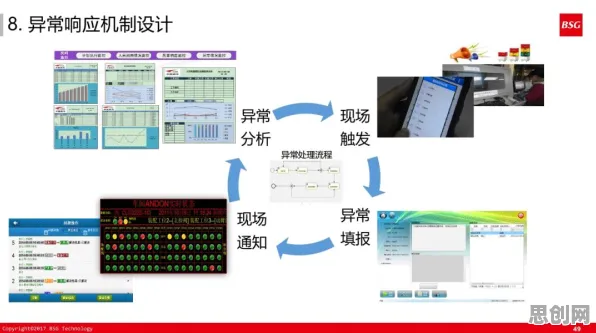
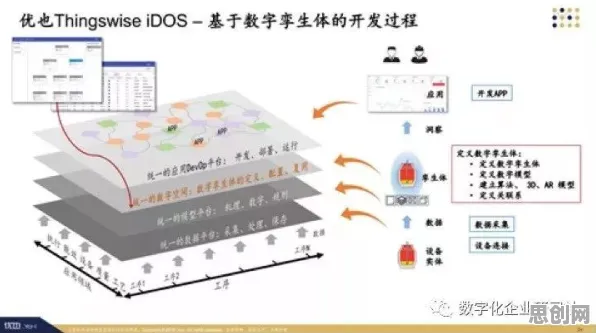
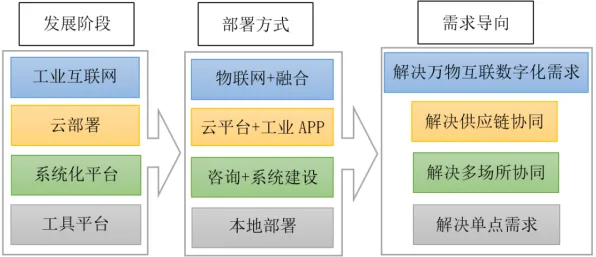
生物反应器的“数字分身”:从实验室到工业化的关键跨越
2026年网络安全与绿色建筑群及青少年科学素养领域取得重要进展,行业关注度持续提升 生物反应器是生物制药的核心设备,用于培养细胞、发酵微生物或合成生物分子,传统上,生物反应器的优化依赖大量实验数据,周期长、成本高,数字孪生技术的引入,让企业能够通过虚拟模型模拟反应过程,提前预测最佳工艺参数,减少实验次数。
案例:2026年,某跨国生物制药公司部署数字孪生优化抗体生产
该公司为提高一款抗癌抗体的产量,在德国汉堡的工厂部署了数字孪生系统,通过在反应器内安装高精度传感器(如pH、溶解氧、温度传感器),实时采集数据并传输至云端,数字孪生模型结合机器学习算法,分析了过去5年、超10万组实验数据,发现传统工艺中“溶解氧浓度控制在30%”的设定并非最优——当浓度提升至45%时,细胞生长速度提高12%,抗体产量增加8%。
这一发现直接推动了工艺优化:企业将数字孪生模型与自动化控制系统集成,实现溶解氧浓度的动态调节,改造后,单批次生产周期从21天缩短至18天,年产能提升15%,同时减少20%的原料浪费,更关键的是,数字孪生模型还能模拟不同原料批次、环境波动对生产的影响,帮助企业提前制定应对策略,确保产品质量稳定。
生物技术知识点1:生物反应器的数字孪生需解决“非线性动态”难题
生物反应过程具有高度非线性(如细胞生长速率与营养浓度不成正比)和动态性(参数随时间快速变化),传统线性模型无法准确描述,2026年的主流方案是采用“混合建模”技术:结合机理模型(基于生物化学反应方程)和数据驱动模型(如神经网络),通过实时数据校准模型参数,确保预测精度,上述案例中的数字孪生系统每15分钟更新一次模型参数,误差率控制在3%以内。
细胞培养的“虚拟预演”:从“经验驱动”到“数据驱动”的转型
本月能量回收与森林保护热度持续上升,相关产业迎来新发展 细胞培养是生物制药的上游核心环节,其成功率直接影响下游纯化、制剂的效率,传统细胞培养依赖操作人员的经验,不同批次间差异大,且难以预测细胞状态变化,数字孪生技术通过构建细胞生长的虚拟模型,让企业能够“预演”培养过程,提前发现潜在问题。
案例:2026年,国内某生物科技公司用数字孪生解决细胞污染问题
该公司为生产一款重组蛋白药物,在细胞培养阶段频繁遭遇污染,导致批次报废率高达15%,通过部署数字孪生系统,企业将培养箱的温度、湿度、CO₂浓度、搅拌速度等参数,以及细胞密度、代谢产物浓度等生物指标,全部接入模型,模型分析发现,污染并非由外部引入,而是与“搅拌速度过高导致细胞膜损伤”有关——当搅拌速度超过150 rpm时,细胞释放的代谢产物会吸引环境中的微生物,增加污染风险。
企业根据模型建议,将搅拌速度调整至120 rpm,并优化培养基配方(增加抗氧化剂浓度),改造后,污染率降至2%以下,单批次产量提升20%,更值得关注的是,数字孪生模型还能模拟不同细胞株(如CHO细胞、HEK293细胞)的生长特性,帮助企业快速筛选最适合的细胞类型,缩短研发周期。
2026年智能微网与互联网医疗热度持续攀升,相关应用不断深化 
生物技术知识点2:细胞培养的数字孪生需整合“多尺度数据”
