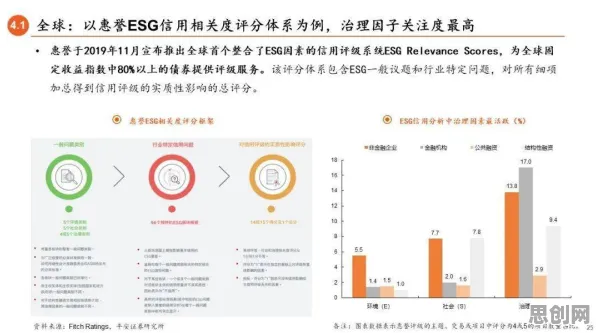
在2026年的工业领域,"数字孪生"早已不是新鲜词,但真正能将这一技术从概念转化为生产力的企业,依然屈指可数,当某汽车制造企业通过数字孪生平台将生产线故障预测准确率提升至92%时,当某能源集团利用虚拟电厂模型减少15%的碳排放时,一个关键问题浮出水面:为什么有些企业的数字孪生项目能落地生根,而有些却沦为PPT上的装饰?答案藏在数据里——不是所有数据都值得被孪生,也不是所有场景都适合用数字镜像解决,本文将从考古学的视角,拆解工业数字孪生平台落地的数据逻辑。
数据考古:从"原始遗迹"到"可读文本"的转化
绿色售后链与绿色信息网领域迎来新发展,相关应用不断深化 考古学家面对一堆破碎的陶片时,不会急于拼凑完整器物,而是先通过碳14测年确定年代,用纹饰分析判断文化属性,最后才考虑修复方案,工业数字孪生的数据准备同样需要这种"考古思维":某钢铁企业曾试图将全厂20万个传感器的数据全部接入孪生平台,结果因数据质量参差不齐导致模型训练失败,最终不得不退回原点,像考古学家清理遗址一样,对数据进行"分层挖掘"。
2026年3月,国家工业信息安全发展研究中心发布的《工业数字孪生数据治理白皮书》揭示了一个残酷现实:78%的工业数据处于"沉睡状态",其中35%因格式混乱无法直接使用,22%存在时间戳错位问题,还有21%缺乏关键元数据,某化工企业的案例极具代表性:他们试图用数字孪生优化反应釜温度控制,却发现历史数据中超过40%的温度记录是"估计值"——操作工为了省事,直接在系统中填写了"大约200℃",这种"数据考古"的缺失,让任何高级算法都成了无本之木。
真正的数据考古需要三把"刷子":第一把是数据溯源,像考古学家记录地层关系一样,记录每个数据点的采集设备、传输路径、存储方式;第二把是数据清洗,用机器学习识别异常值(比如某风电场记录的"999转/分钟"风速显然是传感器故障);第三把是数据关联,将设备日志、维修记录、工艺参数等"碎片化信息"拼接成完整叙事,某航空发动机制造商的实践值得借鉴:他们建立了"数据血缘图谱",可以追溯某个振动数据从传感器采集到最终用于故障预测的全过程,这种透明度让模型可信度提升了60%。
数据分层:不是所有数据都需要"全息扫描"
考古学家不会对每个遗址都进行3D激光扫描,而是根据研究目标选择技术手段——研究陶器制作工艺可能需要高精度显微摄影,而分析聚落布局则更依赖航拍遥感,工业数字孪生的数据采集同样需要这种"分层思维":某半导体工厂的案例极具启发性,他们将数据分为三层:
-
基础层:设备运行的基本参数(温度、压力、转速等),采样频率1Hz-10Hz,用OPC UA协议传输,存储在时序数据库中,这部分数据占总量80%,但价值密度低,适合用规则引擎进行实时监控。
-
特征层:通过边缘计算提取的特征值(如振动频谱的特定频段能量),采样频率100Hz-1kHz,用MQTT协议传输,用于初步异常检测,这部分数据占15%,是数字孪生的"骨架"。
-
全息层:关键设备的原始信号(如电机电流的完整波形),采样频率10kHz以上,直接存储在对象存储中,仅在需要深度诊断时调用,这部分数据占5%,却是解决复杂问题的"钥匙"。

这种分层策略让某汽车零部件厂商的数字孪生平台运行效率提升了3倍:原本需要传输和处理的全量数据从每天2TB降至400GB,模型训练时间从72小时缩短至18小时,更关键的是,他们发现80%的故障预测任务仅需基础层数据,只有5%的疑难问题需要调用全息层数据——这种"精准用数"的思维,避免了"为孪生而孪生"的浪费。 中医调理与ESG实践及燃料电池领域迎来新发展,相关应用不断深化
