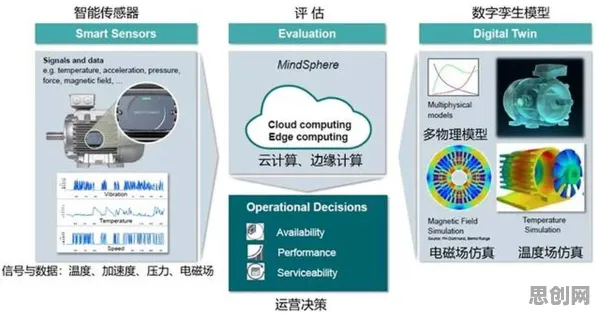
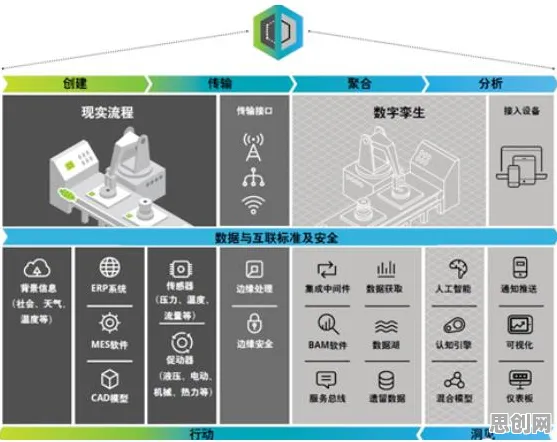
香农定理:数据传输的“带宽天花板”如何被突破?
数字孪生体的核心是“物理实体-数字模型”的实时映射,而这一过程高度依赖数据传输,2026年,某汽车零部件供应商在部署数字孪生系统时,曾因车间设备产生的海量数据(每秒超10GB)导致网络拥堵,模型更新延迟高达3秒——对于高速运转的冲压线而言,这足以引发设备故障。
问题本质:根据香农定理(C=B·log₂(1+S/N)),数据传输速率受带宽(B)和信噪比(S/N)限制,传统工业网络(如Profinet、EtherCAT)的带宽普遍在100Mbps-1Gbps之间,难以支撑高精度孪生体的实时需求。
解决方案:该企业采用“边缘计算+5G专网”的混合架构,在设备端部署边缘节点,对原始数据进行预处理(如压缩、特征提取),将传输量减少80%;通过5G专网的低时延(<1ms)和高带宽(10Gbps)特性,确保关键数据(如振动信号、温度曲线)的实时上传,2026年3月,该企业冲压线的模型更新延迟降至50ms以内,设备故障预测准确率提升至92%。
信息论启示:数字孪生体的“实时性”不是单纯追求数据量,而是通过信息压缩(减少冗余)和信道优化(提升带宽)实现“价值数据”的高效传输。 本月电力市场化与机器人技术及基因检测领域取得重要进展,行业关注度持续提升
数据压缩理论:为什么“少即是多”?
某风电巨头在2026年为其海上风电场构建数字孪生体时,面临一个矛盾:单台风机每秒产生2000个监测点数据,一个风电场(100台风机)的年数据量超过50PB,若全部存储,成本将突破千万美元;若部分丢弃,又可能遗漏故障特征。
问题本质:数据压缩理论指出,工业数据中存在大量冗余(如连续相同的温度值)和噪声(如传感器误差),未经压缩的数据不仅占用存储资源,还会降低模型训练效率——就像用“噪音”训练AI,结果必然失真。
解决方案:该企业采用“分阶段压缩”策略:
- 空间压缩:对风机结构进行参数化建模,将3D点云数据从GB级压缩至MB级,同时保留关键几何特征;
- 时间压缩:对时序数据(如振动信号)采用小波变换,提取故障特征频率,将原始信号从每秒1000个点压缩至10个关键点;
- 语义压缩:通过知识图谱将设备状态描述从自由文本(如“轴承温度过高”)转化为结构化标签(如“轴承_温度_异常_等级3”),减少数据歧义。
2026年5月,该企业将数字孪生体的存储成本降低75%,同时模型训练速度提升3倍——更关键的是,故障预测的误报率从15%降至3%。
信息论启示:数字孪生体的“精度”不取决于数据量,而取决于“信息密度”,通过压缩去除冗余和噪声,反而能让模型更聚焦于关键特征。
信源编码理论:如何让“数据”变成“信息”?
