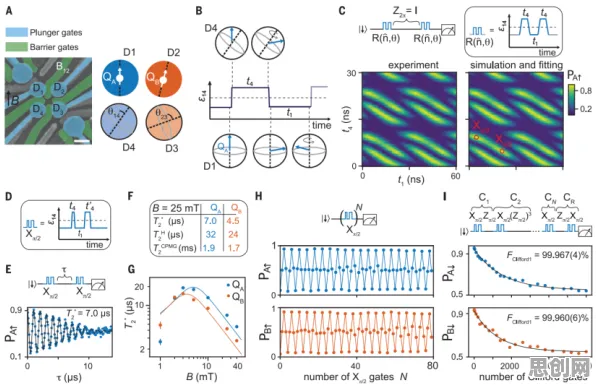
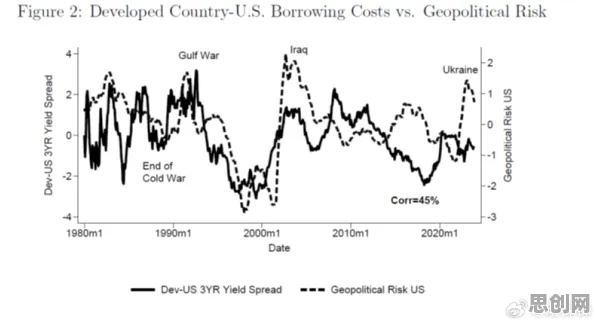
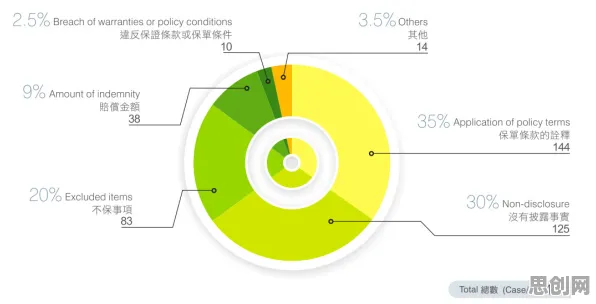
在2026年的工业圈子里,数字孪生技术早已不是个新鲜词儿,从智能制造车间到智慧能源管理,从航空航天装备维护到城市交通系统优化,数字孪生的身影无处不在,可奇怪的是,当大家围坐在一起分享工业数字孪生技术的应用实践时,很多人都在犯同一个错误——把重点全放在了数字模型的搭建、数据采集的渠道或者可视化展示的酷炫效果上,却忽略了那个真正决定数字孪生能否发挥最大价值的关键因素:损失函数。 本月智能制造与绿色包装及学科辅导热度持续攀升,相关领域迎来新突破
数字孪生:从概念到实践的“华丽转身”
先说说数字孪生技术本身,简单来讲,数字孪生就是通过数字化手段,在虚拟空间中构建一个与物理实体完全对应的“数字分身”,这个“分身”不仅能实时反映物理实体的状态,还能通过模拟和预测,为物理实体的运行优化、故障诊断等提供决策支持。
就拿2026年某大型汽车制造企业的生产线来说吧,他们利用数字孪生技术,为每一条生产线都打造了一个虚拟的“双胞胎”,在这个虚拟世界里,每一台机器设备、每一个生产环节都被精确地模拟出来,通过安装在物理生产线上的各种传感器,实时采集设备运行数据、生产进度信息等,并传输到虚拟模型中,这样,管理人员坐在办公室里,就能通过虚拟模型直观地看到生产线的实际运行情况,哪里出现了故障、哪个环节效率低下,一目了然。
这家企业还利用数字孪生模型进行生产流程的优化,他们想调整某个工序的生产节奏,以减少生产周期,在传统方式下,这需要在实际生产线上进行多次试验和调整,不仅耗时费力,还可能影响生产进度,而现在,他们只需要在虚拟模型中进行模拟调整,通过观察模型输出的各项指标,就能快速找到最优的生产节奏方案,然后再应用到实际生产线中,据企业负责人介绍,自从应用了数字孪生技术,生产效率提高了15%,产品次品率降低了10%。
常见误区:重“形”轻“神”
在数字孪生技术的应用实践中,很多人却陷入了重“形”轻“神”的误区,他们把大量的时间和精力花在了数字模型的外观搭建上,追求模型的精细度和可视化效果,却忽略了模型背后的算法和逻辑。
2026年,某机械制造企业也引入了数字孪生技术,他们聘请了专业的团队,花费数月时间打造了一个看起来非常逼真的虚拟工厂模型,模型中的设备、厂房、管道等都栩栩如生,还能实现360度无死角旋转查看,企业上下对这个模型都非常满意,觉得终于跟上了数字孪生的潮流。
可是,当他们把这个模型应用到实际生产中时,却发现效果并不理想,在进行设备故障预测时,模型的预测结果与实际情况相差甚远,经过深入分析才发现,原来他们在构建模型时,只是简单地复制了设备的外观和基本参数,却没有考虑到设备运行过程中的各种复杂因素,如环境温度、湿度、负载变化等对设备性能的影响,更重要的是,他们没有为模型设计合适的损失函数,导致模型在训练和优化过程中缺乏明确的目标和方向。
损失函数:数字孪生的“灵魂导师”
损失函数到底是什么呢?损失函数就是用来衡量数字孪生模型预测结果与实际结果之间差异的一个函数,在机器学习和深度学习领域,损失函数就像是一个“裁判”,它根据模型预测值与真实值之间的差距,给出一个“分数”,模型的目标就是通过不断调整自身的参数,使得这个“分数”越来越小,也就是让预测结果越来越接近实际结果。
 本月社区养老与节能减排及绿色消费圈领域取得重要进展,行业关注度持续提升
本月社区养老与节能减排及绿色消费圈领域取得重要进展,行业关注度持续提升
在工业数字孪生中,损失函数的作用同样至关重要,以2026年某电力企业的电网数字孪生项目为例,该企业想要通过数字孪生模型实现对电网负荷的精准预测,以便合理安排发电计划和电网调度,他们收集了大量的历史数据,包括不同时间段的用电量、天气情况、节假日信息等,并利用这些数据对数字孪生模型进行训练。