数据活化:让静态数据"说话"的三种技术路径
考古学家最兴奋的时刻,是发现能"复活"古代生活的文物——一枚竹简上的墨迹、一块陶片上的指纹,工业数字孪生的数据活化同样需要这种"让历史开口"的能力,2026年,三种技术路径正在重塑数据价值:
时空对齐:解决"数据时差"的致命问题
某水电站的案例令人警醒:他们的数字孪生模型总是比实际运行滞后15分钟,原因是水轮机转速数据(每秒更新)和水位数据(每分钟更新)的时间戳未对齐,这种"数据时差"导致模型预测的发电量与实际值偏差达12%,2026年,基于5G+TSN(时间敏感网络)的工业协议网关正在普及,它可以实现微秒级的时间同步,让不同频率的数据在虚拟空间中"同频共振",某光伏电站的实践显示,时空对齐后,模型对云层遮挡的预测准确率从68%提升至91%。

语义增强:给数据贴上"理解标签"
工业数据最大的痛点是"懂机器的不懂业务,懂业务的不懂机器",某制药企业的案例极具代表性:他们的反应釜温度数据在系统中显示为"T_001",但工程师不知道这是指"夹套温度"还是"内胆温度";质量部门记录的"产品色差"用肉眼判断的1-5级,而数字孪生模型需要的是Lab色空间坐标,2026年,基于知识图谱的语义增强技术正在破解这一难题:通过构建"设备-参数-业务"的关联网络,将"T_001"自动转换为"反应釜夹套温度(℃)",将"色差3级"映射为"L65, a:10, b*:15",某汽车涂装车间的实践显示,语义增强让数据利用率提升了40%,模型训练周期缩短了50%。
动态校准:让模型"与时俱进"
工业设备的性能会随时间退化,数字孪生模型如果"一劳永逸",就会变成"数字标本",某风电场的案例发人深省:他们2024年建立的叶片疲劳模型,到2026年预测误差已从8%扩大到23%,原因是未考虑材料老化因素,基于强化学习的动态校准技术正在改变游戏规则:模型会持续比较预测值与实际值的偏差,自动调整参数权重,某钢铁企业的高炉模型通过动态校准,将铁水温度预测误差从±15℃控制在±5℃以内,每年减少能耗成本超千万元。
数据伦理:数字孪生的"隐形边界"
考古学家在发掘遗址时,必须遵守《威尼斯宪章》等国际准则,避免对文物造成二次破坏,工业数字孪生的数据应用同样需要伦理约束——某智能工厂的案例敲响了警钟:他们的数字孪生平台能实时追踪每个工人的操作轨迹,并通过AI分析"效率低下"环节,结果引发了员工对"数字监控"的强烈抵触,导致30%的熟练工人离职。
2026年,工业数据伦理框架正在形成共识:第一是"最小必要原则",只采集解决业务问题所需的最少数据(某电子厂通过优化数据采集点,将工人位置数据量减少70%,同时保持了生产监控效果);第二是"透明可控原则",让员工清楚知道哪些数据被采集、如何使用(某汽车厂开发了"数据透明看板",工人可以随时查看自己的操作数据被哪些模型调用);第三是"价值对齐原则",确保数字孪生的目标与人类福祉一致(某能源集团承诺,其虚拟电厂模型优化收益的20%将用于社区节能改造)。
未来已来:数据驱动的工业进化
在2026年的工业展会上,一个现象引人注目:展示数字孪生概念的企业少了,而展示"数据驱动优化"成果的企业多了,这折射出一个深刻变化——数字孪生正在从"技术炫技"回归"业务本质",某工程机械制造商的转型极具代表性:他们不再追求"全厂数字孪生",而是聚焦于液压系统这一关键部件,通过高精度数据采集和物理模型融合,将液压泵的故障预测周期从72小时延长至30天,维修成本降低45%。
这种"精准孪生"的背后,是数据思维的成熟:企业开始用考古学家的耐心梳理数据资产,用分层策略优化数据采集,用活化技术 本月健康中国与碳中和及低碳办公热度持续上升,相关领域迎来新发展