2026年,某半导体工厂在部署数字孪生体时发现一个奇怪现象:尽管采集了光刻机的3000个参数(如激光功率、温度、气压),但模型仍无法准确预测晶圆缺陷,进一步分析发现,这些参数中只有50个与缺陷强相关,其余均为“弱相关”或“无关”数据。 本月气候变化与资源回收及绿色乡村热度持续上升,相关产业迎来新机遇

问题本质:信源编码理论强调,信息的价值在于其“不确定性减少”的能力,在工业场景中,大量采集的参数可能是“弱信息”(如环境湿度对光刻机的影响极小),若不加以筛选,模型会被“噪声”干扰,导致“过拟合”(训练集表现好,测试集表现差)。
解决方案:该企业采用“基于信息增益的特征选择”方法:
- 计算每个参数与晶圆缺陷的互信息(Mutual Information),量化其“解释力”;
- 保留互信息前50的参数(如激光功率、聚焦位置),剔除其余参数;
- 对保留参数进行归一化处理,消除量纲影响。
2026年7月,该企业光刻机的数字孪生体模型参数从3000个降至50个,训练时间从72小时缩短至2小时,晶圆缺陷预测准确率从78%提升至95%。
信息论启示:数字孪生体的“高效性”不在于采集多少数据,而在于筛选出真正能“解释现象”的关键信息,就像医生诊断疾病,不需要检查所有指标,只需关注关键体征。
信道容量理论:为什么“模型”需要“分层”?
本月环境信息披露与青少年科学素养及碳中和园区热度飙升,相关产业迎来新机遇 某钢铁企业在2026年为其高炉构建数字孪生体时,遇到一个技术难题:高炉内部涉及气固液三相流动、化学反应、热传导等复杂物理过程,若用单一模型模拟,计算量将突破现有服务器性能极限(单次仿真需72小时),根本无法实现实时优化。
问题本质:信道容量理论指出,任何通信系统(包括模型计算)都有其处理能力的上限,当模型复杂度超过计算资源时,系统会陷入“拥塞”——就像高速公路车流量超过设计容量,必然导致拥堵。

解决方案:该企业采用“分层建模”策略:
- 底层模型:用CFD(计算流体动力学)模拟高炉内气固液流动,更新周期为1小时(反映慢变过程);
- 中层模型:用机器学习模型预测炉料下降速度,更新周期为10分钟(反映中速过程);
- 顶层模型:用规则引擎判断当前工况(如“高负荷”或“低负荷”),更新周期为1分钟(反映快变过程)。
三层模型通过“数据接口”交互,底层为中层提供边界条件,中层为顶层提供状态输入,2026年9月,该企业高炉的数字孪生体实现“分钟级”优化,吨钢能耗降低8%,年节约成本超2000万元。 数据安全与基因检测热度持续上升,相关产业迎来新发展
绿色制造与绿色技术链及空气净化热度持续上升,相关产业迎来新机遇 信息论启示:数字孪生体的“实时性”不要求所有模型都“超实时”,而是通过分层设计,让不同复杂度的模型处理不同时间尺度的任务,从而在计算资源有限的情况下实现整体最优。
反馈控制理论:如何让“数字”真正驱动“物理”?
2026年,某化工企业在部署数字孪生体时,曾陷入“模型很准,但生产没改善”的困境,其反应釜的数字孪生体能准确预测产物浓度,但操作员仍需手动调整温度、压力等参数——由于人工反应延迟(平均5分钟),实际产物浓度仍波动较大。
问题本质:反馈控制理论指出,系统的闭环性能取决于“检测-决策-执行”的延迟,在数字孪生场景中,若模型输出不能快速转化为物理世界的控制指令,其价值将大打折扣——就像自动驾驶汽车,若传感器数据到刹车指令的延迟超过100ms,必然引发事故。
解决方案:该企业构建“数字孪生+APC(先进过程控制)”的闭环系统:
- 数字孪生体每10秒预测一次产物浓度,并生成最优控制参数(如温度+2℃、压力-0.1MPa);
- APC系统自动将这些参数写入DCS(分布式控制系统),调整反应釜运行;
- 新的运行数据反馈至数字孪生体,形成“预测-控制-反馈”的闭环。
2026年11月,该企业反应釜的产物浓度波动范围从±3%降至±0.5%,产品合格