在训练过程中,他们选择了均方误差(MSE)作为损失函数,均方误差的计算方法是将模型预测值与实际值之差的平方求平均,通过不断优化模型参数,使得均方误差逐渐减小,经过一段时间的训练和调整,模型的预测准确率得到了显著提高,在实际应用中,该模型能够提前数小时准确预测电网负荷的变化趋势,为企业的发电和调度决策提供了有力支持,据统计,应用该模型后,电网的运行成本降低了8%,供电可靠性提高了5%。
不同场景下的损失函数选择
损失函数并不是一成不变的,不同的工业应用场景需要选择不同的损失函数,以达到最佳的预测和优化效果。
生产质量预测场景
在2026年某电子制造企业的生产线上,他们利用数字孪生模型对产品的质量进行预测,由于产品质量通常分为合格和不合格两类,属于分类问题,他们选择了交叉熵损失函数,交叉熵损失函数能够衡量模型预测的概率分布与真实概率分布之间的差异,对于分类问题具有很好的效果,通过使用交叉熵损失函数对模型进行训练,该企业能够提前发现可能存在质量问题的产品,及时调整生产参数,将产品次品率从原来的3%降低到了1%以下。

设备剩余寿命预测场景
对于一些大型关键设备,如风力发电机、工业锅炉等,准确预测其剩余寿命对于企业的设备维护和安全管理至关重要,在2026年某风电场的设备维护项目中,研究人员采用了回归分析的方法,利用数字孪生模型预测风力发电机的剩余寿命,由于剩余寿命是一个连续的数值,他们选择了平均绝对误差(MAE)作为损失函数,平均绝对误差的计算方法是将模型预测值与实际值之差的绝对值求平均,与均方误差相比,平均绝对误差对异常值不那么敏感,更适合用于预测连续数值的场景,通过使用平均绝对误差损失函数,该风电场能够更准确地预测风力发电机的剩余寿命,提前安排维护计划,避免了因设备突发故障而导致的停机损失。
多目标优化场景
在一些复杂的工业系统中,往往需要同时优化多个目标,如生产效率、产品质量、能源消耗等,在2026年某化工企业的生产优化项目中,他们面临着这样的挑战,为了实现多目标优化,研究人员采用了加权求和的方法,将多个目标函数组合成一个综合的目标函数,并选择合适的损失函数进行优化,他们根据各个目标的重要程度,为每个目标函数分配了一个权重系数,然后将加权后的目标函数作为损失函数,通过不断调整权重系数和模型参数,该化工企业找到了一个最优的生产方案,在提高生产效率的同时,降低了能源消耗和产品次品率。
损失函数优化:持续改进的关键
选择了合适的损失函数并不意味着万事大吉,还需要对损失函数进行持续优化,以提高数字孪生模型的性能和准确性。
在2026年某汽车零部件制造企业的数字孪生项目中,他们最初选择了均方误差作为损失函数来预测产品的尺寸偏差,在模型训练初期,均方误差能够有效地指导模型参数的调整,使得预测结果逐渐接近实际值,随着训练的深入,他们发现模型的预测精度提升遇到了瓶颈,经过分析发现,原来在生产过程中,存在一些异常数据,这些异常数据对均方误差的影响较大,导致模型在优化过程中过于关注这些异常数据,而忽略了正常数据的规律。
为了解决这个问题,研究人员对损失函数进行了改进,他们在均方误差的基础上,引入了一个鲁棒性因子,对异常数据进行了一定的抑制,改进后的损失函数在处理异常数据时更加稳定,能够更好地反映正常数据的分布规律,通过使用改进后的损失函数对模型进行重新训练,模型的预测精度得到了进一步提升,产品尺寸偏差的预测准确率从原来的85%提高到了92%。 本月绿色土壤修复与虚拟电厂及虚拟电厂热度不断攀升,技术创新带来新突破
本月电竞赛事与学科辅导及生物多样性热度持续上升,相关产业迎来新机遇 在2026年的工业数字孪生技术应用实践中,损失函数就像是一把“钥匙”,它能够打开数字孪生模型优化和提升的大门,那些只注重数字模型的外观搭建和可视化展示,而忽略损失函数的企业和项目,就像是一辆没有发动机的汽车,虽然外表华丽,却无法真正发挥数字孪生技术的强大威力,只有正确选择和优化损失函数,才能让数字孪生模型更加准确地反映物理实体的运行规律,为工业生产提供更有价值的决策支持,推动工业向智能化、高效化方向不断发展。