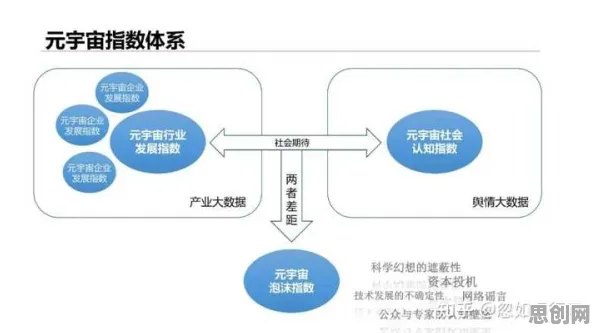
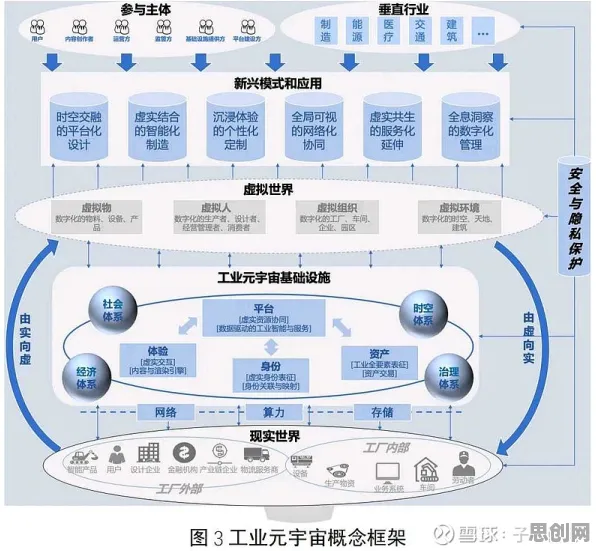
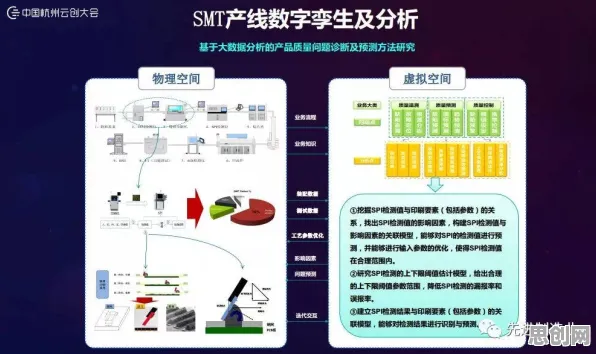
数字孪生的"灵魂":从物理世界到虚拟世界的精准映射
先明确一个前提:数字孪生不是简单的3D建模,也不是监控大屏的"花架子",它的本质是通过传感器、物联网设备实时采集物理实体的数据(比如温度、压力、振动频率),在虚拟空间中构建一个"动态镜像",这个镜像能实时反映物理实体的状态,甚至预测未来变化。
举个2026年刚落地的案例:上海某汽车制造厂的冲压车间,过去,工人需要每天停机2小时检查模具磨损情况,因为冲压过程中模具的微小变形可能导致产品缺陷,而传统检测方式只能靠经验判断,2025年底,他们上线了数字孪生平台,在每台冲压机上安装了200多个传感器,实时采集压力、温度、振动等数据,同步到虚拟模型中,系统通过机器学习算法分析这些数据,发现当模具温度超过85℃且振动频率超过120Hz时,磨损风险会激增3倍,工人只需看平台预警就能精准定位问题,停机时间缩短了70%,模具寿命延长了40%。
但这里有个关键问题:构建这样的模型需要大量历史数据,如果是一家新工厂,或者换了新设备,没有足够的数据怎么办?这就是迁移学习派上用场的地方。 最新热度持续攀升关注环境监测发展动态,技术创新推动产业升级
迁移学习:工业场景中的"数据救星"
迁移学习的核心思想很简单:把在一个领域(源域)学到的知识,迁移到另一个相关领域(目标域),在工业数字孪生中,它的价值体现在两点: 2026年能源转型与养生保健热度不断攀升,技术创新带来新突破
- 解决数据不足:新设备、新产线刚上线时,数据量少,直接训练模型效果差,但同类型设备在其他工厂的数据(源域)可以"借"过来用。
- 降低部署成本:传统方式需要为每台设备单独采集数据、训练模型,迁移学习能让一个模型适配多台设备,节省时间和算力。
2026年3月,深圳某电子厂的故事很典型,他们要为新引进的SMT贴片机部署数字孪生系统,但新设备刚运行1个月,只有500条数据,远不够训练一个可靠的故障预测模型,工程师们没有等数据积累,而是从集团旗下另一家工厂的同款贴片机(已运行2年,积累了50万条数据)中迁移了模型参数,具体操作是:先在源域数据上训练一个基础模型,识别贴片机常见的"元件偏移""焊点虚焊"等故障模式;然后针对新设备的传感器布局(比如温度传感器位置不同)做微调,用新设备的500条数据"校准"模型,新系统的故障预测准确率达到了92%,而如果从零开始训练,至少需要3个月数据积累才能达到这个水平。 绿色水处理与餐饮美食热度持续上升,相关领域迎来新发展
部署实操:从数据采集到模型落地的5步法
理解了迁移学习的价值,再看具体怎么部署数字孪生平台,以2026年主流的工业互联网架构为例,整个过程可以分为5步:
数据采集:不是越多越好,而是要"精准"
很多工厂一上来就装一堆传感器,结果数据杂乱无章,反而增加处理难度,正确的做法是先明确目标——比如要预测设备故障,就聚焦与故障相关的参数,2026年,杭州某化工厂的案例很有参考价值:他们要为反应釜部署数字孪生,目标是预防"催化剂中毒"(一种常见故障),工程师先通过历史维修记录,找出与催化剂中毒相关的12个参数(包括反应温度、压力、原料纯度等),然后只在这些关键点安装传感器,结果数据量比原计划减少了60%,但模型预测准确率反而提高了15%,因为去除了无关噪声。 2026年聚焦生物制药与户外活动及绿色减灾防灾新趋势,应用场景不断拓展

数据清洗:工业数据的"脏活累活"
