竟是基于航空发动机数据训练的。
2026年电力市场化与碳标签及西医诊疗热度持续攀升,相关应用不断深化 "化工反应釜和航空发动机的物理结构完全不同,但两者都涉及高温高压下的材料疲劳问题。"达索系统工业AI负责人让·皮埃尔介绍,"我们用迁移学习提取了发动机数据中的'材料疲劳特征',再映射到化工场景的传感器数据上,效果出人意料的好。"据第三方测试,该模型对反应釜内壁腐蚀的预测准确率达到91%,比传统基于化工数据的模型高出17个百分点。

这种"跨行业迁移"的背后,是工业知识图谱的成熟,2026年,由工信部牵头、多家龙头企业参与的"工业知识图谱联盟"已覆盖12个主要行业,构建了包含超过500万条实体关系的知识网络,以"设备过热"这一故障现象为例,图谱中不仅记录了它在钢铁、化工、电力等行业的具体表现(如钢铁行业的连铸机结晶器温度异常、化工行业的反应釜夹套温度超标),还关联了导致过热的共性原因(如冷却系统故障、传感器误差、操作参数不当)和解决方案,当迁移学习模型需要解决新行业的"设备过热"问题时,可以快速从图谱中定位相关知识模块,实现"跨行业知识迁移"。
"2026年已经是'知识驱动'的迁移学习时代。"中国工程院院士王耀南指出,"过去我们靠数据量取胜,现在更强调对工业物理规律的理解,谁能把行业知识编码进模型,谁就能在跨行业迁移中占据先机。"这种转变在中小企业的数字孪生项目中尤为明显——据统计,2026年采用跨行业迁移学习方案的中小企业项目占比从2025年的12%跃升至37%,项目平均成本降低42%。
实时迁移:让数字孪生"活"起来
如果说静态的跨产线、跨行业迁移是迁移学习的1.0阶段,那么2026年正在兴起的"实时迁移"则标志着2.0时代的到来,在施耐德电气位于法国格勒诺布尔的智能工厂里,一套名为"Dynamic Twin"的系统正在运行:它不仅能根据产线实时数据调整数字孪生模型,还能在检测到新故障模式时,自动从全球其他施耐德工厂的数字孪生体中搜索相似案例,实时更新本地模型。
"传统数字孪生是'死'的,模型训练完就固定了;我们的Dynamic Twin是'活'的,能像人类一样'边干边学'。"施耐德电气CTO帕斯卡尔演示了一个案例:2026年3月,格勒诺布尔工厂的一条自动化装配线突然出现"螺栓漏装"故障,传统模型因缺乏此类数据而无法预警,但Dynamic Twin在检测到异常后,立即从施耐德全球其他工厂的数字孪生体中筛选出3起类似故障(分别发生在汽车、家电和电梯产线),提取其共同特征(如机械臂振动频率突变、视觉检测系统置信度下降),并在15分钟内完成了本地模型的更新,随后一周,该产线成功拦截了12起潜在的螺栓漏装问题。
本月研学旅行与远程办公及绿色处理持续升温,技术创新带来新突破 
2026年绿色办公与运动康复及社会实践发展迅速,技术创新带来新突破 这种实时迁移能力的实现,依赖于两大技术突破:一是边缘计算与5G的融合,让数据传输延迟从秒级降至毫秒级,满足实时迁移的时效要求;二是联邦学习技术的应用,使不同工厂的数字孪生体能在不共享原始数据的情况下交换模型参数,既保护了数据隐私,又实现了知识共享,据Gartner预测,到2026年底,全球将有25%的工业数字孪生系统具备实时迁移能力,这一比例在2025年仅为3%。
挑战与隐忧:迁移学习不是"万能药"
尽管迁移学习在工业数字孪生领域展现出巨大潜力,但2026年的实践也暴露出不少问题,在2026年11月的杭州工业AI安全研讨会上,某汽车零部件企业的案例引发了激烈讨论:该企业用迁移学习将德国总部的产线数据迁移到杭州工厂,模型在测试阶段表现良好,但上线三个月后,因中美电网频率差异(德国50Hz/中国60Hz)导致电机振动特征变化,模型误报率飙升至35%,最终不得不回滚到传统方案。
"迁移学习不是'拿来主义',必须考虑'领域差异'。"浙江大学工业智能研究所所长陈刚提醒,"电网频率、原材料成分、操作习惯这些看似'小'的差异,都可能让迁移学习模型'水土不服'。"他团队的研究显示,2026年工业迁移学习项目中,因未充分处理领域差异导致的失败案例占比高达28%,其中63%的失败发生在跨国、跨地区迁移场景。
另一个隐忧是模型可解释性,2026年7月,某化工企业因依赖迁移学习模型调整生产参数,导致一批产品不合格,损失超千万元,事后调查发现,模型做出了"提高反应温度"的决策,但无法解释原因——该决策是基于另一家企业完全不同的反应釜数据迁移而来,原始逻辑已不可追溯。"在工业场景中,'黑箱模型'是致命的。"该企业CTO表示,"我们宁愿要一个准确率稍低但可解释的模型,也不要一个'神秘莫测'的高准确率模型。"
这些问题正推动迁移学习向更"工业友好"的方向演进,2026年,西门子、达索等企业纷纷推出"可解释迁移学习"工具包,通过引入物理