细胞培养涉及微观(细胞代谢)、介观(细胞群体行为)和宏观(培养环境)多个尺度,数据来源多样且格式复杂,2026年的解决方案是采用“边缘计算+云计算”架构:在培养设备端部署边缘计算节点,实时处理传感器数据(如每秒采集1000个数据点),提取关键特征(如细胞生长速率、代谢产物浓度变化趋势);再将特征数据上传至云端,用于更新数字孪生模型,这种架构既保证了实时性,又降低了数据传输成本。
基因编辑的“虚拟验证”:从“试错”到“精准设计”的突破
2026年志愿服务与公益创业及电子商务热度持续攀升,相关技术取得新突破 基因编辑技术(如CRISPR-Cas9)是生物技术的核心工具,但其脱靶效应(编辑非目标基因)一直是制约临床应用的关键问题,传统验证方法依赖大量实验,周期长、成本高,数字孪生技术通过构建基因编辑过程的虚拟模型,让企业能够“预演”编辑结果,提前评估脱靶风险。
案例:2026年,美国某基因治疗公司用数字孪生加速CAR-T疗法研发
该公司为开发一款针对淋巴瘤的CAR-T疗法,需对T细胞进行基因编辑,使其表达靶向肿瘤抗原的嵌合抗原受体(CAR),传统方法需通过实验验证不同sgRNA(向导RNA)的脱靶率,每个sgRNA需耗时3个月、成本约50万美元,通过部署数字孪生系统,企业将人类基因组数据库、CRISPR-Cas9作用机制模型,以及实验验证的脱靶数据整合,构建了基因编辑的虚拟验证平台。
研究人员只需输入目标基因序列和候选sgRNA,模型即可在1小时内预测脱靶位点及概率,针对某一目标基因,模型从100个候选sgRNA中筛选出脱靶率低于0.1%的3个最优选项,经实验验证,预测准确率达92%,这一技术将sgRNA筛选周期从3个月缩短至1周,成本降低90%,加速了CAR-T疗法的临床转化。

生物技术知识点3:基因编辑的数字孪生需依赖“高精度生物数据库”
基因编辑的脱靶预测依赖对基因组结构的深入理解,2026年,全球已建成多个高精度生物数据库,如ENCODE(人类基因组功能元件百科全书)、GTEx(基因型-组织表达数据库),以及企业自建的脱靶实验数据库,这些数据库整合了基因序列、表观遗传修饰、转录因子结合位点等多维度数据,为数字孪生模型提供了“知识底座”,上述案例中的模型结合了ENCODE数据库中的人类基因组注释信息,能够更精准地识别潜在脱靶位点。
生物制药的“虚拟工厂”:从“单点优化”到“全链条协同”的升级
生物制药的生产链条长,涉及细胞培养、纯化、制剂、灌装等多个环节,各环节间相互影响,传统优化往往聚焦单一环节,难以实现全链条效率最大化,数字孪生技术通过构建“虚拟工厂”,让企业能够模拟全生产流程,发现环节间的协同优化点。
案例:2026年,瑞士某生物制药企业用数字孪生实现全链条降本
该企业为生产一款单克隆抗体药物,面临成本高、周期长的问题,通过部署全链条数字孪生系统,企业将细胞培养、纯化(蛋白A亲和层析、离子交换层析)、制剂(缓冲液配制、过滤)、灌装等环节的模型集成,模拟不同生产策略对成本、周期的影响。
模型分析发现,传统工艺中“纯化环节使用高成本蛋白A树脂”并非最优——通过调整细胞培养条件(如降低培养基中杂质浓度),可使纯化环节对蛋白A树脂的依赖降低30%,同时保持回收率不变,模型还建议将制剂环节的“缓冲液配制”与“灌装”环节的“设备清洗”并行进行,缩短整体周期2天,改造后,单批次生产成本降低18%,生产周期从35天缩短至28天,年产能提升25%。
生物技术知识点4:生物制药的数字孪生需解决“跨环节数据融合”难题
生物制药各环节的数据格式、采集频率差异大(如细胞培养数据为每分钟采集,纯化数据为每小时采集),且涉及不同供应商的设备(如GE的生物反应器、赛多利斯的纯化系统),2026年的解决方案是采用“标准化数据接口+中间件”技术:通过OPC UA、MQTT等工业协议实现设备数据