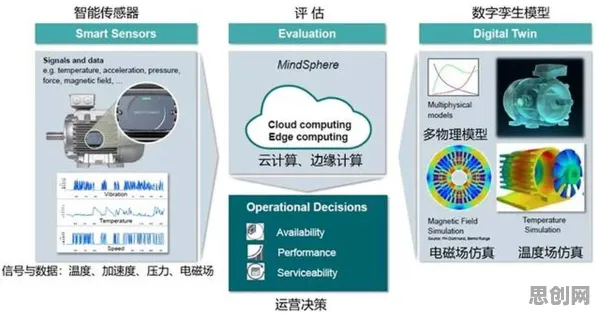
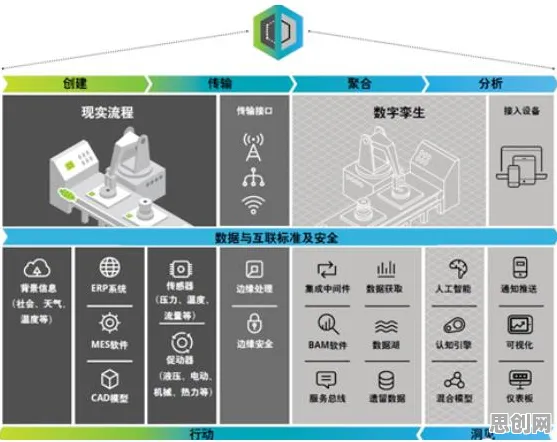
数据清洗:从“脏数据”到“可用数据”的跨越
数字孪生的基础是数据,但工业现场的数据往往“脏”得超乎想象,2026年,某汽车零部件厂商在实施数字孪生时发现,其生产线上的传感器数据中,有32%存在时间戳错乱、数值异常或缺失的问题,某台机械臂的关节角度传感器在连续10分钟内记录了相同的数值,实际却是传感器故障导致的“死值”;另一台设备的温度数据突然从50℃跳到-20℃,明显是通信干扰导致的异常值。
数据挖掘知识点1:异常值检测与修复
该厂商采用“3σ原则”结合滑动窗口算法,对时间序列数据进行异常检测,对于温度、压力等连续变量,计算滑动窗口内数据的均值和标准差,超出3倍标准差的值被标记为异常;对于离散变量(如设备状态码),则通过频率统计识别低频异常值,修复时,对短期缺失采用线性插值,对长期缺失则用历史同期数据填充,数据可用率从68%提升至92%,为后续建模提供了可靠基础。
多源数据融合:打破“数据孤岛”的壁垒
工业场景中,数据往往分散在PLC、SCADA、MES等多个系统,格式、频率和语义各不相同,2026年,某钢铁企业试图构建高炉数字孪生体,但发现其数据源包括:DCS系统(每秒1次的高炉温度)、振动传感器(每分钟100次的设备振动数据)、以及人工记录的原料配比(每天1次),不同频率、不同精度的数据如何融合?
数据挖掘知识点2:数据对齐与降采样
该企业采用“时间桶”方法,将所有数据按分钟级时间桶对齐,对于高频数据(如振动),计算每分钟内的均值、最大值、最小值等统计特征;对于低频数据(如原料配比),则直接填充到对应时间桶,通过语义映射解决不同系统对同一指标的定义差异(如“高炉温度”在DCS中用摄氏度,在人工记录中用华氏度),融合后的数据集包含200+维度,覆盖了高炉运行的90%关键参数。
特征工程:从“原始数据”到“有效特征”的提炼
本月机器人技术与健康中国及算法推荐热度持续上升,相关产业迎来新机遇 数字孪生的模型性能,70%取决于特征工程的质量,2026年,某风电企业为优化风机叶片的疲劳寿命预测,收集了包括风速、风向、转速、温度在内的100+原始特征,但直接建模效果不佳。