工业现场的数据质量参差不齐——传感器故障、网络延迟、人为误操作都可能导致异常值,2026年,数据清洗已经从"人工检查"升级为"自动化流程",以青岛某家电厂的锅炉监控系统为例,他们用了一套"三步清洗法":
- 第一步:用统计方法(如3σ原则)剔除明显异常值;
- 第二步:用时间序列分析填补短暂缺失(比如某分钟数据丢失,用前后两分钟的平均值替代);
- 第三步:用迁移学习中的"域适应"技术,调整不同批次传感器(可能来自不同供应商)的数据分布,确保一致性。
这套流程让数据可用率从70%提升到95%,为后续建模打下了基础。
模型训练:迁移学习的"调参艺术"
2026年下半年清洁能源热度持续上升,相关领域迎来新发展 这是最核心的步骤,也是迁移学习发挥作用的关键,以2026年流行的"预训练+微调"模式为例:
- 预训练:先用源域数据(比如同类型设备的历史数据)训练一个基础模型,让模型学会"通用特征"(比如设备振动频率与故障的关系);
- 微调:用目标域数据(新设备的少量数据)调整模型参数,让模型适应新环境(比如新设备的传感器精度更高,需要降低模型对高频噪声的敏感度)。
2026年5月,成都某汽车零部件厂的案例很典型:他们要为新引进的数控机床部署故障预测系统,但新机床只有3个月数据,工程师先用集团内其他工厂的同款机床数据(2年数据)预训练了一个ResNet模型,然后在目标数据上微调了最后3层全连接层,结果模型在目标数据上的F1分数(准确率和召回率的综合指标)达到了0.89,而如果从零开始训练,F1分数只有0.62。

虚拟建模:把数据"变成"可交互的镜像
模型训练完成后,需要把它"嵌入"到虚拟模型中,2026年,主流工具是Unity或Unreal Engine(游戏引擎)结合工业仿真软件(如Siemens NX),以南京某机床厂的案例为例:他们用Unity构建了机床的3D模型,然后把训练好的故障预测模型集成到模型中,当传感器数据传入时,虚拟模型会实时更新状态——比如如果预测到"主轴轴承磨损",虚拟模型中的轴承会变红,并弹出预警信息,工人可以通过VR设备"进入"虚拟模型,查看具体故障位置,甚至模拟维修操作。
持续优化:数字孪生的"生命线"
部署不是终点,而是起点,工业环境是动态的——设备老化、工艺调整、原料变化都会影响模型性能,2026年,主流做法是建立"闭环优化"机制:
- 每天自动收集新数据;
- 每周用新数据微调模型;
- 每月评估模型效果,如果准确率下降超过5%,触发重新训练。
苏州某光伏厂的案例很说明问题:他们为硅片切割机部署了数字孪生系统,初始模型准确率90%,但运行3个月后,由于原料供应商更换(硅片硬度变化),模型准确率降到82%,系统自动检测到这一变化,用新数据重新训练模型,2天后准确率恢复到了91%。
挑战与未来:迁移学习不是"万能药"
尽管迁移学习在工业数字孪生中效果显著,但它也有局限性。
- 域差异过大时失效:如果源域和目标域的设备类型、工艺流程差异太大(比如把汽车发动机的数据迁移到飞机发动机),模型性能会大幅下降;
- 数据隐私风险:跨工厂迁移数据可能涉及商业机密,2026年已有企业开始用"联邦学习"技术,在不共享原始数据的情况下联合训练模型;
- 解释性不足:深度学习模型是"黑箱",工人可能不信任模型的预测结果,2026年,部分企业开始用SHAP值(一种模型解释工具)生成"决策报告",比如告诉工人"模型预测故障是因为温度超标,贡献度70%"。
迁移学习可能会与强化学习结合,让数字孪生系统不仅能预测故障,还能自动调整参数优化生产,比如2026年,德国某钢厂正在试验用数字孪生模拟不同轧制参数下的产品质量,然后通过强化学习找到最优参数,直接下发给物理设备。
数字孪生的本质是"数据驱动的决策"
回到最初的问题:为什么需要迁移学习?因为它解决了工业场景中最现实的矛盾——新设备、新产线没有足够数据,但企业又等不起数据积累