数据挖掘知识点3:特征衍生与选择
该企业通过领域知识衍生新特征:将风速与风向结合计算“等效风速”(考虑风向对叶片受力的影响);将转速与温度结合计算“热应力指数”(反映材料疲劳的关键指标),采用“互信息法”筛选特征,去除与目标变量(叶片寿命)相关性低于0.1的特征,模型输入特征从100+降至20+,预测准确率提升15%。
时序模式挖掘:捕捉设备运行的“隐藏节奏”
工业设备的运行数据具有强时序性,隐藏着设备健康状态的周期性规律,2026年,某化工企业通过数字孪生监测反应釜温度,发现其数据存在明显的“日周期”和“周周期”模式:每天凌晨3点温度最低(因夜间负荷降低),每周一温度波动最大(因周末停机后重启)。
数据挖掘知识点4:周期性检测与分解
该企业采用“傅里叶变换”将时序数据分解为不同频率的成分,识别出主要的周期(24小时、168小时),用“STL分解”(季节-趋势-残差分解)将数据拆分为季节项(周期性变化)、趋势项(长期变化)和残差项(随机波动),通过监控残差项的异常,提前3天预测了反应釜密封泄漏故障,避免了一次非计划停机。
关联规则挖掘:发现“数据背后的因果链”
2026年机构养老与可持续时尚及医疗器械热度持续上升,相关产业迎来新机遇 工业场景中,单个指标的异常往往与其他指标相关,2026年,某半导体厂商在数字孪生中发现,某台光刻机的“曝光能量”偶尔会偏离设定值,但单独分析能量数据无法找到原因,通过关联规则挖掘,发现当“环境湿度>60%”且“设备温度<25℃”时,曝光能量偏离的概率提升80%。

数据挖掘知识点5:Apriori算法与支持度-置信度框架
该厂商采用Apriori算法,设置最小支持度为5%(即某组合在所有数据中出现的比例)、最小置信度为70%(即某条件出现时,目标事件出现的概率),最终挖掘出20+条关联规则,包括“湿度>60% & 温度<25℃ → 能量偏离”“设备振动>5g → 定位误差增加”等,这些规则被嵌入数字孪生的预警系统,使故障识别时间缩短60%。
聚类分析:给设备“分群”实现精准管理
同一类型的设备,运行状态可能因使用年限、维护水平不同而差异巨大,2026年,某电梯企业为优化维护策略,对全国5万台电梯的振动数据进行聚类分析。
数据挖掘知识点6:K-means++与轮廓系数
该企业采用K-means++算法(改进的K-means,避免初始中心点随机性),结合轮廓系数(评估聚类效果的指标,值越接近1表示聚类越合理)确定最佳聚类数,最终将电梯分为3类:A类(新电梯,振动小)、B类(中年电梯,振动中等)、C类(老旧电梯,振动大),针对不同类别,制定差异化维护计划:A类每年检修1次,B类每半年1次,C类每季度1次,使整体故障率下降40%。
预测模型:从“事后处理”到“事前预防”
数字孪生的核心价值之一是预测性维护,2026年,某航空发动机厂商通过数字孪生预测涡轮叶片的剩余寿命,采用LSTM(长短期记忆网络)模型处理时序数据。

数据挖掘知识点7:LSTM与注意力机制
该厂商的LSTM模型输入为叶片的振动、温度、压力等时序数据,输出为剩余寿命预测值,为提升模型对关键时间点的关注,引入注意力机制,自动学习不同时间步的权重,在叶片裂纹扩展阶段,模型会赋予近期数据更高权重,模型预测误差从15%降至5%,支持发动机“视情维护”策略,减少非计划拆解成本3000万元/年。
仿真优化:在虚拟世界中“试错”
数字孪生不仅用于监测,还可通过仿真优化生产参数,2026年,某食品企业为优化烘焙生产线,在数字孪生体中模拟不同温度、湿度、时间组合对面包品质的影响。
数据挖掘知识点8:蒙特卡洛模拟与响应面法
该企业采用蒙特卡洛模拟生成1000组随机参数组合,在数字孪生体中运行仿真,记录每组参数下的面包水分、硬度、色泽等指标,用响应面法建立参数与指标之间的数学模型,通过梯度下降法寻找最优参数组合,确定“温度185℃、湿度65%、时间12分钟”为最佳工艺,使面包合格率从82%提升至95%。
实时决策:让数字孪生“动起来”
数字孪生的最高阶段是实现实时决策,2026年,某智能电网企业构建变电站数字孪生体,通过边缘计算实时分析电流、电压、温度等数据,自动调整无功补偿装置的投切。 2026年生态补偿与碳封存及绿色电力热度持续上升,相关产业迎来新机遇
数据挖掘知识点9:流式计算与规则引擎
该企业采用Apache Flink进行流式计算,对每秒10万条的传感器数据进行实时处理,当检测到“某相电压偏差>5%”且“无功功率<设定值